") 了解光學(xué)字符識別技術(shù)識別票據(jù)原理
了解光學(xué)字符識別技術(shù)識別票據(jù)原理

本文翻譯自dzone 中Ivan Ozhiganov 所發(fā)文章Deep Dive Into OCR for Receipt Recognition 文中版權(quán)、圖像代碼等數(shù)據(jù)均歸作者所有。為了本土化,翻譯內(nèi)容略作修改。
光學(xué)字符識別技術(shù)(OCR)目前被廣泛利用在手寫識別、打印識別及文本圖像識別等相關(guān)領(lǐng)域。小到文檔識別、銀行卡身份證識別,大到廣告、海報。因?yàn)镺CR技術(shù)的發(fā)明,極大簡化了我們處理數(shù)據(jù)的方式。
同時,機(jī)器學(xué)習(xí)(ML)和卷積神經(jīng)網(wǎng)絡(luò)(CNN)的快速發(fā)展也讓文本識別出現(xiàn)了巨大的飛躍!我們在本文的研究中也將使用卷積神經(jīng)網(wǎng)絡(luò)CNN技術(shù)來識別零售店的紙質(zhì)票據(jù)。為了方便演示,我們本次將僅采用俄語版的票據(jù)進(jìn)行測試。
我們的目標(biāo)是項(xiàng)目開發(fā)一個客戶端來識別來獲取相關(guān)文檔,在有服務(wù)器端去識別解析數(shù)據(jù)。準(zhǔn)備好了嗎?讓我們一起去看看怎么做吧!
預(yù)處理
首先,我們需要接收圖像相關(guān)數(shù)據(jù),使其水平豎直方向垂直,接下來使用算法進(jìn)行檢測是否為票據(jù),最終二值化方便識別。
旋轉(zhuǎn)圖像識別收據(jù)
我們有三種方案來識別票據(jù),下文對這三種方案做了測試。
1. 高閾值的自適應(yīng)二值化技術(shù)。2. 卷積神經(jīng)網(wǎng)絡(luò)(CNN)。3. Haar特征分類器。
自適應(yīng)二值化技術(shù)
首先,我們看到,圖中圖像上包含了完整的數(shù)據(jù),同時票據(jù)又與背景有些差距。為了能更好識別相關(guān)數(shù)據(jù),我們需要將圖片進(jìn)行旋轉(zhuǎn)。使其水平沿豎直方向?qū)R。
我們使用Opencv中的自適應(yīng)閾值化函數(shù)adaptive_threshold和scikit-image框架來調(diào)整收據(jù)數(shù)據(jù)。利用這兩項(xiàng)函數(shù),我們可以在高梯度區(qū)域保留白色像素,低梯度區(qū)域保留黑色像素。這使得我們獲得了一個高反差的樣本圖片。這樣,通過裁剪,我們就能得到票據(jù)的相關(guān)信息了。
使用卷積神經(jīng)網(wǎng)絡(luò)(CNN)
起初我們決定使用CNN來做相關(guān)位置檢測的接收點(diǎn),就像我們之前做對象檢測項(xiàng)目一樣。我們使用判斷角度來拾取相關(guān)關(guān)鍵點(diǎn)。這種方案雖然好用,但是和高閾值對比檢測裁剪更差。
因?yàn)镃NN只能找到文本的角度坐標(biāo),而文字的角度變化很大,這就意味著CNN模型不是很精準(zhǔn)。詳情請參考下面CNN測試的結(jié)果。
使用Haar特征分類器來識別收據(jù)
作為第三種選擇,我們嘗試使用Haar特征分類器來做分類篩選。然而經(jīng)過一周的分類訓(xùn)練和改變相關(guān)參數(shù),我們并沒有得到什么比較積極的結(jié)果,甚至發(fā)現(xiàn)CNN都比Haar表現(xiàn)好得多。
二值化
最終我們使用opencv中的adaptive_threshold方法進(jìn)行二值化,經(jīng)過二值化處理,我們得到了一個不錯的圖片。
文本檢測
接下來我們來介紹幾個不同的文本檢測組件。
通過鏈接組件檢測文本
首先,我們使用Opencv中的find Contours函數(shù)找到鏈接的文本組。大多數(shù)鏈接的組件是字符,但是也有二值化留下來嘈雜的文本,這里我們通過設(shè)置閾值的大小來過濾相關(guān)文本。
然后,我們執(zhí)行合成算法來合成字符,如:Й和=。通過搜索最臨近的字符組合合成單詞。這種算法需要你找到每個相關(guān)字字母最臨近的字符,然后從若干字母中找到最佳選擇展示。
接下來文字形成文字行。我們通過判斷文字是否高度一致來判斷文本是否屬于同一行。
當(dāng)然,這個方案的缺點(diǎn)是不能識別有噪聲的文本。
使用網(wǎng)格對文本進(jìn)行檢測
我們發(fā)現(xiàn)幾乎所有票據(jù)都是相同寬度的文本,所以我們設(shè)法在收據(jù)上畫出一個網(wǎng)格,并利用網(wǎng)格分割每個字符:
網(wǎng)格一下子精簡了票據(jù)識別的難度。神經(jīng)網(wǎng)絡(luò)可以精準(zhǔn)識別每個網(wǎng)格內(nèi)的字符。這樣就解決了文本嘈雜的情況。最終可以精確統(tǒng)計文本數(shù)量。
我們使用了以下算法來識別網(wǎng)格。
首先,我在二值化鏡像中使用這個連接組件算法。
然后我們發(fā)現(xiàn)圖中左下角有些是真,所喲我們通過二維周期函數(shù)來調(diào)整網(wǎng)格識別。
修正網(wǎng)格失真背后主要的思想是利用圖形峰值點(diǎn)找到非線性幾何失真,換句話說,我們必須找到這個函數(shù)的最大值的和。另外,我們還需要一個最佳失真值才行。
我們使用ScipyPython模塊中的RectBivariateSpline函數(shù)來參數(shù)化幾何失真。并用Scipy函數(shù)進(jìn)行優(yōu)化。得到如下結(jié)果:

總而言之,這個方法緩慢且不穩(wěn)定,所以堅決不打算使用這個方案。
光學(xué)字符識別
我們通過組連接識別發(fā)現(xiàn)文本,并識別完整的單詞。
識別通過連接組發(fā)現(xiàn)的文本
對于文本識別,我們使用卷積神經(jīng)網(wǎng)絡(luò)(CNN)接收相關(guān)字體進(jìn)行培訓(xùn)。輸出部分,我們通過對比來提升概率。我們那個幾個最初的幾個選項(xiàng)多對比,發(fā)現(xiàn)有99%的準(zhǔn)確識別率后。又通過對比字典來提高準(zhǔn)確度,并消除相關(guān)類似的字符,如"З" 和 "Э"造成的錯誤。
然而,當(dāng)涉及嘈雜的文本時,該方法性能卻十分低下。
識別完整的單詞
當(dāng)文本太嘈雜的時候,需要找到完整的單詞才能進(jìn)行單個字母的識別。我們使用下面兩個方法來解決這個問題:
LSTM網(wǎng)絡(luò)
圖像非均勻分割技術(shù)
LSTM網(wǎng)絡(luò)
您可以閱讀這些文章,以更加深入了解使用卷積神經(jīng)網(wǎng)絡(luò)識別序列中的文本 ,或我們可以使用神經(jīng)網(wǎng)絡(luò)建立與語言無關(guān)的OCR嗎?為此,我們使用了OCRopus庫來進(jìn)行識別。
我們使用了等寬的字體來作為人工識別樣本進(jìn)行訓(xùn)練。
訓(xùn)練結(jié)束后,我們由利用其他數(shù)據(jù)來測試我們的神經(jīng)網(wǎng)絡(luò),當(dāng)然,測試結(jié)果非常積極。這是我們得到的數(shù)據(jù):
訓(xùn)練好的神經(jīng)網(wǎng)絡(luò)在簡單的例子上表現(xiàn)十分優(yōu)秀。同樣,我們也識別到了網(wǎng)格不適合的復(fù)雜情況。
我們抽取的相關(guān)的訓(xùn)練樣本,并讓他通過神經(jīng)網(wǎng)絡(luò)進(jìn)行訓(xùn)練。
為了避免神經(jīng)網(wǎng)絡(luò)過度擬合,我們多次停止并修正訓(xùn)練結(jié)果,并不斷加入新數(shù)據(jù)作為訓(xùn)練樣本。最后我們得到以下結(jié)果:

新的網(wǎng)絡(luò)擅長識別復(fù)雜的詞匯,但是簡單的文字識別卻并不好。
我們覺得這個卷積神經(jīng)網(wǎng)絡(luò)可以細(xì)化識別單個字符來使文本識別更加優(yōu)秀。
圖像非均勻分割技術(shù)
因?yàn)槭論?jù)字體是等寬的字體,所以我們決定按照字符分割字體。首先,我們需要知道每個字母的寬度。因此,字符的寬度尤為重要,我們需要估計每個字母的長度,利用函數(shù),我們得到下圖。選擇多種模式來選取特定的字母寬度。
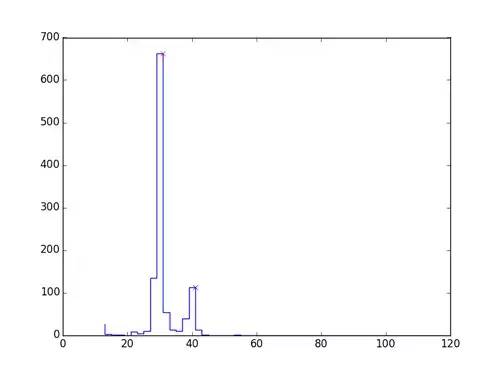
我們得到一個單詞的近似寬度,通過除以字符中的字母數(shù),給出一個近似分類:
區(qū)分最佳的是:
這種分割方案的準(zhǔn)確度是非常高的:
當(dāng)然,也有識別不太好的情況:
分割后我們在使用CNN做識別處理。
從收據(jù)中提取含義
我們使用正則表達(dá)式來查找收據(jù)中購買情況。所有收據(jù)都有一個共通點(diǎn):購買價格以XX.XX格式來撰寫。因此,可以通過提取購買的行來提取相關(guān)信息。個人納稅號碼是十位數(shù),也可以通過正則表達(dá)式輕松獲取。同樣,也可以通過正則表達(dá)式找到NAME / SURNAME等信息。
總結(jié)
不論你選擇什么方法,LSTM或者其他更加復(fù)雜的方案,都沒有錯誤,有些方法很難用,但是有些方法卻很簡單,因識別樣本而異。
我們將繼續(xù)優(yōu)化這個項(xiàng)目。目前來看,在沒有噪聲的情況下,系統(tǒng)性能更加優(yōu)秀。
原文鏈接:https://dzone.com/articles/using-ocr-for-receipt-recognition
責(zé)任編輯:xj
原文標(biāo)題:深入淺出了解OCR識別票據(jù)原理
文章出處:【微信公眾號:新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
OCR
+關(guān)注
關(guān)注
0文章
161瀏覽量
16788 -
識別
+關(guān)注
關(guān)注
3文章
173瀏覽量
32251
原文標(biāo)題:深入淺出了解OCR識別票據(jù)原理
文章出處:【微信號:vision263com,微信公眾號:新機(jī)器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
即插即用、缺陷同檢,維視智造推出讀碼/字符檢測視覺系統(tǒng)新品

OCR技術(shù)如何實(shí)現(xiàn)鐵路集裝箱號的自動識別?
大模型預(yù)標(biāo)注和自動化標(biāo)注在OCR標(biāo)注場景的應(yīng)用
手持終端集裝箱識別系統(tǒng)的圖像識別技術(shù)
阿普奇視覺控制器AK7在OCR識別場景中的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論