 一個價值36.5萬美元的機器學習模型打了水漂?
一個價值36.5萬美元的機器學習模型打了水漂?
人們口口聲聲擔心「人工智能的推斷不可靠」,實則連個數據泄露的問題都敢忽略。
人們常會提到,當今流行的深度學習模型是黑箱狀態——給它一個輸入,模型就會決策出一個結果,其中的過程不為人所知。人們無法確切知道深度學習的決策依據以及結果是否可靠。近年來,越來越多的新研究面向構建可信的機器學習方法獲得了成果。 然而最近發生的一件事情告訴我們,很多時候被廣泛應用的機器學習模型出問題的原因,壓根就不會深入到算法層面。一點數據上的紕漏就會造成讓人啼笑皆非的結果,而且最重要的是,這樣的事比所謂「模型不可解釋」造成的損失還要多出不少。
上個星期,美國賓夕法尼亞州歷史保護官員和交通部門之間發送了大量郵件,其中內容混合了悲傷、困惑和沮喪的情緒。這一丑聞造成的影響仍在繼續,在官方做出回應之前,我們還不能了解更多情況(盡管此事在當地考古學家之間已經人盡皆知了)。 一個價值 36.5 萬美元的機器學習模型打了水漂。 發生甚么事了? 五年前,一些人帶著創意拜訪了賓州交通部,提出為史前考古遺址創建一個全州范圍預測模型。最終,政府部門選擇與一家大型工程公司合作,后者一直在考古調查方面花錢。
從合同中我們可以看到,這家公司花費了納稅人 36.59 萬美元,承諾提供一款最強大的模型,該模型還整合了 GIS(地理信息系統)疊加分析,其結果可供考古學家們使用。
從那以后直到今天,絕大多數賓夕法尼亞州交通部門的項目和所有需要進行文化資源調查的項目,在進行前都使用了這個機器學習模型的推斷結果。
從數據準備、模型選擇再到性能測試,這一項目原本看起來有模有樣,然而錯誤一旦被人揭穿,情況就變得不忍直視了。 他們將待預測區域當做負樣本 從 2013 年中到 2015 年,項目承包商花了一年半左右的時間向賓州交通部門交付了一個模型和 7 冊文檔。 不幸的是,到目前為止,似乎沒有人閱讀過該文檔。模型似乎會輸出一些毫無意義的數字,而背后原因非常神奇。
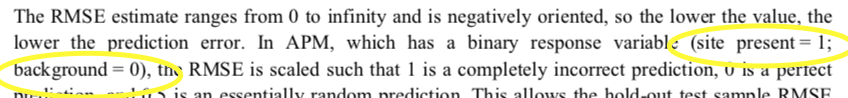
咨詢公司將未調研的土地用作負樣本數據集,但是,這些土地不就是模型將要預測的那部分嗎?一個花費了 30 多萬美元的模型,卻真實地包含了這樣的錯誤。

無論如何,在一個(混合了回歸和隨機森林的)模型中使用 null 數據都是不合適的,這些本不應該作為負樣本數據而出現。即使這些 null 數據存在于自變量中,而不是因變量,它們依舊能夠對模型的推理結果造成嚴重破壞。 他們檢查項目時沒有使用數據處理的最佳實踐 可為什么開發團隊的數據科學家們辛苦工作了一年半,也沒有意識到他們在第一步中就犯了錯?這與他們檢查項目的方式有關。 一般來說,檢查的金標準是留出一部分隨機選擇的部分。此時,只要你訓練了模型,就可以知道該模型在給到真實數據時是否 work。

顯然,在這件事中,相關研究人員未曾進行這樣的驗證。也許他們使用了一些神秘的統計方法?這就不得而知了。 他們將已知地點視為隨機采樣的結果 眾所周知,即使在一個項目區域內,也并非所有土地的采樣率都相同。僅使用鏟測試坑(Shovel Test Pit),并假設你有 100 英畝的土地,其中 50 英畝是高概率,50 英畝是低概率,并以不同的間隔(常見的有 15 米、30 米)對其進行測試。這意味著你有 80% 的測試是在高概率土地上進行的,因為你可以在一英畝土地上以 15 米的間隔進行 16 次鏟土測試,以 30 米的間隔進行約 4 次測試。因此你需要在高概率部分上找到 80% 的站點。 因此我們有一些已知的站點,這些站點并不是從隨機采樣的土地中發現的,而是從人們認為能夠找到它們的位置發現的。 直覺上,大多數考古學家都知道這一點。這很重要,因為已知的正樣本數據集的自變量分布已用于這些統計測試。這種分布是有偏置的,數據科學家不知道如何解釋這些偏置。 因此,我們需要留出一部分數據。 項目管理,沒有管理?
花費 36.5 萬美元,并不意味著簡單地讓承包商派一個人過來,在辦公室角落里搗鼓幾年,而無需他人管理。 追溯到 2014 年初,這個項目在交付給賓州交通部門的第三卷文檔中,已經犯了致命的錯誤(使用 null 數據作為負樣本數據)。難道這個項目無人監督嗎?為什么在向賓州交通部門收取數十萬美元之前,這個融合了 GIS 和機器學習的模型不值得其他人(無論是同事還是上級)關注? 交通部門盡到職責了嗎? 交付文檔之后,賓州交通部門中誰閱讀過這些文檔?作者猜測可能沒人閱讀,也沒人能理解這些文檔。不過這純粹是猜測了,我們更愿意相信文檔被讀過,只是讀地不仔細。
針對該模型中最大的錯誤而言,任何上過大學統計學課程的人都應該能夠解決這個問題。但是正如有人指出的那樣,考古學家很少學習這些數學課程,因此可能不會有考古學家來指出這些錯誤。 教訓 這一錯誤浪費了納稅人 36.5 萬美元,顯示了美國交通部門和售賣該模型的公司在質量控制方面的漫不經心,同時也表明,一些有問題的模型目前仍在某些重要的大型項目中使用。 老實說,如果想要一個預測模型,你拿出這個項目 3–5% 的經費就夠了。把模型做得簡單一點,這樣你就能自己對它進行更新、測試。即使這個模型沒有大量的質量控制問題,復雜的數學模型也不比簡單的性能要好。 揭露此事的人,Medium 博主 Archaic Inquiries 表示,他目前還在等待 SHPO 和 DOT 的回復。他特別強調,他既不在這個州工作,近期也沒有這個打算,寫這篇批評文章也沒拿到什么報酬。他的動機很簡單:看到這個模型由于缺乏監管而用于政策指導,作為一名專業人員的他為自己的領域感到尷尬。
機器學習的推斷結果出錯造成的損失有大有小,在這里可能意味著不少古人類遺跡被忽略,但最可怕的地方在于,在機器學習技術被廣泛應用的今天,這樣的錯誤其實屢見不鮮。 在社交網絡上,賓州算法事件被機器學習圈的人廣泛討論,有人表示:「我遇到的大多數數據科學家,都完全沒有意識到這種錯誤推理的問題(數據泄露),而且因為對于機器學習的無條件信任,甚至相信算法,更甚于相信自己的領域知識。」 「我認識一個政府機構的數據科學家,有很多次,我不得不向他解釋一些數據科學領域中的基本概念。我不會點明他在哪個機構,但當美國人的生命受到威脅時,它會是人們首先想要求助的那個部門。」在 Reddit 上,用戶 Stereoisomer 說道。 不知此類在技術上沒有什么解決難度的問題,以后會不會越來越少。
原文標題:模型花費幾十萬美元,五年之間指導無數項目,才發現負樣本用的是null?
文章出處:【微信公眾號:人工智能與大數據技術】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
AI
+關注
關注
87文章
34269瀏覽量
275427 -
人工智能
+關注
關注
1804文章
48723瀏覽量
246558 -
機器學習
+關注
關注
66文章
8492瀏覽量
134102 -
深度學習
+關注
關注
73文章
5554瀏覽量
122489
原文標題:模型花費幾十萬美元,五年之間指導無數項目,才發現負樣本用的是null?
文章出處:【微信號:TheBigData1024,微信公眾號:人工智能與大數據技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論