 華人學者Nature上發表最新成果 世界最快光子AI加速器
華人學者Nature上發表最新成果 世界最快光子AI加速器

人工神經網絡廣泛應用于人臉識別、語音翻譯、醫療診斷、自動駕駛等重要領域,其性能主要由硬件算力決定,目前所廣泛應用的神經網絡硬件都基于數字電子架構。然而,該架構的兩個本質局限—馮諾曼依瓶頸與電子速率瓶頸,極大限制了神經網絡硬件的潛在算力。首先,數字架構中,數據的存儲和運算是分布式的,因而在計算過程中,會有大量的能源和算力消耗在數據的反復讀取和存儲中,此限制被稱為馮諾曼依瓶頸。其次,由于電子微處理器中的寄生電容和互聯時延問題,電子系統存在著本質的帶寬限制,導致電子微處理器的主頻事實上在過去十年已沒有明顯提升,此限制也被稱為電子速率瓶頸。
光子神經網絡工作于模擬架構中,即數據在硬件系統中的實時位置與進行運算的位置相同,因而規避了馮諾曼依瓶頸。此外,寬達數十太赫茲的光譜也為高速運算提供了充足的帶寬。目前已有來自加州大學、麻省理工學院、明斯特大學等單位的研究團隊做出了一系列在網絡尺度、可集成性、片上存儲等方面的突破,然而尚未能實現較高運算速度與高維數據處理能力,光子神經網絡的超高運算潛力尚未得到證實。
近日,澳大利亞研究人員徐興元博士(莫納什大學)、譚朦曦博士、David Moss教授(斯文本科技大學)、Arnan Mitchell教授(皇家墨爾本理工大學)等首次提出并實現了基于波長、時間交織的光子卷積加速器。該文章以“ 11 TOPS photonic convolutional accelerator for optical neural networks”為題發表在Nature。
研究人員通過采用集成高品質因素、高非線性微環與波導色散調控,實現了高相干度、易于產生的集成克爾孤子晶體光頻梳。
研究人員將該光頻梳進行頻域整形并且與高速光電調制相結合,實現了輸入數據在并行波長通道上的組播與加權,然后采用光學色散介質作為緩存,對組播信號進行了步進延時(步長為單個碼元時長),從而在時域上對齊了不同波長通道中需要加權求和的碼元,最后通過光電轉換實現處理結果的高速實時讀取(如圖1所示)。通過這一系列步驟,波長構架的卷積窗口(感知域)即可在時域以超過60GBaud的速率滑動,結合克爾光頻梳所實現的高并行度(C波段90個波長通道),實現了11 TOPS(太運算每秒)的運算速度,即每秒可完成11萬億次運算。
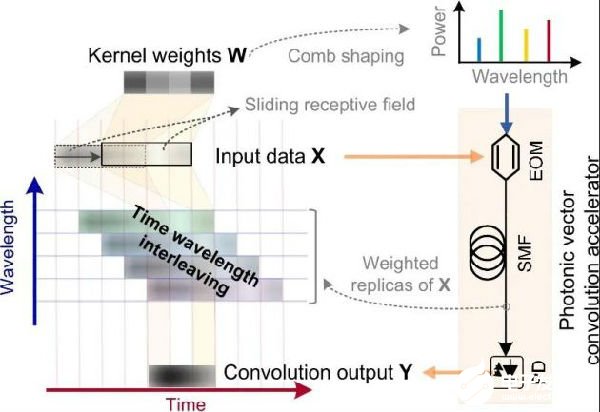
圖1 卷積加速器工作原理
圖源:Nature 589, 44–51 (2021)。 Fig 1
通過這一系列步驟,數學模型抽象的神經元突觸就被光頻梳在實際物理系統中實現,其中突觸連接的權重由光頻梳的光功率體現。最終實驗驗證了高維圖片處理(實驗結果如圖2所示)以及深度學習光子卷積神經網絡(實驗結果如圖3所示)。
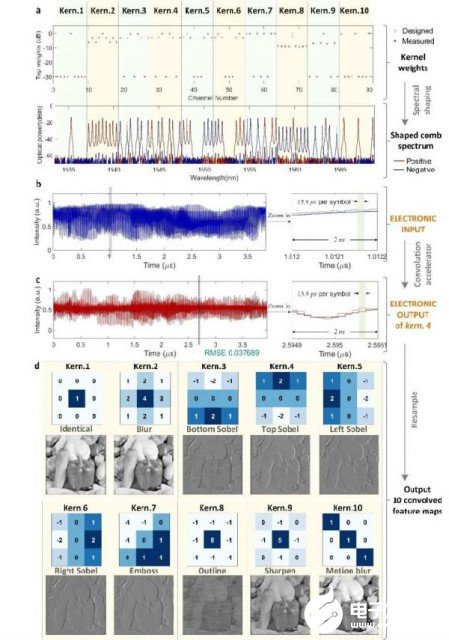
圖2 卷積圖像處理結果
圖源:Nature 589, 44–51 (2021)。 Fig 3
在國際相關研究成果的基礎上實現了數個突破,包括:
1. 由于集成克爾光頻梳所提供的大量波長通道,運算速度首次突破到11 TOPS以上;
2. 首次實現了利用光學手段進行高維數據處理(25萬像素點),為光子神經網絡的進一步實際應用如人臉識別等展現了可能;
3. 實現了500張MINIST手寫數字圖片的高速分類預測,準確率達到88%以上;
4. 實現了具備高速光電接口的硬件加速器,速度可達64G Baud以上,并且可與現有電子或者光學硬件兼容互聯;
5. 結合應用了集成克爾光頻梳,為實現光子神經網絡的單片集成奠定了基礎。
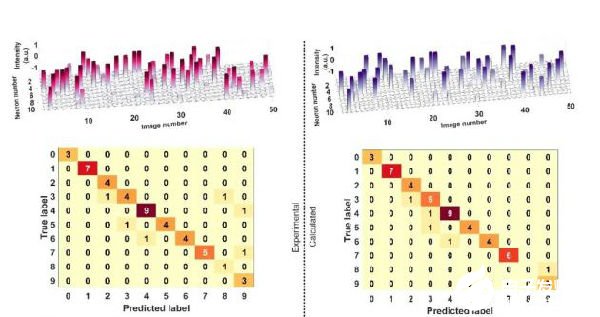
圖3 卷積神經網絡50張手寫數字識別結果。上圖為全連接層神經元輸出幅度,下圖為混淆矩陣。
圖源:Nature 589, 44–51 (2021)。 Fig 6
后續,研究人員將繼續優化本方案的性能指標,如處理速度、并行度、體積與可集成性、功耗等。本工作實驗證明了光子神經網絡硬件的運算潛力,并且具有高速光電接口,未來可作為通用卷積特征提取前端與其他光電模數架構互聯,在卷積神經網絡中可承擔70%以上的運算負荷,大幅提升系統整體算力,在未來實時人工智能應用場景如無人駕駛、醫療診斷等方面有重要應用。
責任編輯:PSY
-
晶體管
+關注
關注
77文章
10007瀏覽量
141269 -
人工智能
+關注
關注
1805文章
48936瀏覽量
248284 -
光子芯片
+關注
關注
3文章
102瀏覽量
24796 -
AI加速器
+關注
關注
1文章
70瀏覽量
9054
發布評論請先 登錄
粒子加速器?——?科技前沿的核心裝置

基于雙向塊浮點量化的大語言模型高效加速器設計
光子 AI 處理器的核心原理及突破性進展
曦智科技時隔八年再登《Nature》,光電混合計算架構首次公開

嵌入式AI加速器DRP-AI 詳細介紹
FPGA+AI王炸組合如何重塑未來世界:看看DeepSeek東方神秘力量如何預測......
消息稱AMD Instinct MI400 AI加速器將配備8個計算芯片
蘋果加入UALink聯盟,共推AI加速器新標準
英偉達AI加速器新藍圖:集成硅光子I/O,3D垂直堆疊 DRAM 內存

IBM與AMD攜手部署MI300X加速器,強化AI與HPC能力
IBM將在云平臺部署AMD加速器
英特爾發布Gaudi3 AI加速器,押注低成本優勢挑戰市場
SiFive發布MX系列高性能AI加速器IP
下一代高功能新一代AI加速器(DRP-AI3):10x在高級AI系統高級AI中更快的嵌入處理






 工商網監
工商網監
評論