") 一文詳解知識(shí)增強(qiáng)的語(yǔ)言預(yù)訓(xùn)練模型
一文詳解知識(shí)增強(qiáng)的語(yǔ)言預(yù)訓(xùn)練模型
來(lái)自:復(fù)旦DISC
作者:王思遠(yuǎn)
引言
隨著預(yù)訓(xùn)練語(yǔ)言模型(PLMs)的不斷發(fā)展,各種NLP任務(wù)設(shè)置上都取得了不俗的性能。盡管PLMs可以從大量語(yǔ)料庫(kù)中學(xué)習(xí)一定的知識(shí),但仍舊存在很多問(wèn)題,如知識(shí)量有限、受訓(xùn)練數(shù)據(jù)長(zhǎng)尾分布影響魯棒性不好等,在實(shí)際應(yīng)用場(chǎng)景中效果不好。為了解決這個(gè)問(wèn)題,將知識(shí)注入到PLMs中已經(jīng)成為一個(gè)非常活躍的研究領(lǐng)域。本次分享將介紹三篇知識(shí)增強(qiáng)的預(yù)訓(xùn)練語(yǔ)言模型論文,分別通過(guò)基于知識(shí)向量、知識(shí)檢索以及知識(shí)監(jiān)督的知識(shí)注入方法來(lái)增強(qiáng)語(yǔ)言預(yù)訓(xùn)練模型。
文章概覽
KLMo:建模細(xì)粒度關(guān)系的知識(shí)圖增強(qiáng)預(yù)訓(xùn)練語(yǔ)言模型(KLMo: Knowledge Graph Enhanced Pretrained Language Model with Fine-Grained Relationships)
這篇文章提出同時(shí)將KG中的實(shí)體以及實(shí)體間的關(guān)系結(jié)合到語(yǔ)言學(xué)習(xí)過(guò)程中,來(lái)得到一個(gè)知識(shí)增強(qiáng)預(yù)訓(xùn)練模型。通過(guò)一個(gè)知識(shí)聚合器對(duì)文本中的實(shí)體片段和KG中的實(shí)體、關(guān)系向量之間的交互建模,從而將KG中的實(shí)體和關(guān)系向量融入語(yǔ)言模型中,還提出了關(guān)系預(yù)測(cè)和實(shí)體鏈接的預(yù)訓(xùn)練任務(wù)來(lái)整合KG中關(guān)系和實(shí)體信息。
用于知識(shí)增強(qiáng)語(yǔ)言模型預(yù)訓(xùn)練的基于知識(shí)圖合成語(yǔ)料庫(kù)生成(Knowledge Graph Based Synthetic Corpus Generation for Knowledge-Enhanced Language Model Pre-training)
檢索型語(yǔ)言模型通過(guò)從外部文本知識(shí)語(yǔ)料集中檢索知識(shí)增強(qiáng)模型,本文為了整合結(jié)構(gòu)化知識(shí)和自然語(yǔ)言數(shù)據(jù),提出了將知識(shí)圖譜轉(zhuǎn)換為自然文本,來(lái)為檢索型語(yǔ)言模型擴(kuò)充檢索知識(shí)語(yǔ)料庫(kù),從而使得結(jié)構(gòu)化知識(shí)無(wú)縫地集成到現(xiàn)有的預(yù)訓(xùn)練語(yǔ)言模型中。
ERICA:通過(guò)對(duì)比學(xué)習(xí)提高預(yù)訓(xùn)練語(yǔ)言模型對(duì)實(shí)體和關(guān)系的理解(ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning)
這篇文章提出對(duì)文本中的關(guān)系事實(shí)進(jìn)行建模來(lái)增強(qiáng)語(yǔ)言模型,具體地設(shè)計(jì)了實(shí)體判別和關(guān)系判別兩個(gè)預(yù)訓(xùn)練任務(wù)來(lái)以知識(shí)監(jiān)督的方式加深對(duì)實(shí)體和關(guān)系的理解,并通過(guò)對(duì)比學(xué)習(xí)的框架實(shí)現(xiàn)。
論文細(xì)節(jié)
1論文動(dòng)機(jī)
本文類似ERNIE-THU[1],通過(guò)引入知識(shí)向量增強(qiáng)預(yù)訓(xùn)練語(yǔ)言模型,然而以前的知識(shí)增強(qiáng)模型只利用實(shí)體信息,而忽略了實(shí)體之間的細(xì)粒度關(guān)系。而實(shí)體間的關(guān)系對(duì)于語(yǔ)言表示學(xué)習(xí)也至關(guān)重要,如圖KG中的關(guān)系信息影響了實(shí)體Trio of Happiness的類別預(yù)測(cè)。
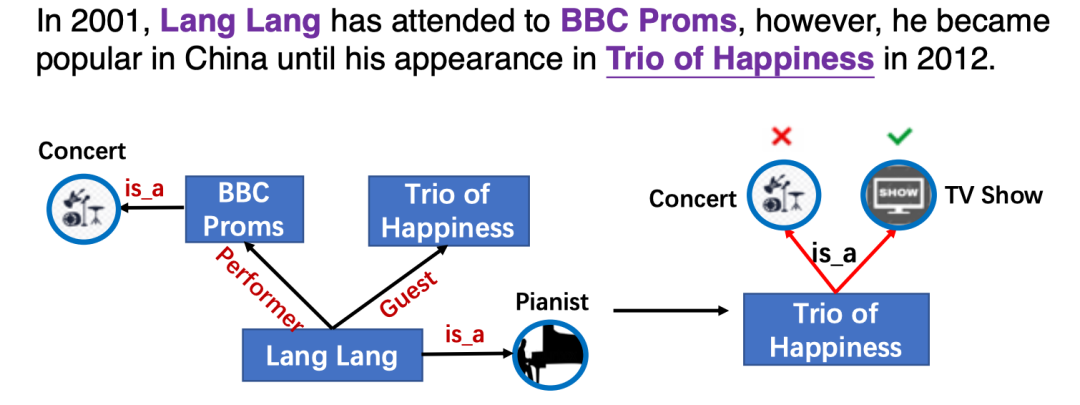
將KG中的實(shí)體和關(guān)系明確地整合到PLMs中的主要挑戰(zhàn)是文本知識(shí)(實(shí)體和關(guān)系)對(duì)齊(TKA)問(wèn)題,為了解決這個(gè)問(wèn)題,文章提出了一個(gè)知識(shí)增強(qiáng)預(yù)訓(xùn)練語(yǔ)言模型(KLMo),通過(guò)一個(gè)知識(shí)聚合器對(duì)文本中的實(shí)體片段和KG中的實(shí)體、關(guān)系向量之間的交互建模,使得文本中token關(guān)注到高度相關(guān)的KG實(shí)體和關(guān)系。文章還提出了關(guān)系預(yù)測(cè)和實(shí)體鏈接的兩個(gè)預(yù)訓(xùn)練任務(wù),來(lái)整合KG中關(guān)系和實(shí)體信息,從而實(shí)現(xiàn)將KG中的實(shí)體和關(guān)系信息融入語(yǔ)言模型中。
模型
KLMo模型如下圖,結(jié)構(gòu)上類似ERNIE-THU,文本序列首先經(jīng)過(guò)一個(gè)文本編碼器,然后會(huì)被輸入到知識(shí)聚合器中來(lái)將實(shí)體和關(guān)系的知識(shí)向量融入到文本序列中,最后通過(guò)優(yōu)化關(guān)系預(yù)測(cè)和實(shí)體鏈接兩個(gè)預(yù)訓(xùn)練目標(biāo),從而將KG中高度相關(guān)的實(shí)體和關(guān)系信息合并到文本表示中。
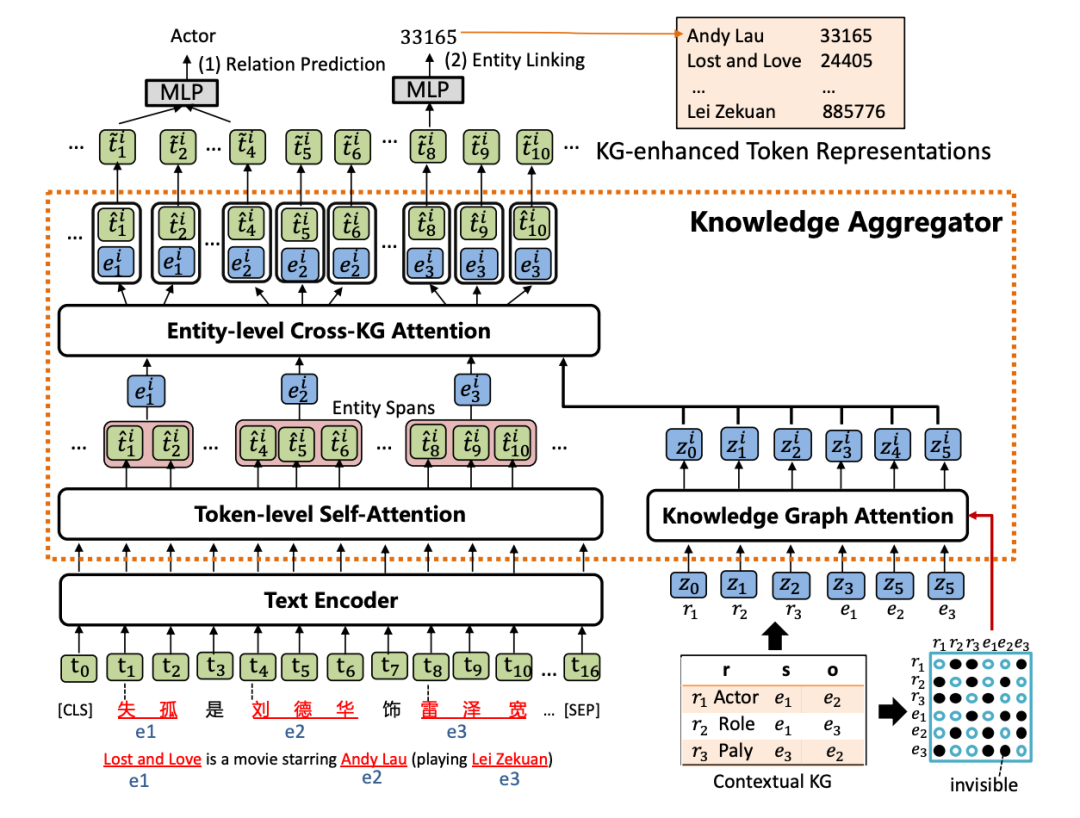
1. 知識(shí)聚合器
知識(shí)聚合器包含兩個(gè)獨(dú)立的注意力機(jī)制:token級(jí)別自注意力和知識(shí)圖譜注意力,分別對(duì)輸入文本和KG進(jìn)行編碼,聚合器通過(guò)實(shí)體級(jí)別的交叉KG注意力,對(duì)文本中的實(shí)體片段與KG中的實(shí)體和關(guān)系之間的交互進(jìn)行建模,以將知識(shí)融入文本表示。
(1) 知識(shí)圖譜注意力機(jī)制
首先通過(guò)TransE得到KG中的實(shí)體和關(guān)系表示,并將其轉(zhuǎn)成一條實(shí)體和關(guān)系向量序列,作為聚合器的輸入。然后采用一個(gè)知識(shí)圖譜注意力機(jī)制,通過(guò)在傳統(tǒng)注意力機(jī)制中引入一個(gè)可視矩陣,從而在知識(shí)表示學(xué)習(xí)過(guò)程中考慮圖結(jié)構(gòu),該矩陣只允許相鄰節(jié)點(diǎn)和關(guān)系可以關(guān)注到彼此。
(2) 實(shí)體級(jí)別交叉KG注意力機(jī)制
給定一個(gè)實(shí)體提及列表,通過(guò)在文本中實(shí)體范圍內(nèi)的所有tokens上pooling計(jì)算得到文本中實(shí)體片段表示,然后將文本中的實(shí)體片段表示作為query,將KG中的實(shí)體和關(guān)系表示作為key和value,進(jìn)行注意力計(jì)算,從而得到知識(shí)增強(qiáng)的實(shí)體表示。
(3) 知識(shí)增強(qiáng)的文本表示
為了將知識(shí)增強(qiáng)的實(shí)體表示注入到文本表示中,文章采用一個(gè)知識(shí)融入操作,公式如下,得到的知識(shí)增強(qiáng)文本表示將會(huì)被傳入下一層知識(shí)聚合器中。
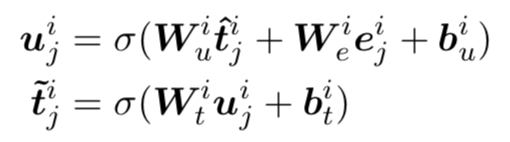
2. 預(yù)訓(xùn)練目標(biāo)
為了將知識(shí)融入到語(yǔ)言預(yù)訓(xùn)練中,KLMo采取了一個(gè)多任務(wù)損失函數(shù),除了傳統(tǒng)的masked language model損失,還引入了一個(gè)關(guān)系預(yù)測(cè)以及實(shí)體鏈接的損失函數(shù)。
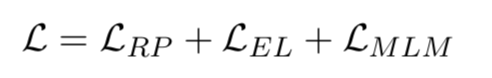
實(shí)驗(yàn)
模型在百度百科網(wǎng)頁(yè)數(shù)據(jù)以及百科知識(shí)圖譜上進(jìn)行預(yù)訓(xùn)練,并在兩個(gè)分別用于實(shí)體分類以及關(guān)系分類的中文數(shù)據(jù)集上進(jìn)行了比較和評(píng)估,結(jié)果顯示實(shí)體之間的細(xì)粒度關(guān)系信息有助于KLMo更準(zhǔn)確地預(yù)測(cè)實(shí)體和關(guān)系的類別。
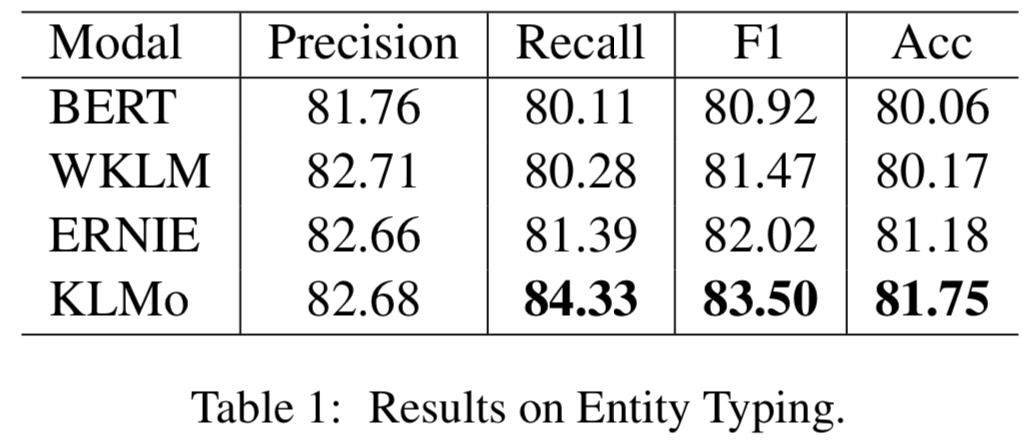
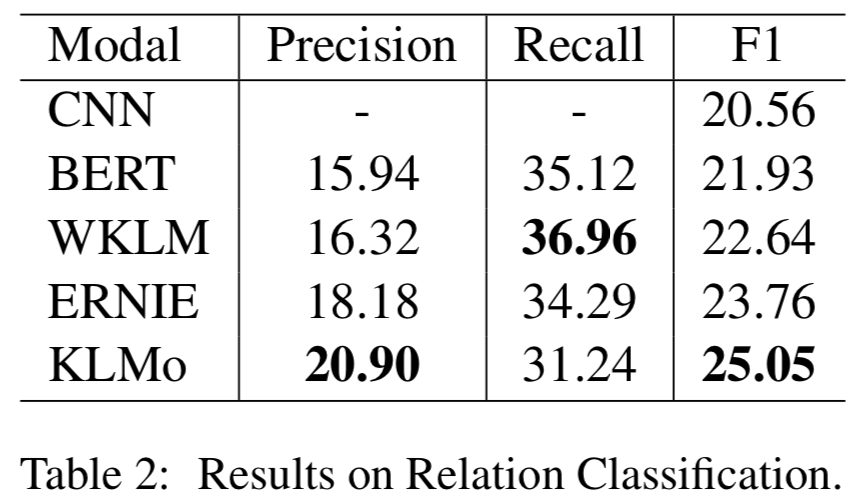
同時(shí)文章還在實(shí)體分類上對(duì)KLMo中實(shí)體和關(guān)系知識(shí)進(jìn)行了消融實(shí)驗(yàn),結(jié)果如下可以看出通過(guò)預(yù)訓(xùn)練,知識(shí)信息已經(jīng)被融入KLMo中。
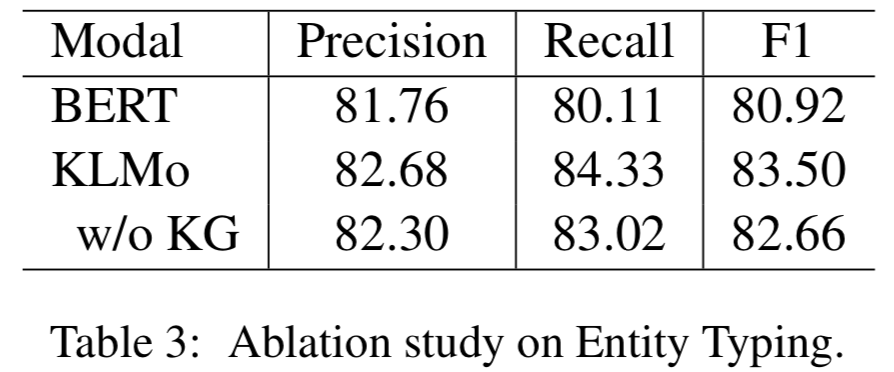
2

論文動(dòng)機(jī)
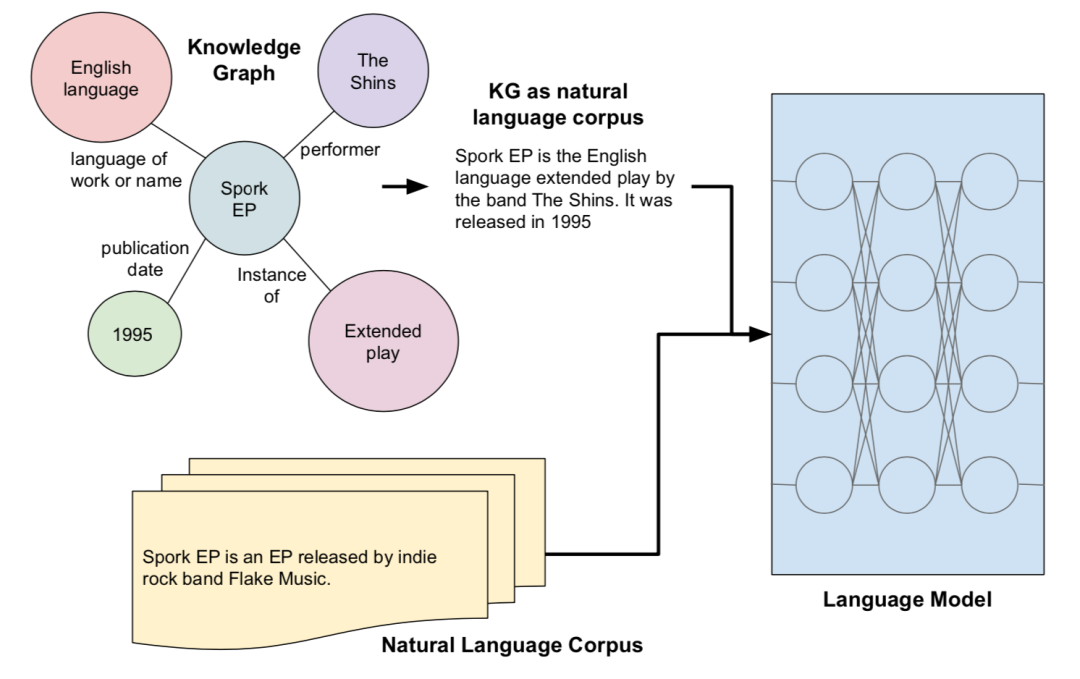
本文基于檢索型預(yù)訓(xùn)練語(yǔ)言模型,通過(guò)從外部知識(shí)語(yǔ)料集檢索知識(shí)來(lái)增強(qiáng)語(yǔ)言模型,然而以前都是從文本語(yǔ)料集中檢索知識(shí),只能覆蓋有限的世界知識(shí)而忽略了結(jié)構(gòu)化知識(shí),并且知識(shí)在文本中的表達(dá)沒(méi)有在KG中那么明確,文本質(zhì)量的變化也會(huì)導(dǎo)致結(jié)果模型中的偏差。為了將結(jié)構(gòu)化知識(shí)整合到語(yǔ)言模型中,文章將結(jié)構(gòu)化知識(shí)圖譜轉(zhuǎn)換為自然文本,來(lái)為檢索型語(yǔ)言模型REALM[2]擴(kuò)充檢索知識(shí)語(yǔ)料庫(kù)KELM,從而使得結(jié)構(gòu)化知識(shí)無(wú)縫地集成到現(xiàn)有的預(yù)訓(xùn)練語(yǔ)言模型中。
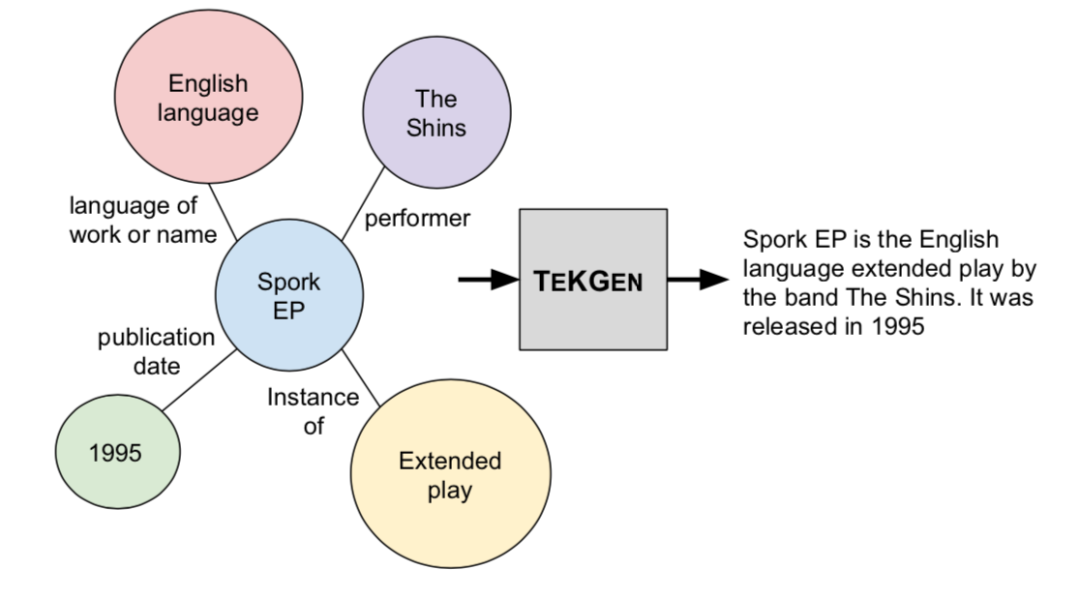
本文提出將英文維基百科知識(shí)圖譜轉(zhuǎn)化成自然語(yǔ)言文本,如上圖,并構(gòu)建了一個(gè)英文Wikidata KG-Wikipedia Text的對(duì)齊數(shù)據(jù)集來(lái)訓(xùn)練文本化模型,從而生成了KELM數(shù)據(jù)集,擴(kuò)充REALM的檢索知識(shí)語(yǔ)料庫(kù)。
模型
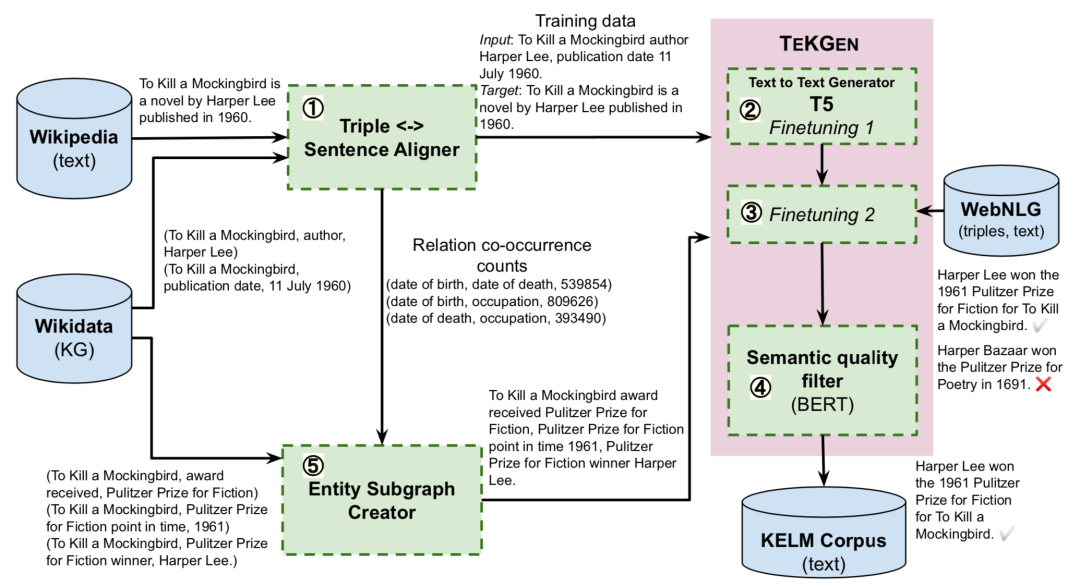
1. 基于KG的文本生成器TEKGEN
文章首先提出了一個(gè)端到端的基于KG的文本化模型TEKGEN,具體流程如上圖:首先使用遠(yuǎn)程監(jiān)督來(lái)對(duì)齊維基百科文本和KG三元組;隨后T5模型按順序首先在這個(gè)語(yǔ)料庫(kù)上進(jìn)行微調(diào)來(lái)提升實(shí)體和關(guān)系覆蓋率,隨后在標(biāo)準(zhǔn)WebNLG語(yǔ)料庫(kù)上進(jìn)行少量步驟的訓(xùn)練來(lái)減少錯(cuò)誤;最后通過(guò)對(duì)BERT微調(diào)構(gòu)建一個(gè)過(guò)濾器,為生成文本針對(duì)三元組的語(yǔ)義質(zhì)量打分。
2. 合成知識(shí)檢索數(shù)據(jù)集KELM Corpus
這一步利用TEKGEN模型和過(guò)濾器來(lái)構(gòu)建一個(gè)合成語(yǔ)料庫(kù)KELM,以自然語(yǔ)言的格式捕獲KG知識(shí)。首先使用前面構(gòu)造的英文Wikidata KG-Wikipedia Text的對(duì)齊數(shù)據(jù)集的關(guān)系對(duì)創(chuàng)建實(shí)體子圖,隨后子圖中的知識(shí)三元組通過(guò)TEKGEN模型轉(zhuǎn)化為自然語(yǔ)言文本,從而構(gòu)建KELM數(shù)據(jù)集。
3.知識(shí)增強(qiáng)語(yǔ)言模型
文章將生成的KELM語(yǔ)料庫(kù)作為將KGs集成到預(yù)訓(xùn)練語(yǔ)言模型,如下圖所示,采用了基于檢索的預(yù)訓(xùn)練語(yǔ)言模型REALM,預(yù)訓(xùn)練過(guò)程中,除了掩碼句還會(huì)從檢索語(yǔ)料集中抽取一個(gè)文本作為輔助知識(shí)用來(lái)聯(lián)合預(yù)測(cè)掩蓋的單詞,而KELM則被用來(lái)替換/擴(kuò)充REALM中的檢索語(yǔ)料集,幫助語(yǔ)言模型引入結(jié)構(gòu)化知識(shí)。
實(shí)驗(yàn)
實(shí)驗(yàn)在知識(shí)探測(cè)(LAMA數(shù)據(jù)集)和開(kāi)放域QA(NaturalQuestions和WebQuestions)上進(jìn)行,作者分別嘗試REALM上的三種檢索語(yǔ)料集設(shè)定:ORIGINAL(Wikipedia Text)、REPLACED(only KELM Corpus)和AUGMENTED(Wikipedia text + KELM Corpus),結(jié)果如下:
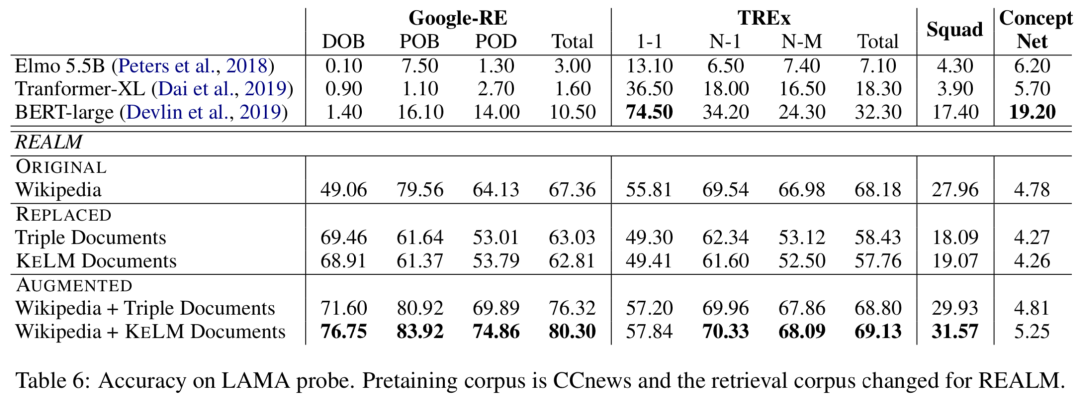
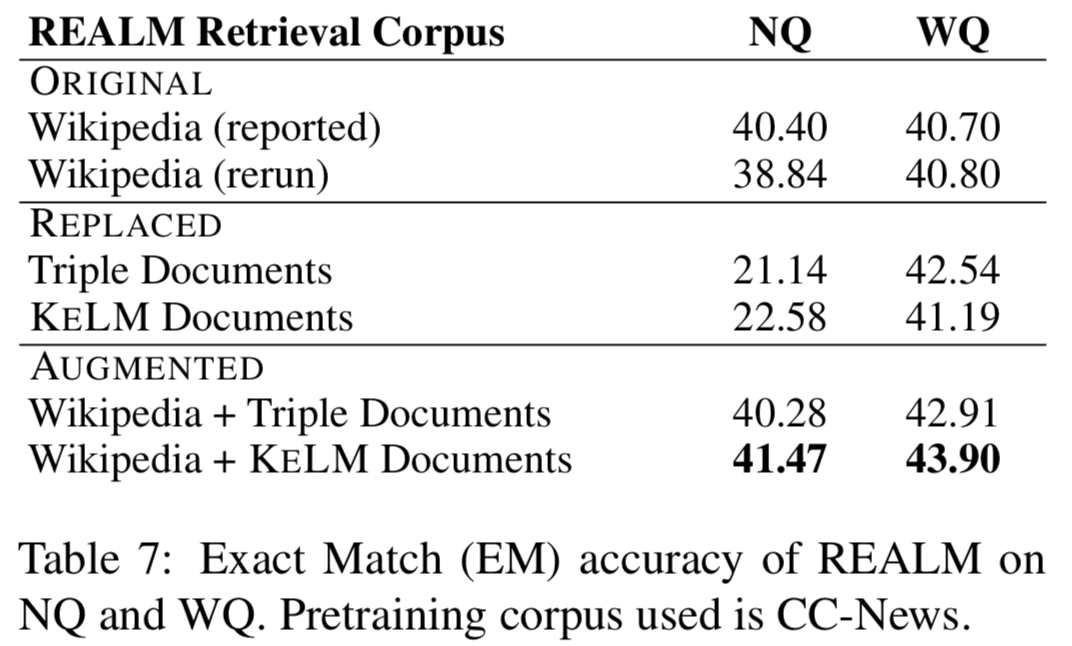
可以看出通過(guò)文本化結(jié)構(gòu)知識(shí)來(lái)擴(kuò)充檢索語(yǔ)料集,在知識(shí)探測(cè)和開(kāi)放域QA上都有提升。作者還進(jìn)行了實(shí)驗(yàn),將原始的Wikidata三元組而非KELM語(yǔ)料庫(kù)整合進(jìn)語(yǔ)言模型,結(jié)果確認(rèn)了結(jié)構(gòu)化知識(shí)文本化的有效性。
3

論文動(dòng)機(jī)
本文通過(guò)知識(shí)監(jiān)督的方式來(lái)建模文本中的關(guān)系事實(shí)從而增強(qiáng)預(yù)訓(xùn)練語(yǔ)言模型,包括同時(shí)建模句子內(nèi)以及跨句子的關(guān)系信息,并提出對(duì)比學(xué)習(xí)的框架ERICA來(lái)全面學(xué)習(xí)實(shí)體和關(guān)系的交互,從而更好捕捉文本中關(guān)系事實(shí)。具體包含了兩個(gè)預(yù)訓(xùn)練任務(wù):(1)實(shí)體判別:給定一個(gè)頭實(shí)體和關(guān)系,推斷可能的尾實(shí)體;(2)關(guān)系判別:判別兩個(gè)關(guān)系是否語(yǔ)義相似。
模型
ERICA根據(jù)無(wú)監(jiān)督數(shù)據(jù)集和外部知識(shí)圖譜構(gòu)建遠(yuǎn)程監(jiān)督幫助預(yù)訓(xùn)練。給定一個(gè)段落,枚舉出所有實(shí)體以及它們之間存在的關(guān)系,從而構(gòu)建整個(gè)對(duì)比學(xué)習(xí)的正樣本集。
1. 實(shí)體&關(guān)系表示
給定一個(gè)文本,首先使用PLM進(jìn)行編碼并得到每個(gè)token的隱表示,然后對(duì)提及實(shí)體的連續(xù)tokens上的表示做mean pooling得到當(dāng)前實(shí)體表示,如果一個(gè)文本多次提及一個(gè)實(shí)體,則對(duì)多個(gè)表示進(jìn)行平均得到最終實(shí)體表示,而對(duì)于關(guān)系表示,通過(guò)組合關(guān)系的首尾實(shí)體的表示得到其表示。
2. 實(shí)體判別任務(wù)
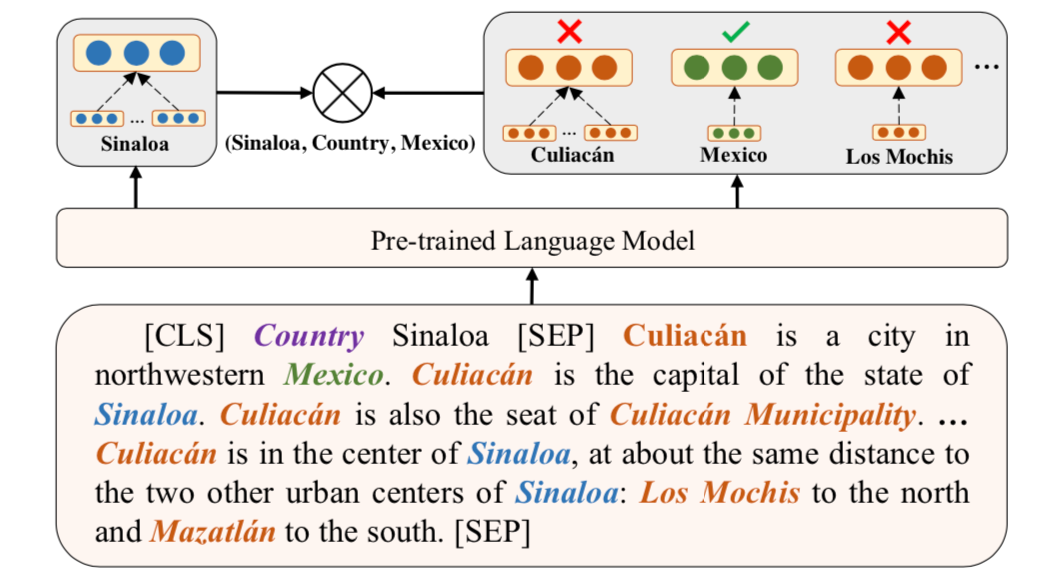
從正樣本集中選擇一個(gè)元組,給定其中的頭實(shí)體和關(guān)系,通過(guò)對(duì)比學(xué)習(xí)使得正確尾實(shí)體相較于文本中其他實(shí)體,要和頭實(shí)體更相近,具體公式如下。
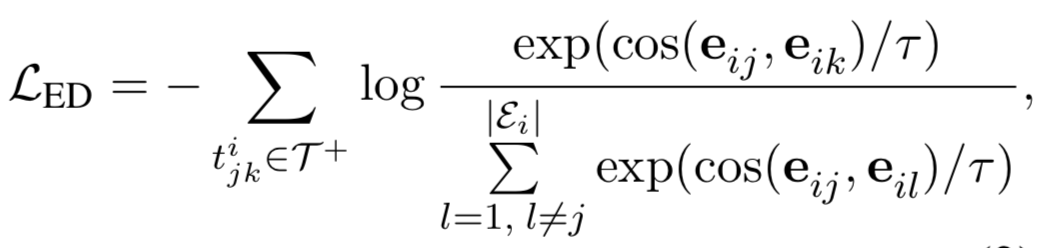
3. 關(guān)系判別任務(wù)
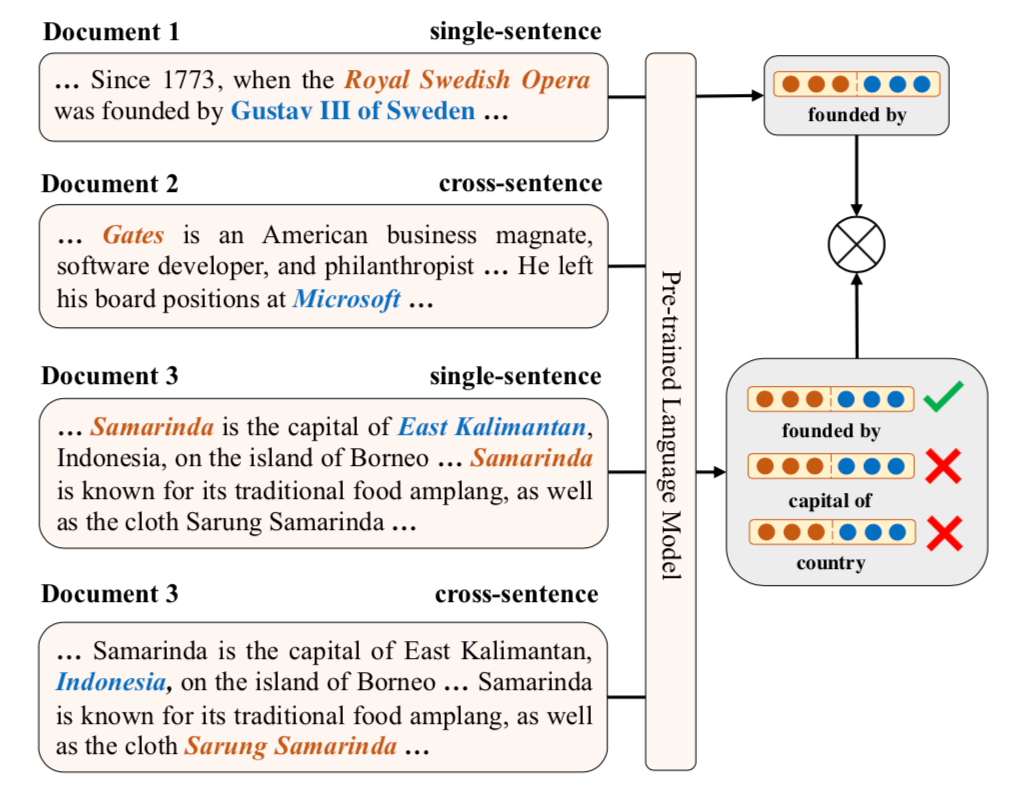
這個(gè)任務(wù)需要判別兩個(gè)關(guān)系是否語(yǔ)義相似,這里考慮到了句子內(nèi)以及跨句子的關(guān)系,從而使得模型隱式地學(xué)習(xí)到了復(fù)雜關(guān)系鏈。具體方法如上圖,通過(guò)對(duì)比學(xué)習(xí)使得相同的關(guān)系表示(由實(shí)體對(duì)表示計(jì)算得到)應(yīng)該更相近。
實(shí)驗(yàn)
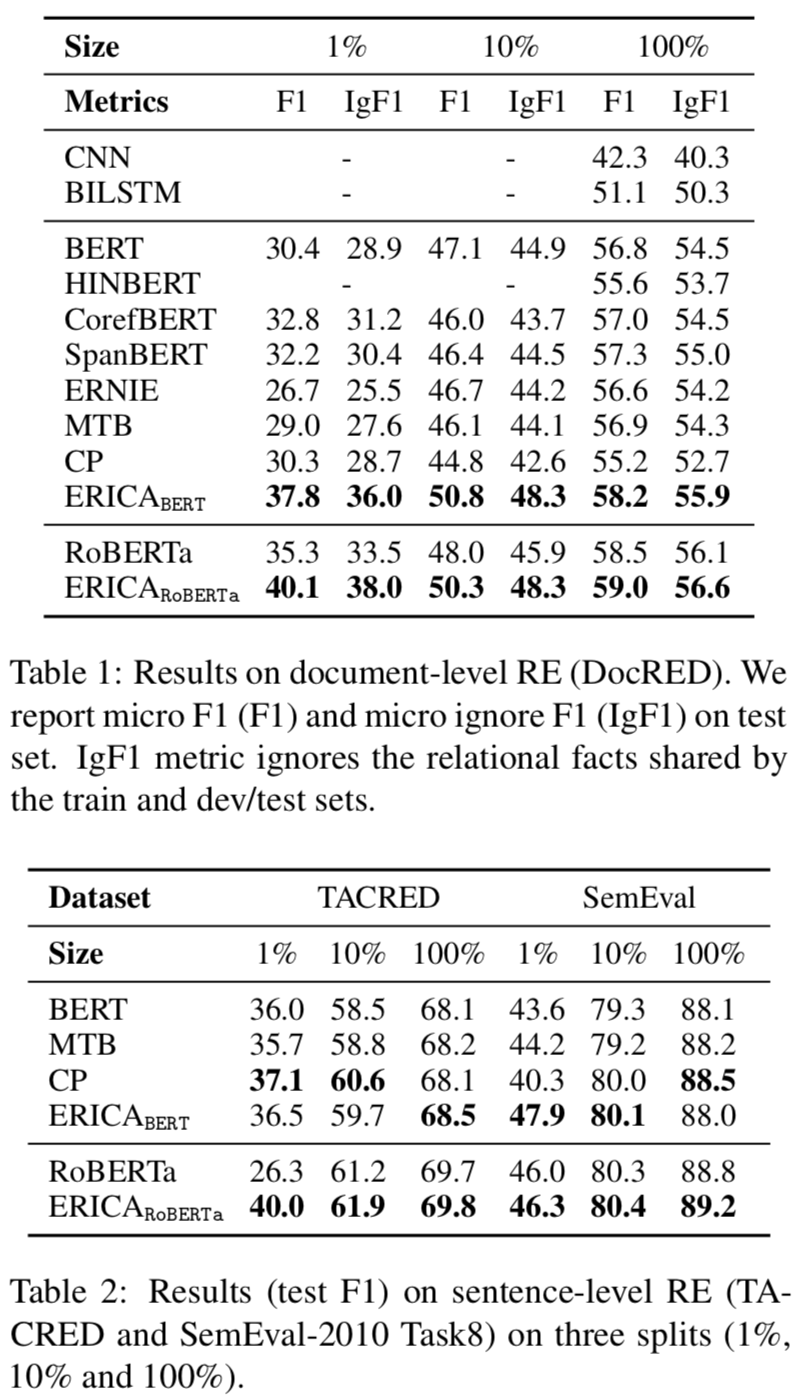
本文在BERT和RoBERTa都進(jìn)行了增強(qiáng)訓(xùn)練,遠(yuǎn)程監(jiān)督根據(jù)English Wikipedia和Wikidata構(gòu)建,評(píng)估實(shí)驗(yàn)在關(guān)系抽取、實(shí)體分類和問(wèn)題回答任務(wù)上進(jìn)行的,實(shí)驗(yàn)結(jié)果分別如下:
Relation Extraction
Entity Typing
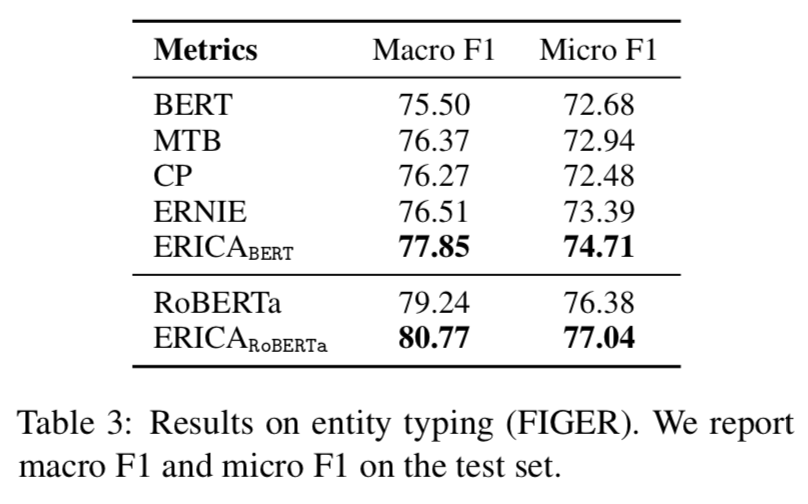
Question Answering
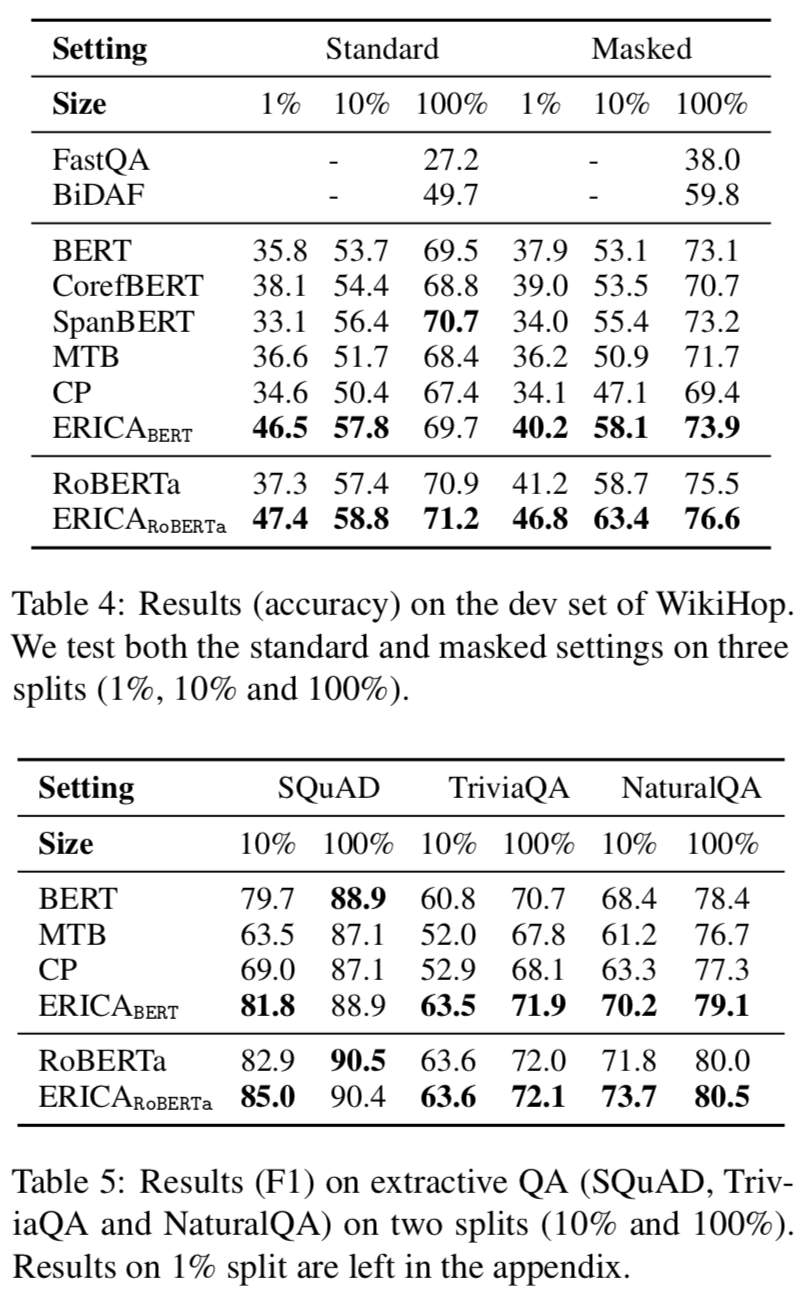
可以看出ERICA模型在不同任務(wù)不同數(shù)據(jù)集合上都有一定的提升。
總結(jié)
本次分享我們介紹了三篇知識(shí)增強(qiáng)的預(yù)訓(xùn)練語(yǔ)言模型文章,分別圍繞知識(shí)向量、知識(shí)檢索以及知識(shí)監(jiān)督的方法來(lái)向語(yǔ)言模型中注入知識(shí)。第一篇通過(guò)一個(gè)知識(shí)聚合器將KG中的實(shí)體和關(guān)系向量顯式注入語(yǔ)言模型;第二篇通過(guò)將知識(shí)圖譜轉(zhuǎn)換為自然文本,為檢索型語(yǔ)言模型擴(kuò)充檢索知識(shí)語(yǔ)料庫(kù),從而將結(jié)構(gòu)化知識(shí)無(wú)縫地注入到語(yǔ)言模型中;第三篇基于知識(shí)監(jiān)督的方式來(lái)建模文本中的關(guān)系事實(shí)從而增強(qiáng)預(yù)訓(xùn)練語(yǔ)言模型。
原文標(biāo)題:從最新的ACL、NAACL和EMNLP中詳解知識(shí)增強(qiáng)的語(yǔ)言預(yù)訓(xùn)練模型
文章出處:【微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
審核編輯:湯梓紅
-
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
558瀏覽量
10661
原文標(biāo)題:從最新的ACL、NAACL和EMNLP中詳解知識(shí)增強(qiáng)的語(yǔ)言預(yù)訓(xùn)練模型
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
【大語(yǔ)言模型:原理與工程實(shí)踐】大語(yǔ)言模型的基礎(chǔ)技術(shù)
【大語(yǔ)言模型:原理與工程實(shí)踐】大語(yǔ)言模型的預(yù)訓(xùn)練
檢索增強(qiáng)型語(yǔ)言表征模型預(yù)訓(xùn)練
預(yù)訓(xùn)練語(yǔ)言模型設(shè)計(jì)的理論化認(rèn)識(shí)
如何向大規(guī)模預(yù)訓(xùn)練語(yǔ)言模型中融入知識(shí)?

Multilingual多語(yǔ)言預(yù)訓(xùn)練語(yǔ)言模型的套路
一種基于亂序語(yǔ)言模型的預(yù)訓(xùn)練模型-PERT
利用視覺(jué)語(yǔ)言模型對(duì)檢測(cè)器進(jìn)行預(yù)訓(xùn)練
預(yù)訓(xùn)練語(yǔ)言模型的字典描述
CogBERT:腦認(rèn)知指導(dǎo)的預(yù)訓(xùn)練語(yǔ)言模型
預(yù)訓(xùn)練數(shù)據(jù)大小對(duì)于預(yù)訓(xùn)練模型的影響
基于預(yù)訓(xùn)練模型和語(yǔ)言增強(qiáng)的零樣本視覺(jué)學(xué)習(xí)

基于醫(yī)學(xué)知識(shí)增強(qiáng)的基礎(chǔ)模型預(yù)訓(xùn)練方法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論