 淺談GPU: 衡量計算效能的正確姿勢(1)
淺談GPU: 衡量計算效能的正確姿勢(1)
琢磨了好幾天,也不知道公眾號第一篇正式文章應該怎么寫。現在很后悔在朋友圈高調公開公眾號,還竟敢宣稱有15年行業經驗,大家不要信以為真,其實不過是一年經驗重復了十幾年而已。連知乎的小朋友都知道問問題的正確姿勢,我真是有些汗顏。
言歸正狀,萬事開頭難,現在騎虎難下,也只好勉力為之。在這里想先介紹些今后文章經常會涉及的一些指標概念,希望能達成基本的共識,到時候交流起來會方便些。
Lateny和Throughput
1 延遲(latency),完成一個任務所需要的時間。
2.吞吐量(throughput),單位時間完成的任務量。
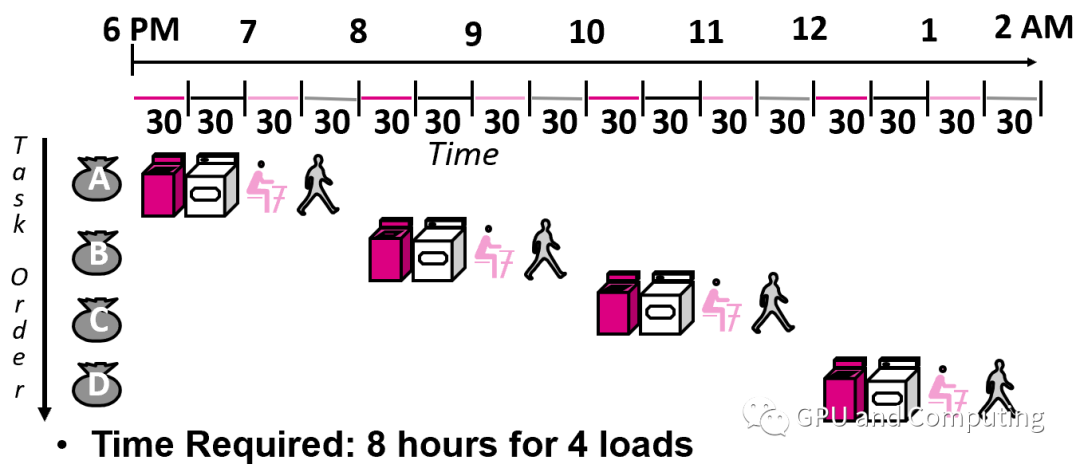
體系結構大神David.A.Patterson在他的著作《計算機組成和設計》用洗衣過程來做譬喻。洗衣過程由清洗,烘干,折疊,收納四個環節組成,每個環節耗時30分鐘,所以每次洗衣任務的latency是2個小時,沒有優化以前,8個小時的完成4次洗衣任務,所以throughput只有0.5。
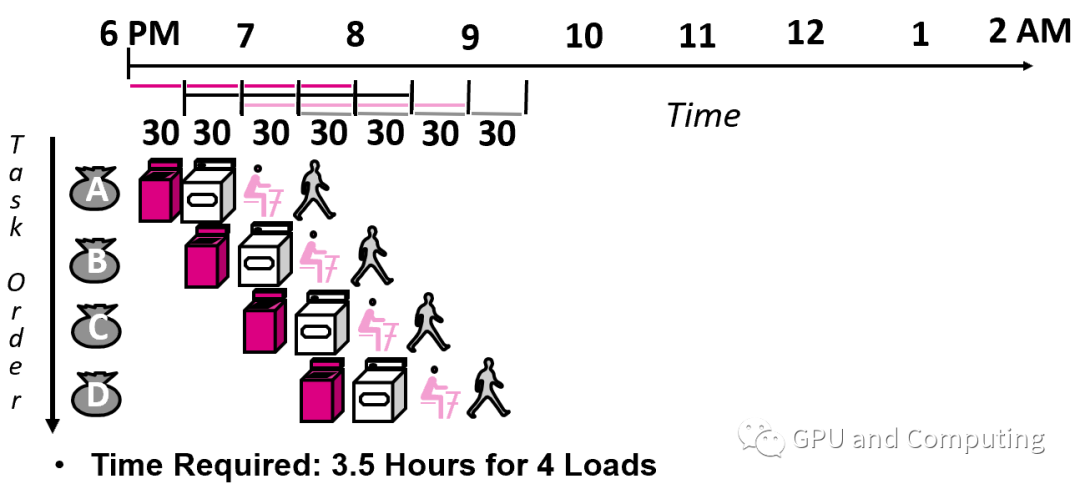
經過流水線改造以后,效率得到改善,雖然每次洗衣還是花費2小時,但單位時間完成的任務量大大提升,4次洗衣任務只花了3.5個小時。
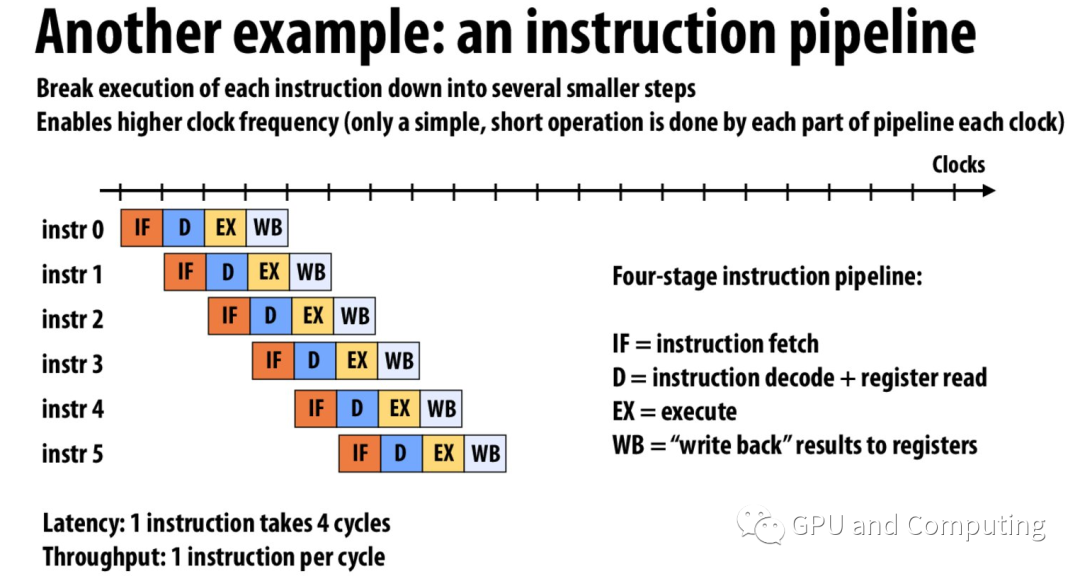
我們可以把生活常識映射到處理器的流水線(Pipeline)設計,處理器的指令Pipeline通過實現指令級的并行(Instruction Level Parallelism)來提高throughput。這種ILP的優化對碼農們就是免費的午餐,躺著程序性能就上去了。
另外,如下圖,我們也可以通過多核CPU或者內置很多計算單元的GPU來提高程序整體的性能(throughput),這種優化屬于線程級并行(Thread Level Parallelism)。相比ILP,TLP對碼農不太友好,不再供應免費的午餐,我們需要編寫多線程程序,甚至通過專門的接口(CUDA/OpenCL)讓CPU/GPU忙碌起來,才能得到性能的提升。
第一篇先寫到這兒了,再長就沒人看了,接下來會介紹其它幾個重要概念。
編輯:lyn
-
處理器
+關注
關注
68文章
19797瀏覽量
233421 -
cpu
+關注
關注
68文章
11029瀏覽量
215873 -
吞吐量
+關注
關注
0文章
48瀏覽量
12472 -
延遲
+關注
關注
1文章
74瀏覽量
13730
原文標題:GPU: 衡量計算效能的正確姿勢(1)
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
常見傳動機構負載慣量計算方法及實例

淺談電磁流量計的常見故障及排除方法
GPU加速計算平臺的優勢
GPU云計算服務怎么樣
調理電路的噪聲余量計算如何計算
算智算中心的算力如何衡量?

電磁流量計的正確調試步驟
云端超級計算機使用教程
《CST Studio Suite 2024 GPU加速計算指南》
靶式流量計的工作原理 靶式流量計和渦街流量計比較
平衡流量計計算公式

GPU計算主板學習資料第735篇:基于3U VPX的AGX Xavier GPU計算主板 信號計算主板 視頻處理 相機信號





 工商網監
工商網監
評論