 25個Pandas實用技巧
25個Pandas實用技巧
從剪貼板中創建DataFrame
假設你將一些數據儲存在Excel或者Google Sheet中,你又想要盡快地將他們讀取至DataFrame中。你需要選擇這些數據并復制至剪貼板。然后,你可以使用read_clipboard()函數將他們讀取至DataFrame中:
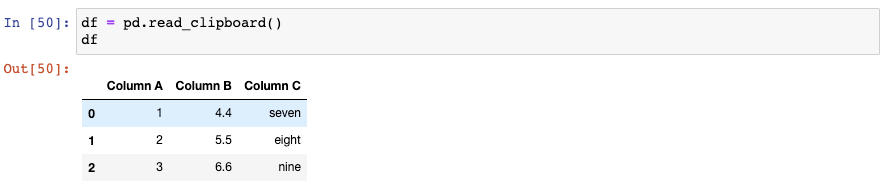
和read_csv()類似,read_clipboard()會自動檢測每一列的正確的數據類型:

讓我們再復制另外一個數據至剪貼板:
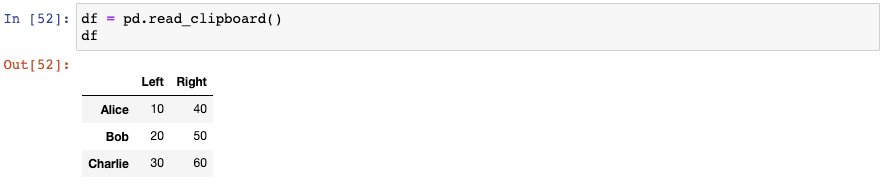
神奇的是,pandas已經將第一列作為索引了:

需要注意的是,如果你想要你的工作在未來可復制,那么read_clipboard()并不值得推薦。
將DataFrame劃分為兩個隨機的子集
假設你想要將一個DataFrame劃分為兩部分,隨機地將75%的行給一個DataFrame,剩下的25%的行給另一個DataFrame。
舉例來說,我們的movie ratings這個DataFrame有979行:

我們可以使用sample()函數來隨機選取75%的行,并將它們賦值給"movies_1"DataFrame:

接著我們使用drop()函數來舍棄“moive_1”中出現過的行,將剩下的行賦值給"movies_2"DataFrame:

你可以發現總的行數是正確的:

你還可以檢查每部電影的索引,或者"moives_1":

或者"moives_2":

需要注意的是,這個方法在索引值不唯一的情況下不起作用。
注:該方法在機器學習或者深度學習中很有用,因為在模型訓練前,我們往往需要將全部數據集按某個比例劃分成訓練集和測試集。該方法既簡單又高效,值得學習和嘗試。
多種類型過濾DataFrame
讓我們先看一眼movies這個DataFrame:
In[60]: movies.head() Out[60]:
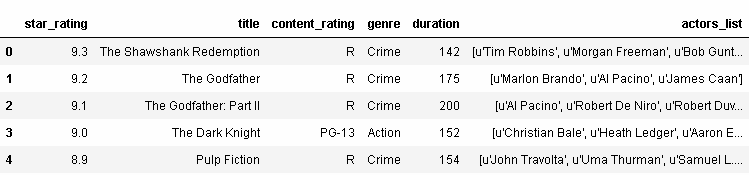
其中有一列是genre(類型):

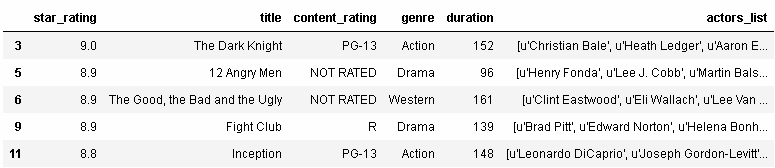
比如我們想要對該DataFrame進行過濾,我們只想顯示genre為Action或者Drama或者Western的電影,我們可以使用多個條件,以"or"符號分隔:
In[62]: movies[(movies.genre=='Action')| (movies.genre=='Drama')| (movies.genre== 'Western')].head() Out[62]:
但是,你實際上可以使用isin()函數將代碼寫得更加清晰,將genres列表傳遞給該函數:
In[63]: movies[movies.genre.isin(['Action','Drama','Western'])].head() Out[63]:
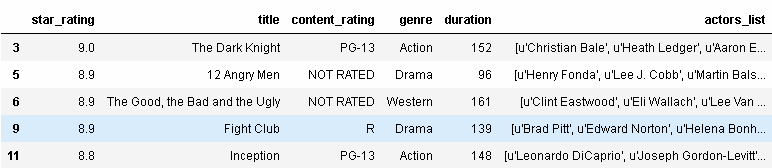
如果你想要進行相反的過濾,也就是你將吧剛才的三種類型的電影排除掉,那么你可以在過濾條件前加上破浪號:
In[64]: movies[~movies.genre.isin(['Action', 'Drama','Western'])].head() Out[64]:

這種方法能夠起作用是因為在Python中,波浪號表示“not”操作。
DataFrame篩選數量最多類別
假設你想要對movies這個DataFrame通過genre進行過濾,但是只需要前3個數量最多的genre。
我們對genre使用value_counts()函數,并將它保存成counts(type為Series):
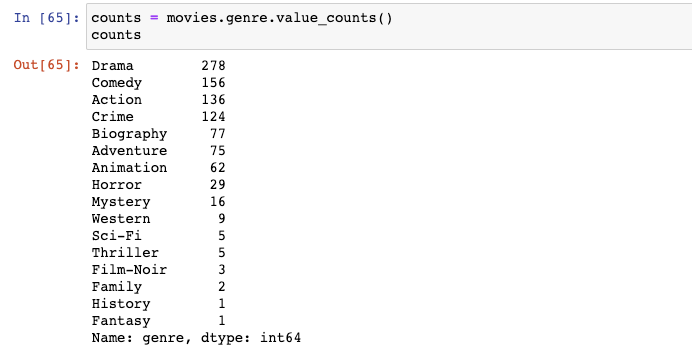
該Series的nlargest()函數能夠輕松地計算出Series中前3個最大值:

事實上我們在該Series中需要的是索引:

最后,我們將該索引傳遞給isin()函數,該函數會把它當成genre列表:
In[68]: movies[movies.genre.isin(counts.nlargest(3).index)].head() Out[68]:

這樣,在DataFrame中只剩下Drame, Comdey, Action這三種類型的電影了。
處理缺失值
讓我們來看一看UFO sightings這個DataFrame:
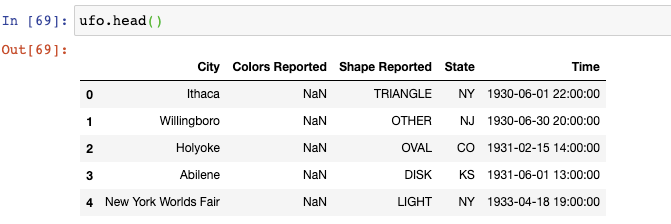
你將會注意到有些值是缺失的。
為了找出每一列中有多少值是缺失的,你可以使用isna()函數,然后再使用sum():

isna()會產生一個由True和False組成的DataFrame,sum()會將所有的True值轉換為1,False轉換為0并把它們加起來。
類似地,你可以通過mean()和isna()函數找出每一列中缺失值的百分比。

如果你想要舍棄那些包含了缺失值的列,你可以使用dropna()函數:
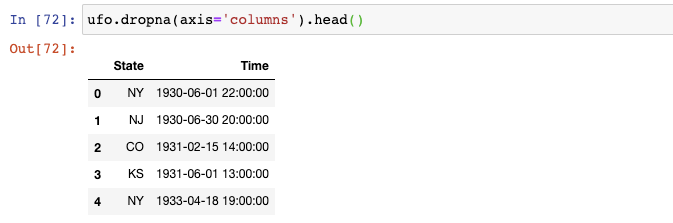
或者你想要舍棄那么缺失值占比超過10%的列,你可以給dropna()設置一個閾值:
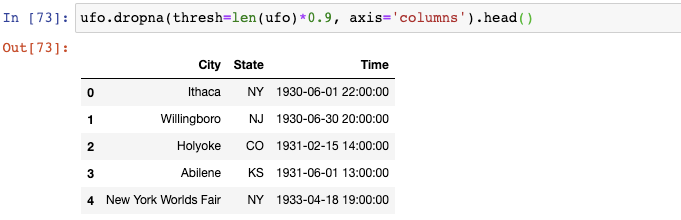
len(ufo)返回總行數,我們將它乘以0.9,以告訴pandas保留那些至少90%的值不是缺失值的列。
一個字符串劃分成多列
我們先創建另一個新的示例DataFrame:
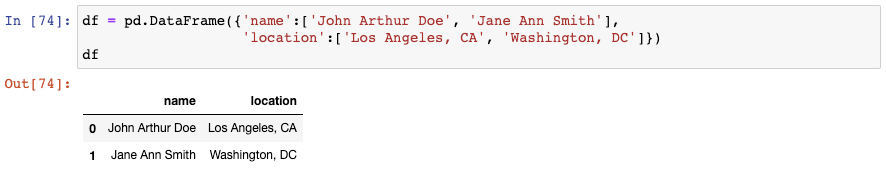
如果我們需要將“name”這一列劃分為三個獨立的列,用來表示first, middle, last name呢?我們將會使用str.split()函數,告訴它以空格進行分隔,并將結果擴展成一個DataFrame:

這三列實際上可以通過一行代碼保存至原來的DataFrame:

如果我們想要劃分一個字符串,但是僅保留其中一個結果列呢?比如說,讓我們以", "來劃分location這一列:

如果我們只想保留第0列作為city name,我們僅需要選擇那一列并保存至DataFrame:

Series擴展成DataFrame
讓我們創建一個新的示例DataFrame:

這里有兩列,第二列包含了Python中的由整數元素組成的列表。
如果我們想要將第二列擴展成DataFrame,我們可以對那一列使用apply()函數并傳遞給Series constructor:

通過使用concat()函數,我們可以將原來的DataFrame和新的DataFrame組合起來:

對多個函數進行聚合
讓我們來看一眼從Chipotle restaurant chain得到的orders這個DataFrame:
In[82]: orders.head(10) Out[82]:
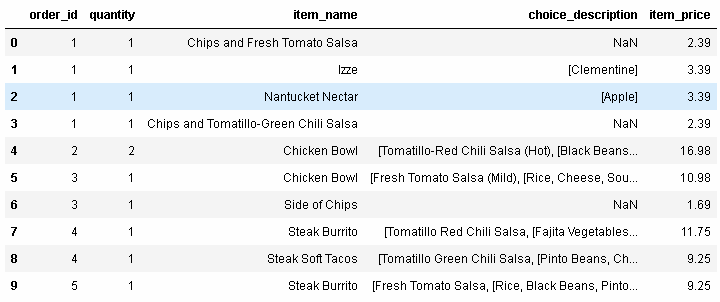
每個訂單(order)都有訂單號(order_id),包含一行或者多行。為了找出每個訂單的總價格,你可以將那個訂單號的價格(item_price)加起來。比如,這里是訂單號為1的總價格:

如果你想要計算每個訂單的總價格,你可以對order_id使用groupby(),再對每個group的item_price進行求和。

但是,事實上你不可能在聚合時僅使用一個函數,比如sum()。為了對多個函數進行聚合,你可以使用agg()函數,傳給它一個函數列表,比如sum()和count():
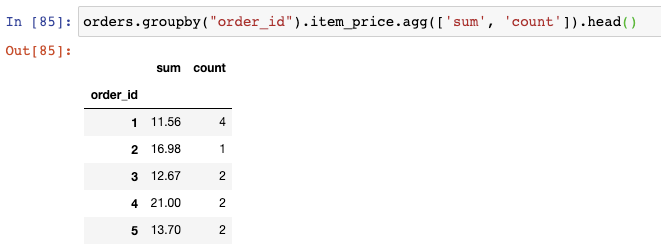
這將告訴我們沒定訂單的總價格和數量。
聚合結果與DataFrame組合
讓我們再看一眼orders這個DataFrame:
In[86]: orders.head(10) Out[86]:
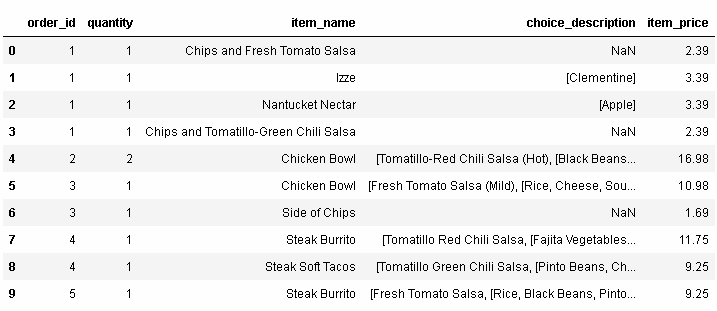
如果我們想要增加新的一列,用于展示每個訂單的總價格呢?回憶一下,我們通過使用sum()函數得到了總價格:

sum()是一個聚合函數,這表明它返回輸入數據的精簡版本(reduced version )。
換句話說,sum()函數的輸出:

比這個函數的輸入要小:

解決的辦法是使用transform()函數,它會執行相同的操作但是返回與輸入數據相同的形狀:

我們將這個結果存儲至DataFrame中新的一列:
In[91]: orders['total_price']= total_price orders.head(10) Out[91]:
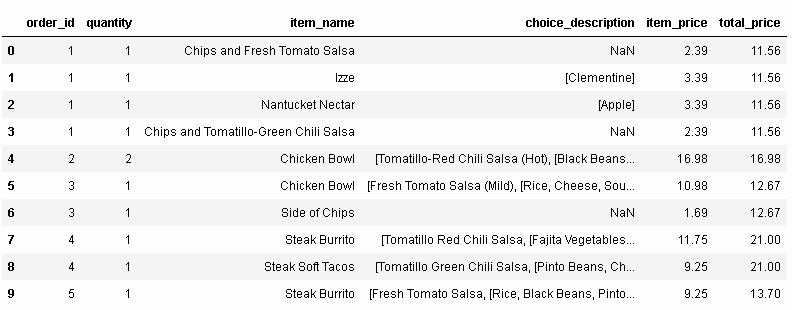
你可以看到,每個訂單的總價格在每一行中顯示出來了。
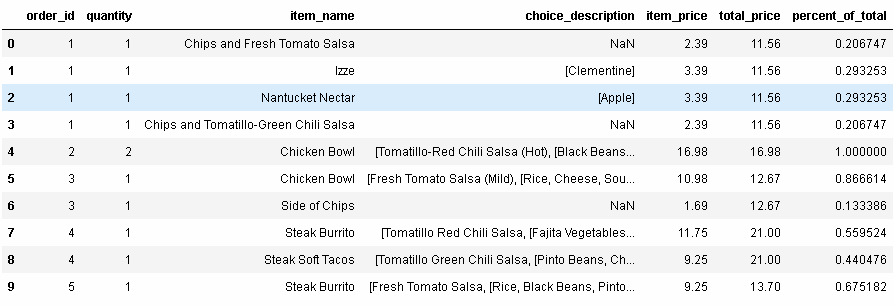
這樣我們就能方便地甲酸每個訂單的價格占該訂單的總價格的百分比:
In[92]: orders['percent_of_total']=orders.item_price/orders.total_price orders.head(10) In[92]:
選取行和列的切片
讓我們看一眼另一個數據集:
In[93]: titanic.head() Out[93]:
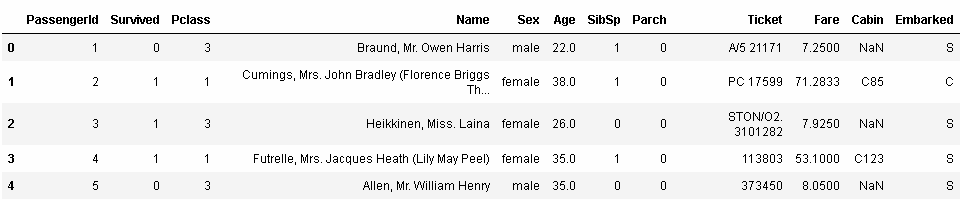
這就是著名的Titanic數據集,它保存了Titanic上乘客的信息以及他們是否存活。
如果你想要對這個數據集做一個數值方面的總結,你可以使用describe()函數:
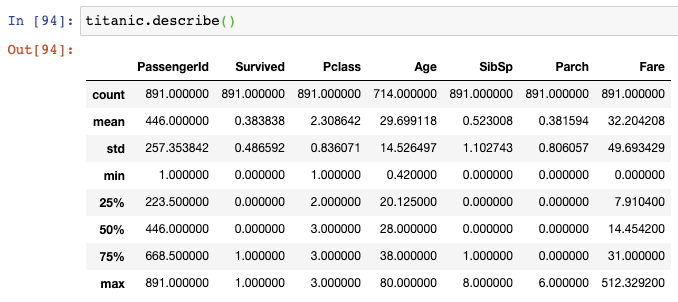
但是,這個DataFrame結果可能比你想要的信息顯示得更多。
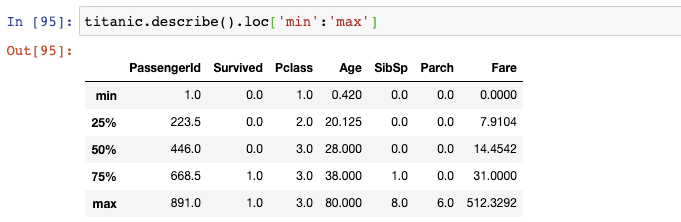
如果你想對這個結果進行過濾,只想顯示“五數概括法”(five-number summary)的信息,你可以使用loc函數并傳遞"min"到"max"的切片:
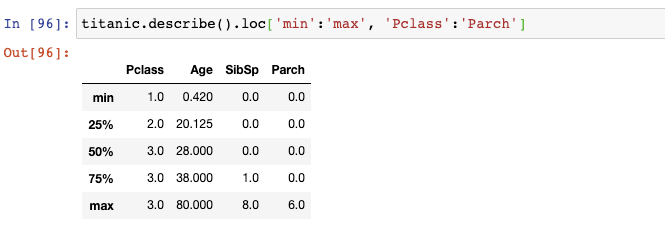
如果你不是對所有列都感興趣,你也可以傳遞列名的切片:
MultiIndexed Series重塑
Titanic數據集的Survived列由1和0組成,因此你可以對這一列計算總的存活率:

如果你想對某個類別,比如“Sex”,計算存活率,你可以使用groupby():

如果你想一次性對兩個類別變量計算存活率,你可以對這些類別變量使用groupby():
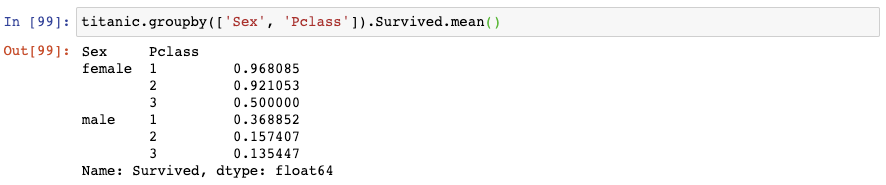
該結果展示了由Sex和Passenger Class聯合起來的存活率。它存儲為一個MultiIndexed Series,也就是說它對實際數據有多個索引層級。
這使得該數據難以讀取和交互,因此更為方便的是通過unstack()函數將MultiIndexed Series重塑成一個DataFrame:

該DataFrame包含了與MultiIndexed Series一樣的數據,不同的是,現在你可以用熟悉的DataFrame的函數對它進行操作。
創建數據透視表
如果你經常使用上述的方法創建DataFrames,你也許會發現用pivot_table()函數更為便捷:

想要使用數據透視表,你需要指定索引(index),列名(columns),值(values)和聚合函數(aggregation function)。
數據透視表的另一個好處是,你可以通過設置margins=True輕松地將行和列都加起來:
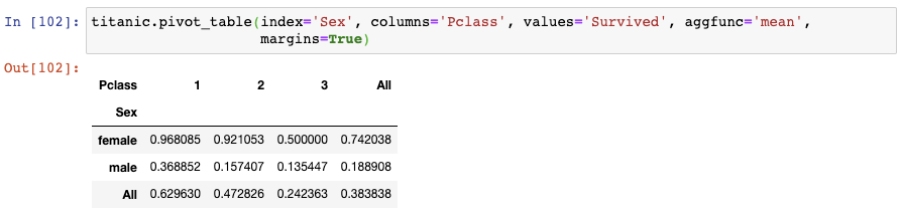
這個結果既顯示了總的存活率,也顯示了Sex和Passenger Class的存活率。
最后,你可以創建交叉表(cross-tabulation),只需要將聚合函數由"mean"改為"count":
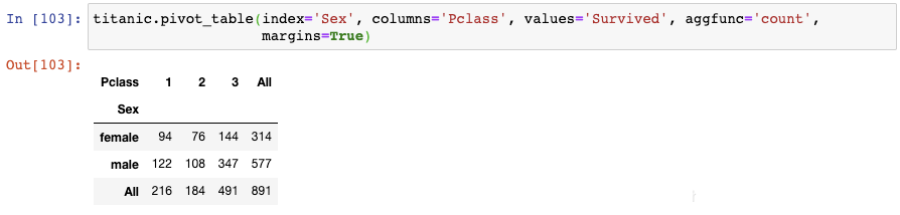
這個結果展示了每一對類別變量組合后的記錄總數。
連續數據轉類別數據
讓我們來看一下Titanic數據集中的Age那一列:
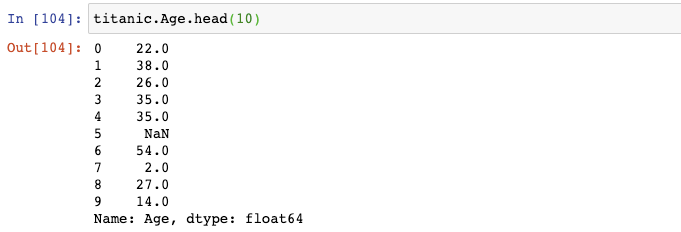
它現在是連續性數據,但是如果我們想要將它轉變成類別數據呢?
一個解決辦法是對年齡范圍打標簽,比如"adult", "young adult", "child"。實現該功能的最好方式是使用cut()函數:
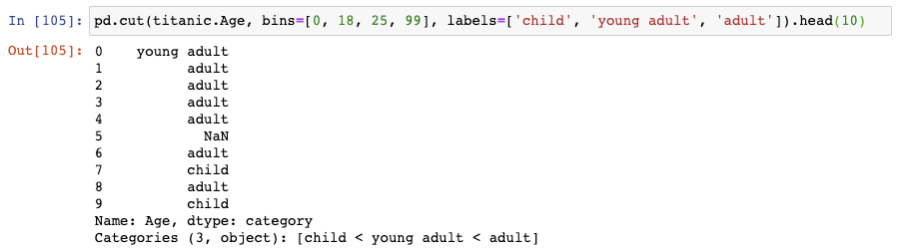
這會對每個值打上標簽。0到18歲的打上標簽"child",18-25歲的打上標簽"young adult",25到99歲的打上標簽“adult”。
注意到,該數據類型為類別變量,該類別變量自動排好序了(有序的類別變量)。
Style a DataFrame
上一個技巧在你想要修改整個jupyter notebook中的顯示會很有用。但是,一個更靈活和有用的方法是定義特定DataFrame中的格式化(style)。
讓我們回到stocks這個DataFrame:
我們可以創建一個格式化字符串的字典,用于對每一列進行格式化。然后將其傳遞給DataFrame的style.format()函數:
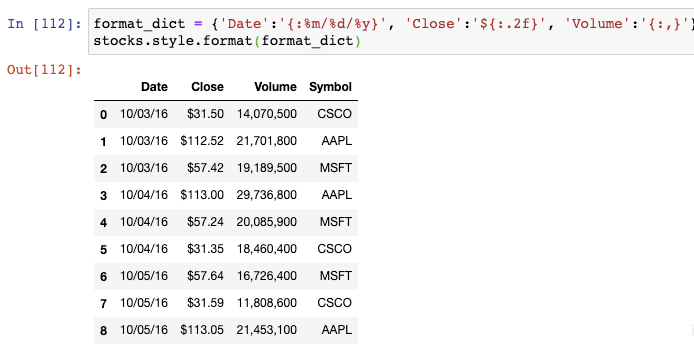
注意到,Date列是month-day-year的格式,Close列包含一個$符號,Volume列包含逗號。
我們可以通過鏈式調用函數來應用更多的格式化:
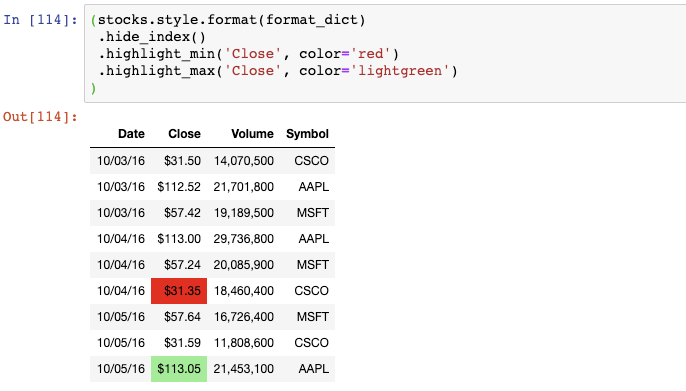
我們現在隱藏了索引,將Close列中的最小值高亮成紅色,將Close列中的最大值高亮成淺綠色。
這里有另一個DataFrame格式化的例子:
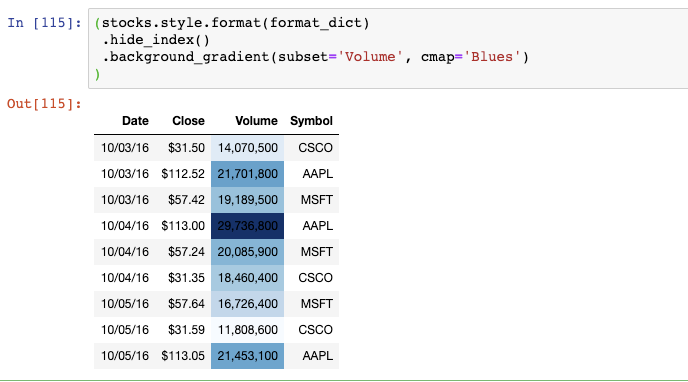
Volume列現在有一個漸變的背景色,你可以輕松地識別出大的和小的數值。
最后一個例子:
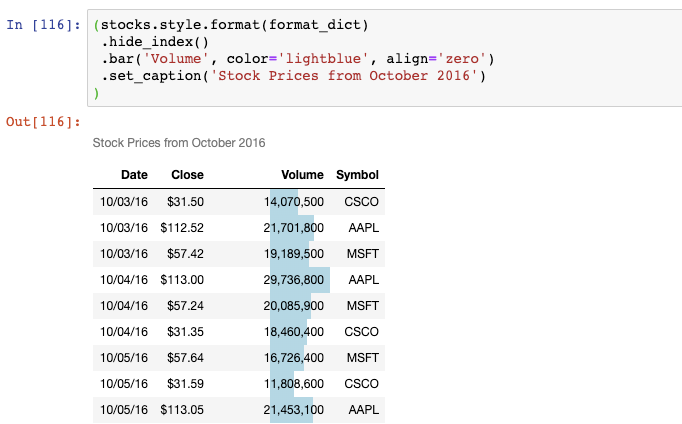
現在,Volumn列上有一個條形圖,DataFrame上有一個標題。
請注意,還有許多其他的選項你可以用來格式化DataFrame。
額外技巧
Profile a DataFrame
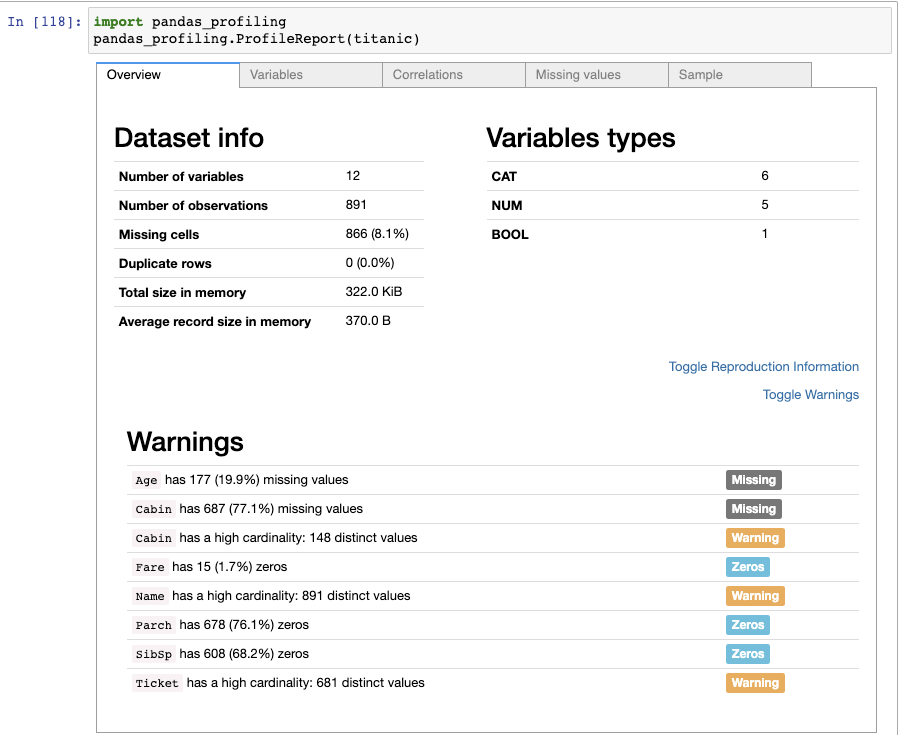
假設你拿到一個新的數據集,你不想要花費太多力氣,只是想快速地探索下。那么你可以使用pandas-profiling這個模塊。
在你的系統上安裝好該模塊,然后使用ProfileReport()函數,傳遞的參數為任何一個DataFrame。它會返回一個互動的HTML報告:
第一部分為該數據集的總覽,以及該數據集可能出現的問題列表
第二部分為每一列的總結。你可以點擊"toggle details"獲取更多信息
第三部分顯示列之間的關聯熱力圖
第四部分為缺失值情況報告
第五部分顯示該數據及的前幾行
使用示例如下(只顯示第一部分的報告):
原文鏈接:
https://nbviewer.jupyter.org/github/justmarkham/pandas-videos/blob/master/top_25_pandas_tricks.ipynb
-
函數
+關注
關注
3文章
4371瀏覽量
64210 -
機器學習
+關注
關注
66文章
8492瀏覽量
134106
原文標題:這 25 個 Pandas 實用技巧你都會嗎
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
泰克示波器MSO58B光標橫豎切換操作指南與實用技巧

Altium Designer AD 25 軟件安裝包下載
【Java開發必備】IntelliJ IDEA數據庫功能進階指南:9個JetBrains工程師私藏技巧

德索工程師教您快速排查 BNC 連接器接線故障的實用技巧

NNV25-05S05A3NT NNV25-05S05A3NT

NNV25-05S05ANT NNV25-05S05ANT
DIY 達人必看:BNC 連接器接線工具套裝精選及實用技巧全解析


三星Galaxy S25/S25+發布 AI賦能引領手機新潮流
將AINN和AGND接在了一起,請問AMC1306M25的AGND的地和隔離電源的地是一個地嗎?
RAPIDS cuDF將pandas提速近150倍

英偉達股價一個月內上漲25%

keil實用技巧

通向數字創新之路:25個組合電路核心主題概念






 工商網監
工商網監
評論