") 如何在多模態(tài)的語(yǔ)境中利用Transformer強(qiáng)大的表達(dá)能力?
如何在多模態(tài)的語(yǔ)境中利用Transformer強(qiáng)大的表達(dá)能力?
曾幾何時(shí),多模態(tài)預(yù)訓(xùn)練已經(jīng)不是一個(gè)新的話題,各大頂會(huì)諸多論文仿佛搭上Visual和BERT,就能成功paper+=1,VisualBERT、ViLBERT層出不窮,傻傻分不清楚。..。..這些年NLPer在跨界上忙活的不亦樂(lè)乎,提取視覺(jué)特征后和文本詞向量一同輸入到萬(wàn)能的Transformer中,加大力度預(yù)訓(xùn)練,總有意想不到的SOTA。
如何在多模態(tài)的語(yǔ)境中更細(xì)致準(zhǔn)確地利用Transformer強(qiáng)大的表達(dá)能力呢?Facebook最新的 Transformer is All You Need 也許可以給你答案。
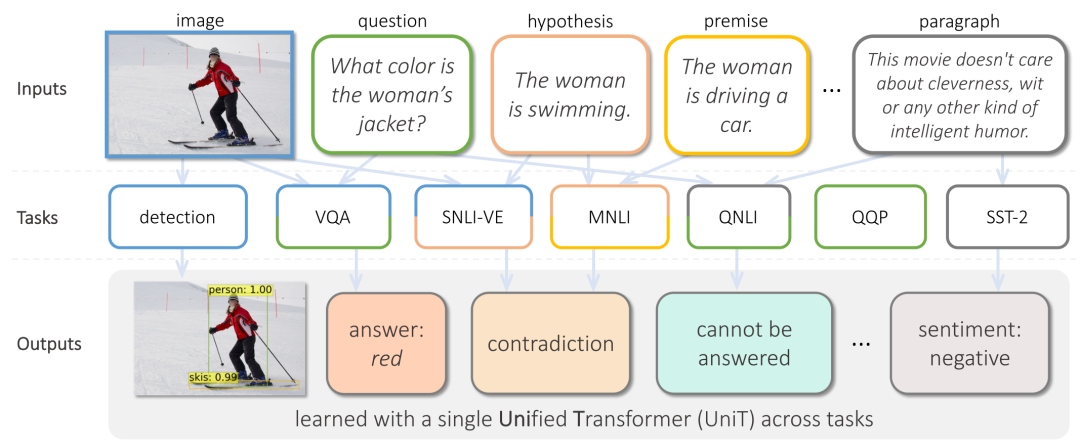
這篇貌似標(biāo)題黨的文章開(kāi)宗明義,針對(duì)文本+視覺(jué)的多模態(tài)任務(wù),用好Transformer就夠了,與許多前作不同,這次提出的模型一個(gè)模型可以解決多個(gè)任務(wù):目標(biāo)檢測(cè)、自然語(yǔ)言理解、視覺(jué)問(wèn)答,各個(gè)模型板塊各司其職、條理清晰:視覺(jué)編碼器、文本編碼器、特征融合解碼器,都是建立在多層Transformer之上,最后添加為每個(gè)任務(wù)設(shè)計(jì)的處理器,通過(guò)多任務(wù)訓(xùn)練,一舉刷新了多個(gè)任務(wù)的榜單。
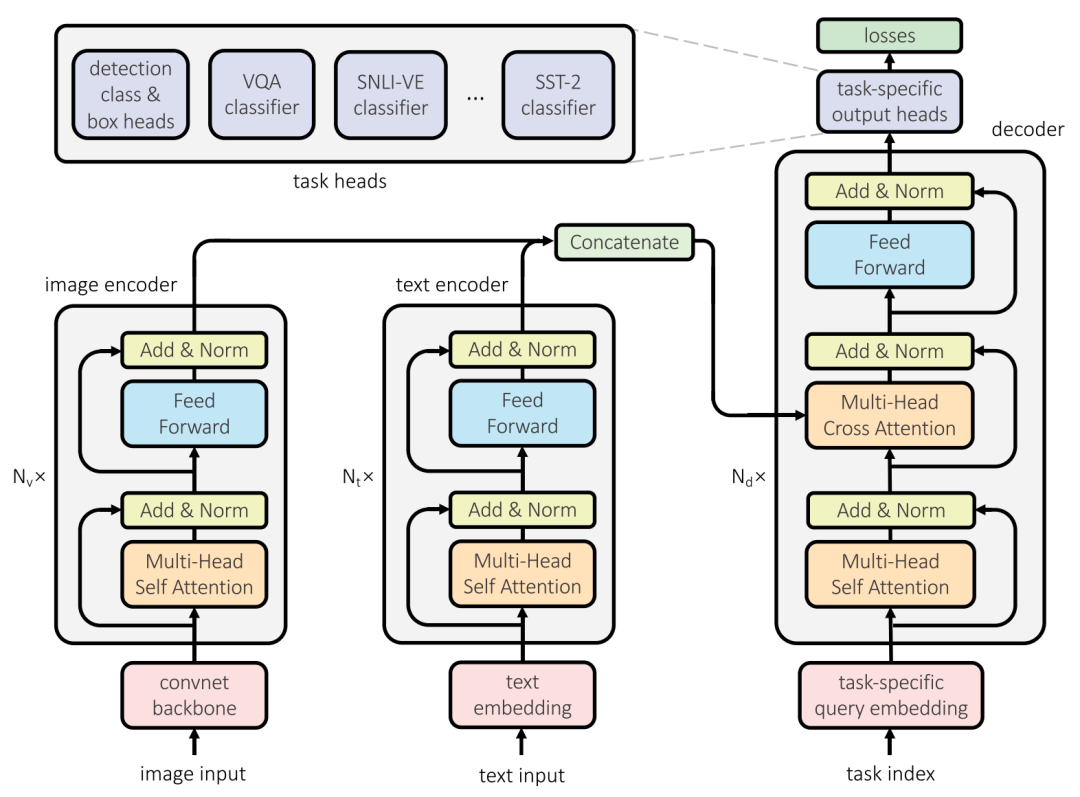
文本編碼器用Transformer提取文本特征是個(gè)老生常談的問(wèn)題,從BERT石破天驚開(kāi)始,純文本領(lǐng)域近乎已被Transformer蠶食殆盡,所以該文也不能免俗,直接借用BERT的結(jié)構(gòu)提取文本內(nèi)容,區(qū)別在于,為了解決多個(gè)任務(wù),在文本序列前添加了一個(gè)針對(duì)不同任務(wù)的參數(shù)向量,在最后輸出隱藏狀態(tài)到解碼器時(shí)再去掉。
視覺(jué)編碼器本文將Transformer強(qiáng)大的表達(dá)能力運(yùn)用到視覺(jué)特征的提取中,由于圖片像素點(diǎn)數(shù)量巨大,首先通過(guò)基于卷積神經(jīng)網(wǎng)絡(luò)的ResNet-50提取卷積特征,極大程度上地降低了特征數(shù)量,最終得到的feature map大小為,然后用全聯(lián)接層調(diào)整單個(gè)特征的維度到,再利用多層Transformer中的注意力機(jī)制提取各個(gè)feature之間的關(guān)系,由于Transformer的輸入是序列,文章將拉成一條長(zhǎng)為的序列,另外和文本編碼器類似,同樣添加了與下游任務(wù)相關(guān)的。
其中是調(diào)整維度的全聯(lián)接層,是多層Transformer編碼器。
模態(tài)融合解碼器多模態(tài)的關(guān)鍵之一就在于怎么同時(shí)利用多個(gè)模態(tài),在本文中是通過(guò)Transformer的解碼器實(shí)現(xiàn)的,這個(gè)解碼器首先將任務(wù)相關(guān)的query做self-attention,再將結(jié)果與文本編碼器和視覺(jué)編碼器的結(jié)果做cross-attention,針對(duì)單一模態(tài)的任務(wù),選取對(duì)應(yīng)編碼器的輸出即可,針對(duì)多模態(tài)的任務(wù),取兩個(gè)編碼器輸出的拼接。
任務(wù)處理器(task-specific output head)之前多模態(tài)預(yù)訓(xùn)練模型往往只針對(duì)某一項(xiàng)任務(wù),而本文提出的一個(gè)模型可以解決多個(gè)文本+視覺(jué)任務(wù),與BERT可以解決多個(gè)文本任務(wù)類似,本文的模型在模態(tài)融合解碼器的結(jié)果上添加為每個(gè)任務(wù)設(shè)計(jì)的處理器,這個(gè)處理器相對(duì)簡(jiǎn)單,用于從隱藏狀態(tài)中提取出與特定任務(wù)相匹配的特征。
目標(biāo)檢測(cè):添加box_head和class_head兩個(gè)前饋神經(jīng)網(wǎng)絡(luò)從最后一層隱藏狀態(tài)中提取特征用來(lái)確定目標(biāo)位置和預(yù)測(cè)目標(biāo)類型。
自然語(yǔ)言理解、視覺(jué)問(wèn)答:通過(guò)基于全聯(lián)接層的分類模型實(shí)現(xiàn),將模態(tài)融合解碼器結(jié)果的第一位隱藏狀態(tài)輸入到兩層全聯(lián)接層并以GeLU作為激活函數(shù),最后計(jì)算交叉熵?fù)p失。
實(shí)驗(yàn)與總結(jié)本文提出的多模態(tài)預(yù)訓(xùn)練模型各個(gè)板塊劃分明確,通過(guò)多層Transformer分別提取特征,再利用解碼器機(jī)制融合特征并完成下游任務(wù),同時(shí)借助最后一層任務(wù)相關(guān)的處理器,可以通過(guò)一個(gè)模型解決多個(gè)任務(wù),同時(shí)也讓多任務(wù)預(yù)訓(xùn)練成為可能,并在實(shí)驗(yàn)中的各個(gè)數(shù)據(jù)集上得到了論文主要進(jìn)行了兩部分實(shí)驗(yàn):
多任務(wù)學(xué)習(xí):
這里的多任務(wù)涉及目標(biāo)檢測(cè)和視覺(jué)問(wèn)答兩個(gè)任務(wù),在目標(biāo)檢測(cè)上運(yùn)用COCO和VG兩個(gè)數(shù)據(jù)集,在視覺(jué)問(wèn)答上運(yùn)用VQAv2數(shù)據(jù)集。對(duì)比了單一任務(wù)和多任務(wù)同時(shí)訓(xùn)練的結(jié)果,同時(shí)對(duì)比了不同任務(wù)共用解碼器的結(jié)果。
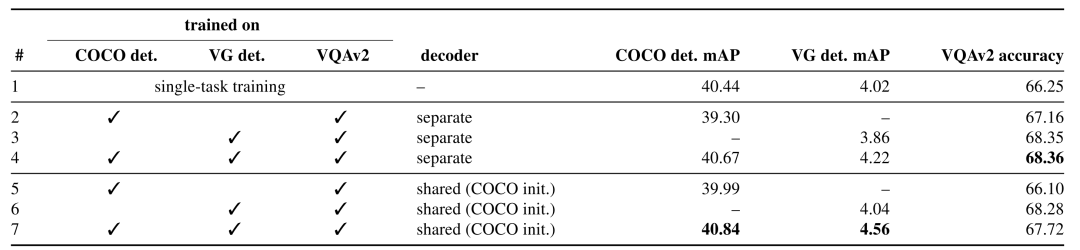
從結(jié)果中我們可以看出,單純的使用多任務(wù)訓(xùn)練并不一定可以提高結(jié)果,不同任務(wù)間雖然相關(guān)但是卻不完全相同,這可能是任務(wù)本身差異或者數(shù)據(jù)集的特性所導(dǎo)致,第二行和第五行可以很明顯地看出COCO上的目標(biāo)檢測(cè)和VQAv2的視覺(jué)問(wèn)答相結(jié)合后,結(jié)果有顯著的下降,然而VG上的目標(biāo)檢測(cè)卻能夠和視覺(jué)問(wèn)答很好地結(jié)合,通過(guò)三個(gè)數(shù)據(jù)集上的共同訓(xùn)練,可以得到最高的結(jié)果。
多模態(tài)學(xué)習(xí):
這一實(shí)驗(yàn)中,為了體現(xiàn)所提出模型能夠有效解決多個(gè)多種模態(tài)的不同任務(wù),論文作者在之前COCO、VG、VQAv2的基礎(chǔ)上,增加了單一文本任務(wù)GLUE的幾個(gè)數(shù)據(jù)集(QNLI、QQP、MNLI、SST-2)和視覺(jué)推斷數(shù)據(jù)集SNLI-VE,從數(shù)據(jù)集的數(shù)量上可以看出本文模型的全能性。與本文對(duì)比的有純文本的BERT、基于Transformer的視覺(jué)模型DETR、多模態(tài)預(yù)訓(xùn)練模型VisualBERT。
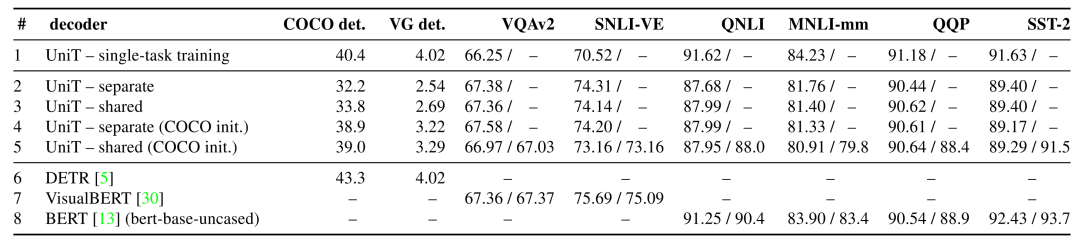
仔細(xì)看各個(gè)數(shù)據(jù)集上的結(jié)果,不難看出本文提出的模型其實(shí)并不能在所有數(shù)據(jù)集多上刷出SOTA,比如COCO上遜色于DETR,SNLI-VE遜色于VisualBERT,SST-2遜色于BERT,其他數(shù)據(jù)集上都有一定的提高,但是模型卻勝在一個(gè)“全”字,模型的結(jié)構(gòu)十分清晰明了,各個(gè)板塊的作用十分明確,同時(shí)針對(duì)不同任務(wù)的處理器也對(duì)后續(xù)多模態(tài)任務(wù)富有啟發(fā)性。
原文標(biāo)題:【Transformer】沒(méi)有什么多模態(tài)任務(wù)是一層Transformer解決不了的!
文章出處:【微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
責(zé)任編輯:haq
-
編碼器
+關(guān)注
關(guān)注
45文章
3775瀏覽量
137194 -
Transforme
+關(guān)注
關(guān)注
0文章
12瀏覽量
8870 -
多模
+關(guān)注
關(guān)注
1文章
30瀏覽量
11007
原文標(biāo)題:【Transformer】沒(méi)有什么多模態(tài)任務(wù)是一層Transformer解決不了的!
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
設(shè)備預(yù)測(cè)性維護(hù)進(jìn)入2.0時(shí)代:多模態(tài)AI如何突破誤報(bào)困局

移遠(yuǎn)通信智能模組全面接入多模態(tài)AI大模型,重塑智能交互新體驗(yàn)

?多模態(tài)交互技術(shù)解析
北京大學(xué)兩部 DeepSeek 秘籍新出爐!(附全集下載)
字節(jié)跳動(dòng)發(fā)布OmniHuman 多模態(tài)框架
2025年Next Token Prediction范式會(huì)統(tǒng)一多模態(tài)嗎

【「具身智能機(jī)器人系統(tǒng)」閱讀體驗(yàn)】2.具身智能機(jī)器人大模型
商湯日日新多模態(tài)大模型權(quán)威評(píng)測(cè)第一
使用ReMEmbR實(shí)現(xiàn)機(jī)器人推理與行動(dòng)能力
未來(lái)AI大模型的發(fā)展趨勢(shì)
利用OpenVINO部署Qwen2多模態(tài)模型
云知聲山海多模態(tài)大模型UniGPT-mMed登頂MMMU測(cè)評(píng)榜首

【《大語(yǔ)言模型應(yīng)用指南》閱讀體驗(yàn)】+ 基礎(chǔ)知識(shí)學(xué)習(xí)
科普講座 | 讓AIGC提高你的專業(yè)表達(dá)和創(chuàng)作能力






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論