 深度學習在58同城首頁推薦中的應用
深度學習在58同城首頁推薦中的應用
引言
58 同城作為國內最大的生活信息服務提供商,涵蓋招聘、房產、車輛、兼職、黃頁等海量的生活分類信息。隨著各個業務線業務的蓬勃發展,用戶在網站上可獲取的分類信息是爆炸性增長的。如何解決信息過載,幫助用戶快速找到關注的信息,已經成為用戶體驗提升的關鍵點與服務的核心競爭力。
背景
目前,搜索與推薦是兩個主要手段。其中,搜索需要人工啟發屬于被動查找,而推薦可以主動推送,使得用戶查看信息這一過程更加智能化。
近幾年隨著計算機硬件性能的提升以及深度學習的快速發展,在自然語言處理、圖像處理、推薦系統等領域有了很多應用,因此實現準確、高效基于深度學習的個性化推薦,不僅能提升用戶體驗,同時也能提升平臺效率。
58 App 推薦涉及的推薦場景有首頁猜你喜歡、大類頁、詳情頁、搜索少無結果,首頁推薦場景和電商場景類似,不同的用戶同樣會有不同的興趣偏好。
比如用戶需要租房、買車,或者找工作、找保潔,針對用戶的個性化偏好產生千人千面的推薦結果;同時用戶對于相似的帖子表現為不同的興趣,比如同一車標不同的車系,這其實就是一個用戶興趣建模問題。
目前平臺已經積累了豐富的用戶行為數據,因此我們需要通過模型動態捕捉用戶的實時興趣,從而提升線上 CTR。
58 推薦系統概述
整個推薦系統架構可以分為數據算法層、業務邏輯層、對外接口層。為各類場景產生推薦數據,如圖 1 所示。
推薦過程可以概括為數據算法層通過相關召回算法根據用戶的興趣和行為歷史在海量帖子中篩選出候選集,使用相關機器學習、深度學習模型為候選帖子集合進行打分排序,進而將產生用戶感興趣并且高質量的 topN 條推薦帖子在首頁猜你喜歡、大類頁、詳情頁、少無結果等場景進行展示。
從數據算法層來看推薦的核心主要圍繞召回算法和排序模型進行,當然算法和策略同等重要,因此需通過理解業務來優化模型、策略之間的沖突。
其中排序模型的構建則是進一步影響線上用戶體驗的關鍵,本文主要圍繞深度學習在 58 首頁推薦排序上的應用展開介紹。
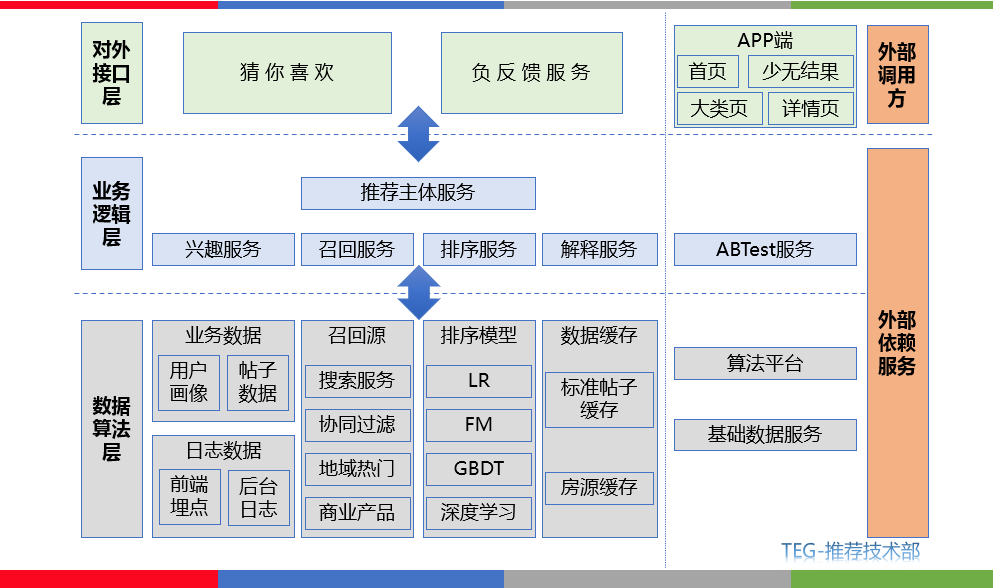
圖 1 58 推薦系統架構
首頁推薦場景位于 58 同城 App 首頁下方的推薦 tab,包含招聘、租房、二手房、二手車等多品類業務信息。
圖 2 首頁推薦場景 tab
如圖 2 可以看到左圖用戶興趣主要為租房,右圖用戶興趣為二手房、二手車、租房,這也就體現出首頁場景下多業務融合的特點。用戶在首頁推薦場景下行為特點表現為強興趣,即用戶興趣明確,但是在多業務信息融合的背景下,用戶的興趣又具有不同的周期性,以及不同的行為等,比如租房周期明顯要低于二手車成交周期,這些不同的特性對于多業務融合推薦排序任務提出了重大挑戰。
業界技術路徑
2016 年 Youtube 將 DNN[1]應用于視頻召回、推薦;Google 提出 Wide&Deep[2] 模型、為后來深度學習模型在推薦任務中的優化改進提供了基礎。58 同城 TEG - 推薦技術團隊一直緊跟技術前沿,在 58 同城各推薦場景探索并落地了一系列深度學習模型。本章節將介紹深度學習模型在推薦排序任務中的創新及經典應用,并以現有模型為基礎結合我們的業務特點進行模型選型并優化改進。
1. YouTube-DNN
DNN [1]應用場景為 YouTube App 首頁視頻推薦,通過 Word2Vec 生成用戶歷史觀看視頻以及搜索關鍵詞 Embedding,之后將歷史行為向量進行平均得到 watch vector、search vector 其他類別特征也需要進行 Embedding 最終和連續值特征拼接處理,最終作為 DNN 的輸入。
對于類別特征的 Embedding 有兩種基本處理方式,通過模型生成向量比如 Word2Vec,或者采用 Embedding 層初始化后和 DNN 一起訓練。
對于圖 3(左)召回任務,YouTube 將目標定義為用戶 next watch,通過 softmax 函數得到所有候選視頻的概率分布。對于圖 3(右)排序任務,作者在輸入特征部分除了在召回時用到的 Embedding 之外還加入了一些視頻描述特征、用戶畫像特征、用戶觀看同類視頻間隔時間、當前視頻曝光給當前用戶次數等體現二者關系的特征。
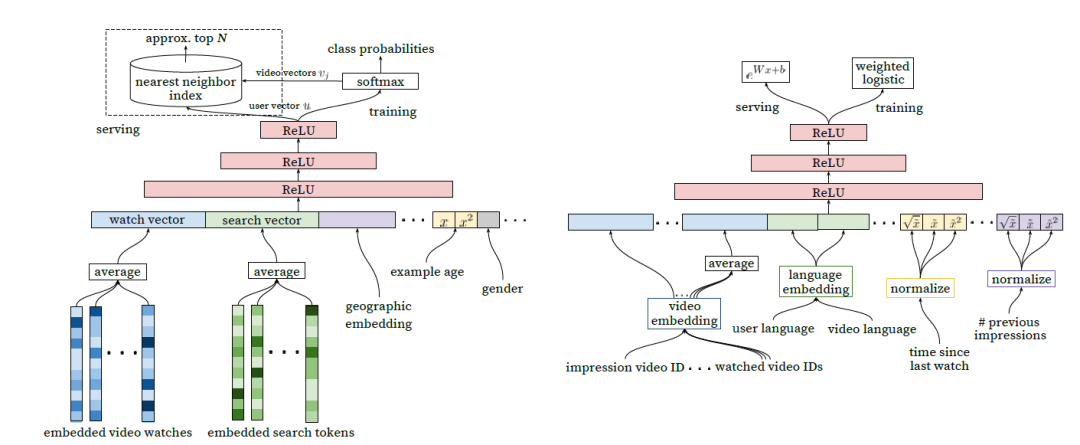
圖 3 YouTube DNN [1] 模型結構
2. Google-Wide&Deep
Wide&Deep[2]模型應用場景為 Google Play 也就是用于 App 推薦,論文強調該模型設計的目的在于具有較強的“Memorization”、“Generalization”。
文章中描述如下假設用戶安裝了 Netflix,并且該用戶之前曾查看過 pandora,計算如下組合特征 (user_installed_app=Netflix,impression_app=pandora) 和安裝 pandora 的共現頻率,假設該頻率比較高則我們希望模型發現這一規律在用戶出現這一組合特征時則推薦 pandora。
像 Logistic Regression 圖 4(左)這樣的廣義線性模型可以做到 Memorization 這一點。而對于 DNN 圖 4(右)模型則可以通過低緯稠密的 Embedding 向量學習到之前未出現的特征組合從而減少特征工程的負擔并且做到 Generalization。
最終組合之后的 Wide&Deep 圖 4(中)模型即便輸入特征是非常稀疏的,同樣可以得到較高質量的推薦結果。
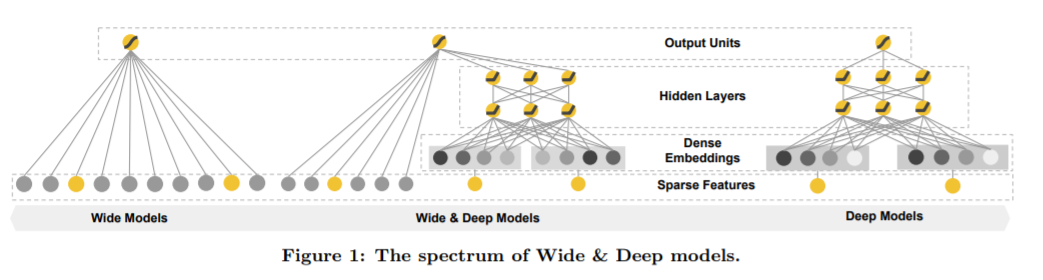
圖 4 Google Wide&Deep[2] 模型結構
3. 華為-DeepFM
DeepFM[3] 模型應用場景為華為應用商店,Wide&Deep 模型為之后兩種模型左右組合的結構改進提供了基礎。
其中圖 5 DeepFM 則是對 W&D 模型的 Wide 部分進行改進的成果,由 FM 替換 LR,原因在于 Wide 部分仍然需要繁雜的人工特征工程。通過 FM 則可以自動學習到特征之間的交叉信息,相比 W&D 模型 DeepFM 則包含了一階、二階、deep 三部分組成從而實現不同特征域之間的交叉。
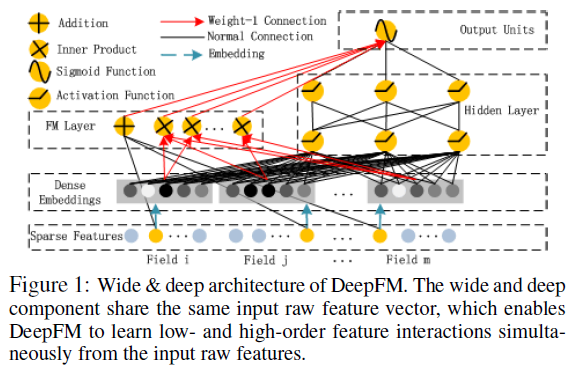
圖 5 華為 DeepFM[3] 模型結構
4. 阿里巴巴-DIN
DIN[4] 模型應用場景為阿里巴巴在線廣告推薦,考慮用戶興趣的多樣性,YouTube-DNN 模型中也利用了用戶歷史行為特征,但是將所有視頻 Embedding 進行平均,這樣就相當于是所有歷史行為對于現在的行為產生相同的影響,這樣的設計對于用戶體驗是不合常理的。因此,考慮引入 NLP 中的 Attention 機制,針對每一個歷史行為計算不同的權重。
總的來講 DIN (圖 6)模型在為當前待排序帖子預測點擊率時,對用戶歷史行為特征的注意力是不一樣的,對于相關的帖子權重更高,對于不相關的帖子權重更低。
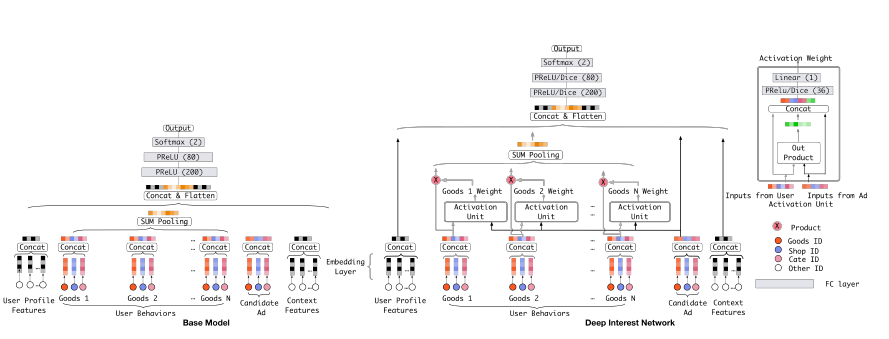
圖 6 阿里巴巴 DIN[4]模型結構
5. 阿里巴巴-DIEN
DIEN[5](圖 7)模型應用場景為阿里巴巴在線廣告推薦,該模型是對 DIN 的改進模型,主要考慮以下兩個方面,DIN 只考慮了用戶興趣的多樣性引入 Attention,但是并沒有考慮用戶興趣的動態變化。
因此引入興趣抽取層,使用 GRU 序列模型對用戶歷史行為建模、引入興趣進化層,使用 Attention、GRU 對用戶興趣衍化建模。在用戶無搜索關鍵詞的情況下捕捉用戶興趣的動態變化將是提升線上點擊率的關鍵。
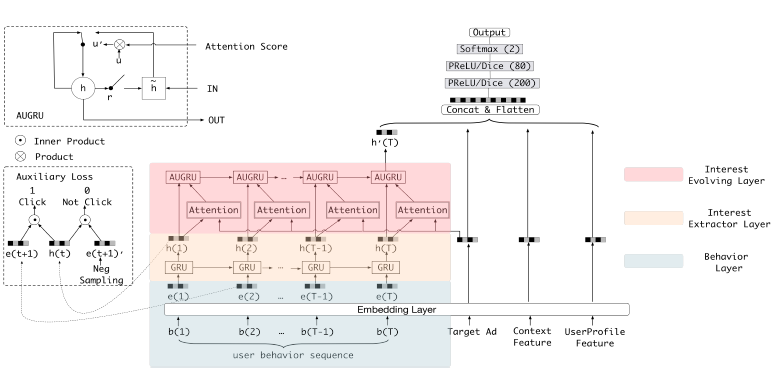
圖 7 阿里巴巴 DIEN[5] 模型結構
通過分析以上模型我們可以發現深度學習模型可以減少人工特征工程,但減少并不等同于不進行人工特征工程。
Embedding&MLP 結構將大規模稀疏數據轉化為低緯稠密特征,最終通過轉換 (Concatenate、Attention、Average) 操作,將其轉化為固定長度的向量 feed 到 MLP,學習特征間的非線性關系。
相同結構的模型在不同的業務上效果會有差異,在近幾年發表的論文中,沒有一個模型會在所有數據集上表現最優,因此需要尋找適合不同場景、不同業務的模型并加以改造。
以 DIEN 為例,由于作者考慮到用戶購買興趣在不同的時間點不同,用戶購買手機后可能需要購買手機殼等,用戶的興趣存在一個進化的過程,并且用戶的整個興趣行為需要準確、完整等。推薦的目標是為用戶展示相關信息提升平臺效率,那么就要從用戶角度考慮去構建模型,而不是單純驗證模型。
深度學習在 58 首頁推薦的應用
對于 58 同城推薦任務,深度學習模型在不同的場景中也是不通用的,即使是對同一類業務下的不同場景同樣需要定制才可以達到提升用戶體驗以及平臺收益的目的。
點擊率預估模型的目標是提升用戶線上點擊率,因此平臺為每一個用戶展示的信息以及用戶點擊或者其他行為的信息對于模型的離線訓練以及線上效果至關重要。
上文中提到的 DNN、Wide&Deep、DeepFM 模型為后來的一些深度學習模型的改進提供了基礎,這些模型我們在前幾年也進行了驗證,并且能夠達到預期效果。由于目前平臺已經積累了大量的用戶行為數據我們的目標則是通過為用戶興趣建模來提升線上點擊率,利用阿里提出的用戶興趣網絡以及用戶興趣進化網絡模型來定制模型結構對于我們的目標是有幫助的,因此我們需要根據首頁推薦場景多業務融合的特點進行改進。
本章節將展開介紹 58 首頁推薦場景下是如何以現有模型為基礎,并結合我們的業務特性來設計可以適配當前場景的模型架構。
模型
58 同城首頁推薦場景中的深度學習模型也是遵循 Embedding&MLP 結構。對于用戶行為特征,我們根據業務選擇了用戶比較敏感的三類 ID 特征,帖子 ID、類目 ID、地域 ID,通過 Attention 計算用戶歷史興趣對于待排序帖子的影響程度,通過 AUGRU 捕捉用戶興趣的動態變化。
其中用戶行為中 ID 類特征 Embedding 特征維度統一(定長,對應下圖中的 Infoid、Cateid、Localid),其他類別特征維度可根據實際業務情況進行修改(變長,對應下圖中的 category1…categoryN),除用戶行為特征外,其他類別特征、連續特征可通過配置文件進行單獨配置。
深度學習模型離線訓練、在線預估部分輸入保持一致,保證多內聚低耦合降低依賴就可以加快離線驗證迭代速度,同時可以快速遷移到線上其他場景。
結合首頁多業務融合的特點,用戶興趣網絡實現結構如圖 8 所示,特征部分包含人工業務特征、人工向量化交叉、興趣特征等。
其中 Item Embedding 是在用戶行為數據中應用 Word2Vec 得到的向量、User Embedding 則是根據 Word2Vec 向量加權得到,具體加權可使用 TF-IDF、待排序帖子與用戶歷史點擊帖子相似度等方式。
在實現模型時特征處理部分需要注意,不建議使用 tf.feature_column API,需要在特征工程部分實現處理邏輯,可減少線上推理耗時。
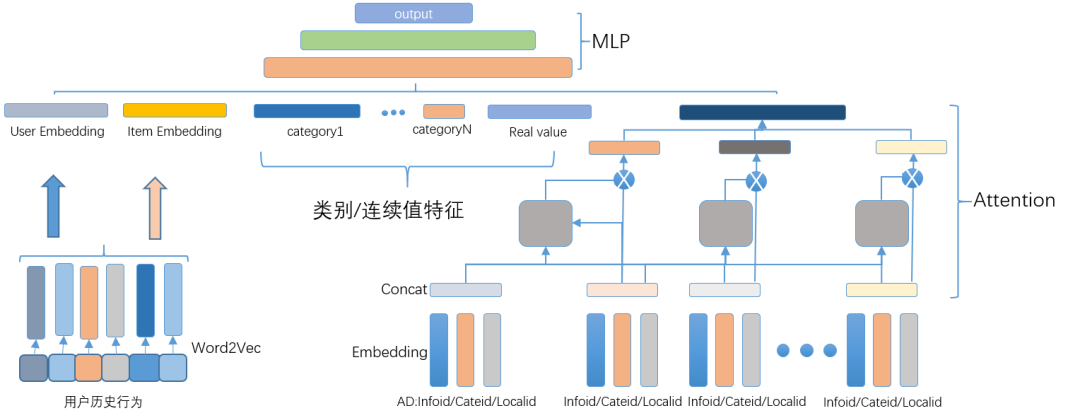
圖 8 58 首頁推薦場景下的深度學習模型結構
基礎特征
對于基礎特征部分我們分別構建了帖子特征、用戶特征以及用戶-帖子組合特征,基礎特征由于具有明顯的物理意義,可解釋性強等特點在各個業務中不容忽視,具體基礎特征可參考下表。
以租房業務中的用戶-帖子類特征為例,通過建立租房用戶對于房源的地域、價格、廳室等興趣標簽以及房源本身的地域、價格、廳室等屬性信息可以計算用戶與房源之間的相關程度。
由于 58 首頁場景為多品類推薦,部分特征對齊工作比較困難,比如用戶同時關注二手房,二手車等,那么房價以及車的價格不屬于同一空間維度,無法在傳統機器學習模型中直接使用,還有用戶興趣具有不同的周期性不同的行為等。由于這些問題的存在,我們考慮在用戶行為上進行構建特征,線上 CTR 取得進一步的提升。
| 類目 | 帖子所屬類目 |
| 地域 | 帖子所屬地域 |
| 歷史點擊次數 | 帖子歷史被點擊次數 |
| 歷史ctr | 帖子歷史點擊率 |
| Word2vec | 帖子向量 |
| 其他 | 其他帖子特征 |
| 帖子特征 | 含義 |
|---|
| 地域 | 用戶所處地域 |
| 用戶興趣 | 用戶歷史興趣特征 |
| 其他 | 其他用戶特征 |
| 用戶特征 | 含義 |
|---|
| 用戶地域-帖子地域 | 用戶所處地域與帖子所屬地域匹配度 |
| 興趣類目-帖子類目 | 用戶興趣中類目與帖子類目匹配度 |
| 興趣地域-帖子地域 | 用戶興趣中地域與帖子地域匹配度 |
| 其他 | 其他用戶-帖子特征 |
| 用戶-帖子特征 | 含義 |
|---|
離線向量化特征
2013 年 Google 開源詞向量計算工具 -Word2Vec[6],該模型通過淺層神經網絡訓練之后的詞向量可以很好的學習到詞與詞之間的相似性,并在學術界、工業界得到了廣泛應用。
這種通過低維稠密向量表示高維稀疏特征的表達方式非常適合深度學習。Embedding 思想從 NLP 領域擴散到其他機器學習、深度學習領域。與句中的詞相類似,用戶在 58 同城全站行為數據中 Item 則同樣可進行 Embedding 從而得到帖子的低緯稠密特征向量。全站行為可以指用戶的點擊行為序列,也可以指用戶的轉化行為序列。因此點擊率預估任務則可以通過 Word2Vec 得到帖子向量表示以及用戶向量表示。
Word2vec 可以根據給定的語料庫,通過優化后的訓練模型快速有效地將一個詞語表達成向量形式。Word2Vec 訓練向量一般分為 CBOW(Continuous Bag-of-Words) 與 Skip-Gram 兩種模型。CBOW 模型的訓練輸入是上下文對應的詞向量,輸出是中心詞向量,而 Skip-Gram 模型的輸入是中心詞向量,而輸出是中心詞的上下文向量。
帖子向量的訓練數據來源于用戶行為日志中抽取出的點擊曝光日志,各個業務場景下每天會出現用戶更新以及新發布的帖子,訓練帖子向量的數據使用用戶最近 7 天的點擊轉化行為數據。
針對業務對用戶行為數據進行處理,首先用戶每次點擊的停留時長小于 3s,認為是誤點擊或對當前帖子不感興趣,則將當前點擊從行為序列中剔除;保留點擊數據,去除微聊、收藏和打電話行為數據,將每條點擊數據按用戶 id 聚合并按點擊轉化時間排序;用戶行為序列中前后兩次行為超過 3 小時的認為興趣已經發生改變,對數據進行切分,生成新的行為序列。
樣本構建之后需要針對樣本需要進行負采樣,負采樣流程是對所有樣本構建一個負采樣序列,對于租房業務來說對于用戶點擊的一條位于北京房源隨機采樣到長沙的一個房源作為負樣本。
長沙的房源顯然是一條合格的負樣本,但是為了讓同城內正負樣本更具有區分性,針對負采樣流程做了以下優化,對每個詞也就是帖子記錄城市、local 信息,詞頻平滑處理,分城市對同城內的詞頻求和;拼接多個城市的負采樣序列作為最終的負采樣序列,同時記錄每個城市負采樣區間的起始和結束位置;同城內負采樣序列按照詞頻占比越高所占區間越長的規則構建,記錄當前中心詞所在點擊序列的所有出現的詞,作為正樣本,不進行負采樣;負采樣時,獲取中心詞的城市,傳入當前城市在負采樣序列中的采樣起始下標和結束下標,在當前城市區間內進行隨機取樣;負樣本的 local 不等于中心詞的 local,且負樣本沒有在中心詞的點擊序列中出現過,即成功采樣負樣本,否則繼續負采樣;對每個負樣本的采樣次數限制在 10 次之內,超過 10 次即在同城內隨機負采樣。
考慮到用戶的轉化行為也是一個更重要的行為特征,在訓練向量的過程中加入合理的正樣本使得相關的向量更相似,比如保留點擊、微聊和打電話行為數據,用戶的微聊和打電話行為相較于點擊行為有更強烈的的喜好,可用于生成正樣本;記錄序列中每個帖子的行為及對應的時間戳,遍歷當前序列,記錄微聊和打電話行為發生的時間戳以及對應帖子所在的位置下標,若中心詞位置在最近一次的微聊或打電話行為之前。
考慮到用戶的興趣在某個時間段內有連續性,將間隔時間設置在 15 分鐘之內,在這個時間范圍內的點擊可以認為對之后發生的微聊和打電話行為有間接影響,將下一次的微聊或點擊作為當前中心詞的正樣本;為了避免產生噪音數據,限制中心詞和微聊帖或打電話帖的地域信息相同或價格區間相同,滿足條件后作為正樣本進行訓練。
用戶行為特征
圖 9 用戶行為定義
58 同城全站用戶行為一般包含點擊和轉化,轉化則是指收藏、微聊、電話,圖 9 展示了租房、二手車、二手房、招聘業務中收藏、微聊/在線聊、電話、申請職位所在詳情頁的位置。
基于對用戶行為的分析以及首頁推薦場景多業務融合的特點,從用戶角度出發,考慮到用戶一般對于發布帖子本身以及帖子所在位置關注度比較高,最終將帖子 ID、類目 ID、區域 ID作為用戶行為屬性進行 Embedding 編碼。
特征的分布式表示在深度學習特征工程中至關重要,組合以上三類 ID 特征通過模型 Embedding 層獲得低緯稠密的帖子向量表示,最終可通過 Attention 或者其他相似度度量方式等計算出當前待排序帖子和用戶歷史點擊帖子的相關程度,從而使得模型學習到用戶關注點。
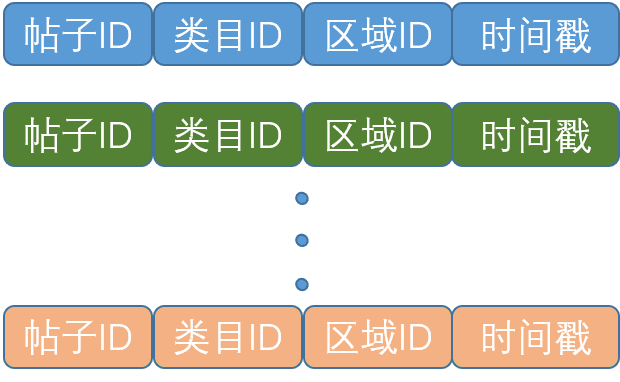
圖 10 用戶行為特征
離線用戶行為數據是將全站用戶行為特征按時間戳排序(如圖 10 所示)保存在 HDFS 中,其中單個用戶行為包含帖子 ID、類目 ID、區域 ID、時間戳等基礎信息,最終在離線訓練和在線預估中選擇使用用戶最近 N 條行為特征,通過模型將這些基礎信息進行embedding編碼。離線向量化特征則是通過用戶行為序列中的帖子 ID 序列使用 Word2vec 訓練所得。對于用戶行為中帖子 ID 的 embedding 向量可以在模型中通過 end2end 的方式訓練得到,也可以通過加載預訓練向量在模型中加載使用。
離線樣本

圖 11 樣本特征
整個離線樣本處理流程如圖 11 所示,包含用戶行為特征,基礎特征。由于訓練樣本數據數量級已達到億級別,為了加快模型離線訓練速度我們對訓練樣本采用兩種負采樣方法進行采樣:
隨機負采樣,即一次曝光的帖子列表中用戶未點擊的樣本按照自定義正負樣本比例進行采樣;
自定義采樣,即保留一次曝光帖子列表中用戶最后一次點擊之前的未點擊樣本作為負樣本。
深度學習模型要求輸入樣本不可以存在缺失值,因此需要補全策略,我們針對樣本中出現的每一種類別特征設置了一個 ID 為 0 的 Embedding 標記該特征為缺失值,對于連續特征目前將缺失值設置為 0,后期會繼續進行缺失值補全策略的實驗,比如平均值、中位數等。
離線訓練
使用離線樣本生成流程我們將所有樣本通過 MapReduce 保存在 HDFS,使用 TensorFlowDataSet 等 API 可直接讀取 HDFS 上的離線數據,對于 DNN、DIN、DIEN 模型我們實現了單機以及分布式版本,目前單機版本已在線上使用,分布式版本還在優化過程中。
模型離線訓練優化初期可通過 tensorboard 監控訓練過程中的 accuracy、loss 等指標(圖 12),通過監控可以看出模型已收斂,模型正常訓練上線之后不再使用 TensorFlow 的 summary API 可減少部分離線訓練時長。
此外,模型中如果使用到 tf.layers.batch_normalization 時應特別注意其中的 training 參數,并且在訓練過程中需要更新 moving_mean、moving_variance 參數,保存PB模型時則需要將BN層中的均值和方差保存,否則在 serving 階段取不到參數時直接使用均值為 0、方差為 1 的初始值預測,出現同一條樣本在不同的 batch 中不同打分的錯誤結果。
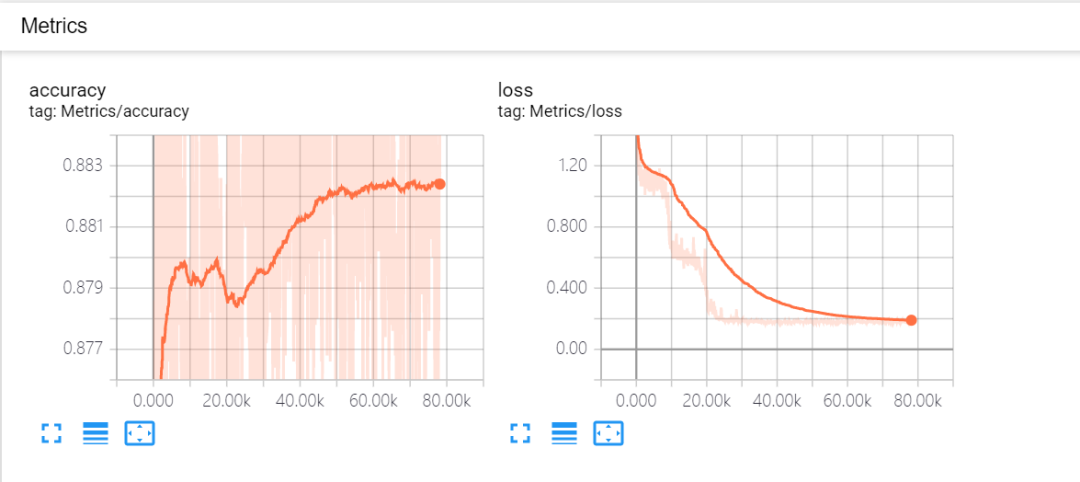
圖 12 Accuracy、Loss 變化曲線
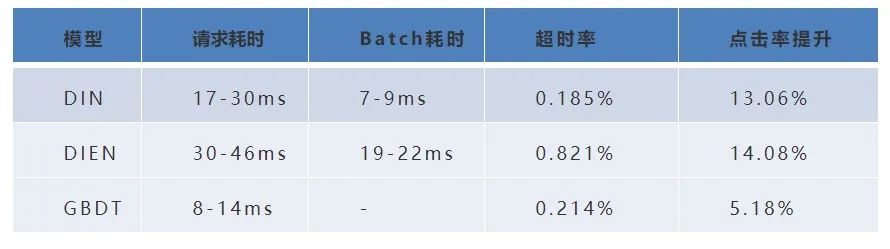
下表為 GBDT、DIN、DIEN 的離線效果,可見 DIN、DIEN 均已超過傳統機器學習模型。接下來我們將介紹線上實驗部分。
| GBDT | 0.634 |
| DIN | 0.643 |
| DIEN | 0.651 |
| 模型 | AUC |
|---|
排序服務
用戶實時行為數據構建,離線數據已經保存在 HDFS,線上則是通過實時解析 kafka 消息將用戶實時行為保存在分片 Redis 集群中,單天可產生億級別的用戶行為數據,用戶行為特征基本解析流程可參考圖 1。
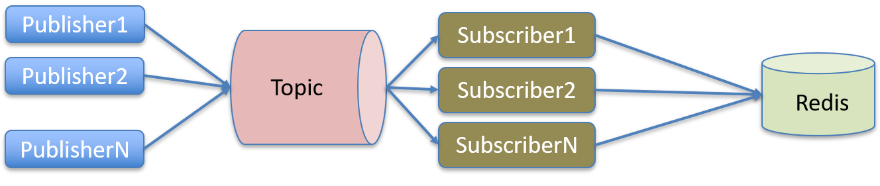
圖 13 實時用戶行為特征解析
特征抽取部分實現了帖子信息、用戶興趣、用戶行為的特征并行處理,首頁場景線上一次排序請求約 120 條帖子,為降低 TensorFlow-Serving 單節點 QPS 同時考慮單次排序請求的整體耗時,我們將一次排序請求拆分成多個 batch 并行請求深度學習模型打分服務(圖 14)。
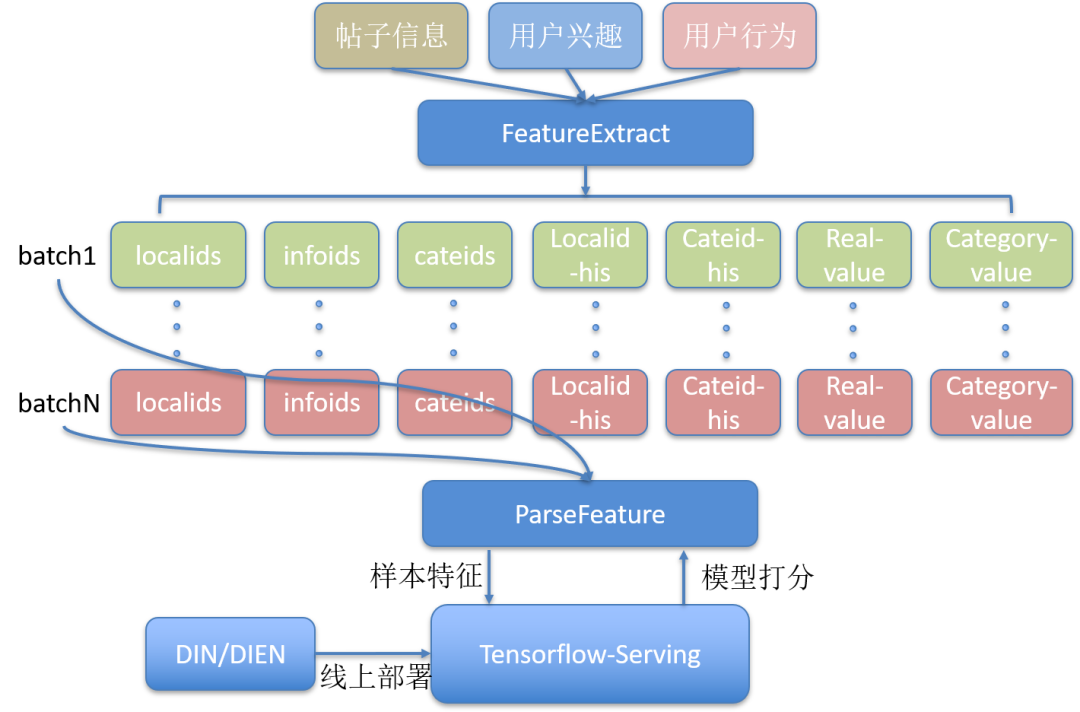
圖 14 多 Batch 請求 TensorFlow-Serving
在測試環境下我們進行了排序耗時評估,發現 batch 為 2,10,20 平均耗時差距約為 10ms,隨著 batch 增加,一次可打分帖子量增加,則 tensorflow-serving 各節點 QPS 會降低。
上線后對耗時日志進行統計,通過分析耗時統計結果(圖 15),99% 以上的請求均低于 22ms 最終權衡排序總耗時之后將線上 batch 設置為 20。
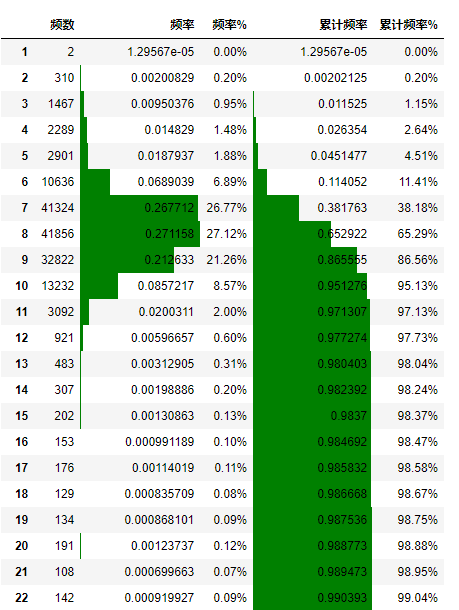
圖 15 線上單個 batch 請求耗時分布
通過線上耗時監控,DIN 模型每個 batch 平均耗時 6-9ms(圖 16 左),DIEN 每個 batch 平均耗時19-22ms(圖 16 右)均已滿足線上耗時限制。
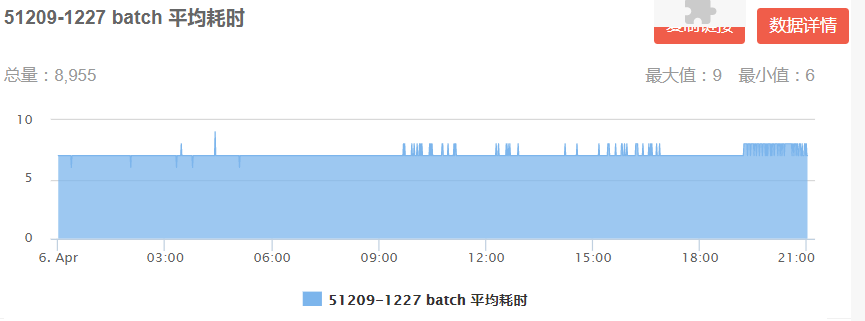
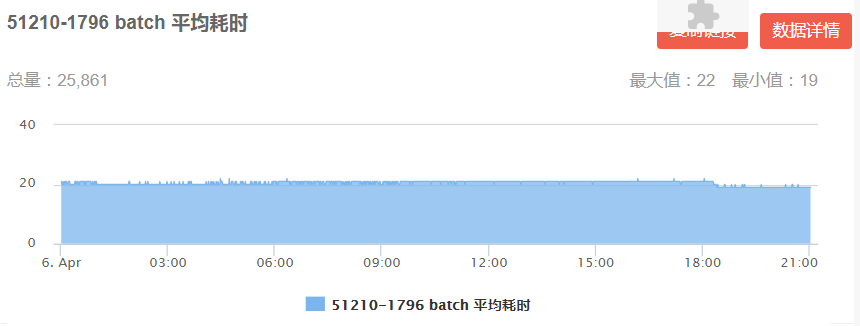
圖 16 DIN/DIEN 線上 Batch 平均耗時
首頁場景下 DIN、DIEN 模型排序實驗階段,在小流量測試階段 TensorFlow-Serving 服務 QPS 峰值可達幾千時,服務請求量及耗時量指標可參考圖 17。
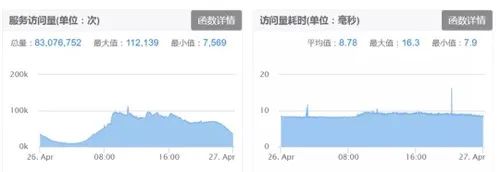
圖 17 DIN/DIEN 線上 Tensorflow-serving 請求量及耗時
實驗總結
實時/截斷用戶行為特征
模型上線之后發現離線 AUC 高于線上最優 GBDT 模型,但是線上點擊率卻低于 GBDT,排查之后定位問題出現在實時行為特征部分。
離線樣本生成過程會使用曝光時間戳去截取用戶歷史行為特征,但是線上則是通過 kafka 實時解析用戶行為,通過監控解析 kafka 寫入 Redis 發現存在部分行為數據堆積情況以及實時日志上傳 kafka 存在延遲。用戶行為數據達到 8000 萬左右(圖 18 左)時,大于兩分鐘寫入 Redis 的數據已經存在 500 萬左右(圖 18 右)。
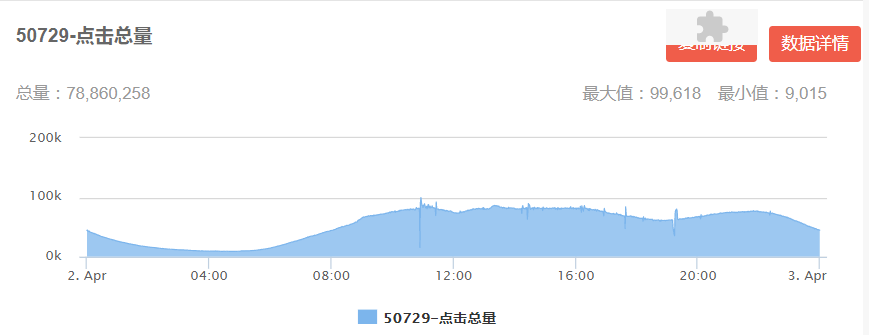
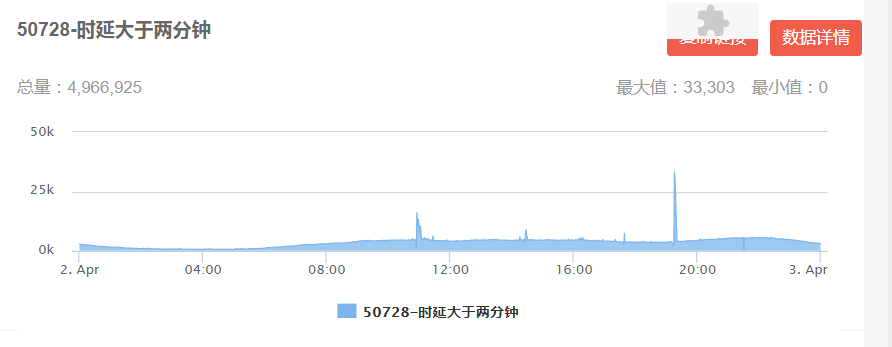
圖 18 kafka 解析用戶實時行為監控
因此通過線上監控統計后初步斷定為行為特征時間穿越問題,因此對線上線下的用戶點擊行為特征按照統計的時間進行截斷并進行線上 AB 實驗,1819(DIN)、1820(DIEN) 算法號直接讀取線上實時行為特征,1227(DIN)、1796(DIEN) 算法號則通過設置時間間隔進行截斷。
通過圖 19,20 我們可以發現線上(實驗號 1227)線下用戶行為特征進行兩分鐘截取時間后線上點擊率比通過曝光時間戳截取(實驗號 1819)有 2%-4% 的提升,1796 則比 1820 有 5%-8% 的提升。
通過線上 AB 實驗表明模型使用實時性要求比較高的用戶行為特征時對于是否存在時間穿越問題需要重點關注,當然這個問題也可以通過增加處理 kafka 的線程數來降低消息的堆積量,不過線上線下用戶行為特征是否對齊仍需要驗證。
因此用戶實時行為特征在 58 App 首頁推薦場景下需要根據實際業務數據設置時延,保證線上線下實時用戶行為特征一致。
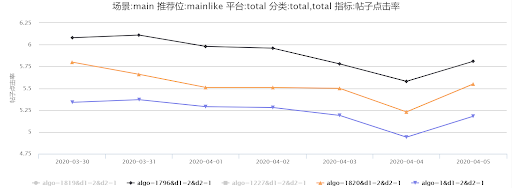
圖 19 DIEN- 驗證行為特征時間穿越
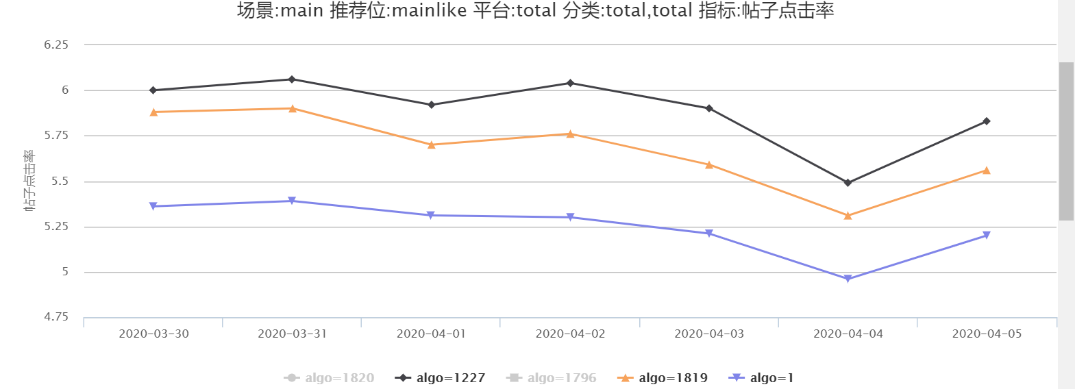
圖 20 DIN- 驗證行為特征時間穿越
使用 Word2Vec 向量
離線向量特征部分提到我們使用 Word2Vec 模型對用戶行為特征中的帖子進行離線預訓練得到了帖子的 Embedding 向量。
對于 Word2Vec 向量的使用可分為兩種,一種是離線預訓練,之后在模型 Embedding 層中用戶行為特征部分的 infoid 加載預訓練向量,一種是將預訓練的帖子向量作為連續特征直接輸入 DNN 使用,在接下來的實驗中我們優先使用第二種方式進行,后期會繼續使用第一種方法進行線上實驗。
圖 21-22 中可見對于使用 Word2Vec 向量的 1209(DIN)、1222(DIEN)比未使用 Word2Vec 向量的 1227(DIN)、1796(DIEN) 均有 1.5%-4.3% 的提升。
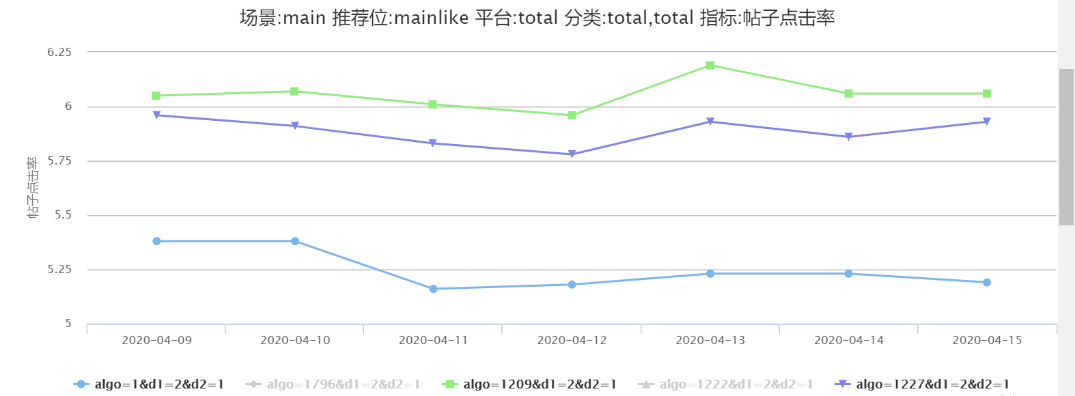
圖 21 DIN- 是否使用 Word2Vec 向量
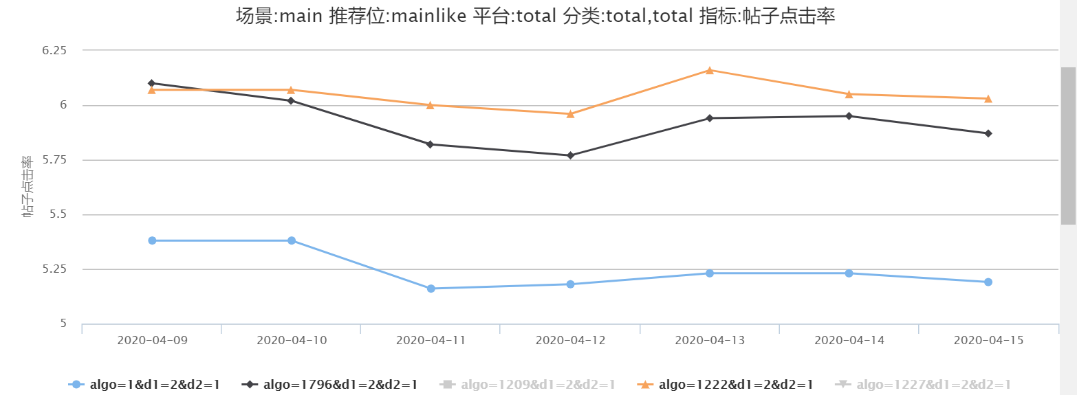
圖 22 DIEN- 是否使用 Word2Vec 向量
以上實驗為上線初期的部分數據,目前線上點擊率實驗中DIN比基線周平均提升 13.06%,曝光轉化率提升 16.16%;DIEN 相比基線曝光轉化率提升 17.32%,均已超過線上最優 GBDT 模型, DIEN 模型已全量部署,目前各模型線上指標可參考下表。
總結與展望
通過團隊協作打通基于用戶興趣相關的深度學習模型離線訓練、線上打分流程,將 58 App 中豐富的用戶行為數據成功應用到深度學習模型,并能夠提升首頁推薦點擊率,從而達到提升用戶體驗,提升平臺效率的目的。
用戶行為數據中的每一個帖子對于當前要推薦的帖子的相關程度是不一樣的,不可一概而論。注意力機制將用戶序列 Embedding 加和平均改成加權平均,使得推薦模型可以學習到用戶關注點。
用戶行為是與時間順序相關的序列,序列模型可以用來學習用戶行為的演化過程,可以用于預測用戶下一次的行為。前期的離線實驗包括目前的線上效果能夠證明通過對用戶興趣建模可以捕捉到用戶關注點以及動態的興趣變化。
目前深度學習已經在 TEG- 推薦技術團隊內部負責的各個場景進行實驗,當然還有一些待優化的事情,比如離線分布式訓練及復雜深度學習模型線上性能。
還有一些特征層面的實驗工作,比如對于用戶行為特征,不局限于帖子 id、類目 id、地域 id、用戶行為序列長度擴增等、帖子向量和用戶向量交叉等。
在模型層面,對其他 Attention 結構進行實驗、DNN 部分考慮使用殘差網絡、通過 Graph Embedding 等生成帖子向量、線上支持其他深度學習排序模型等。
責任編輯:lq
-
Google
+關注
關注
5文章
1787瀏覽量
58684 -
算法
+關注
關注
23文章
4699瀏覽量
94773 -
深度學習
+關注
關注
73文章
5554瀏覽量
122491
原文標題:社區分享 | 深度學習在 58 同城首頁推薦中的應用
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
軍事應用中深度學習的挑戰與機遇
AI自動化生產:深度學習在質量控制中的應用






 工商網監
工商網監
評論