") Linux網(wǎng)絡(luò)包接收過程的監(jiān)控與調(diào)優(yōu)
Linux網(wǎng)絡(luò)包接收過程的監(jiān)控與調(diào)優(yōu)
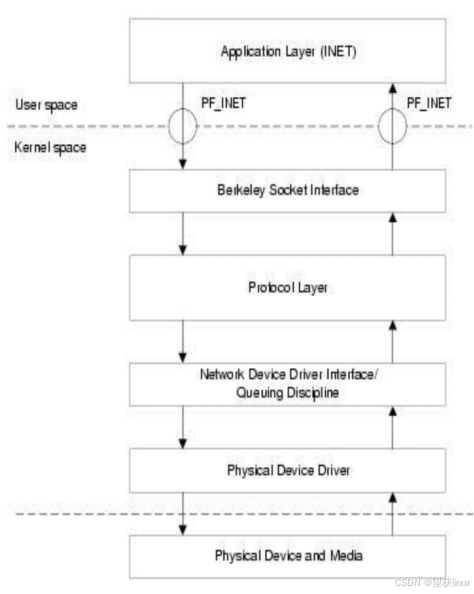
上一篇文章中《圖解Linux網(wǎng)絡(luò)包接收過程》,我們梳理了在Linux系統(tǒng)下一個數(shù)據(jù)包被接收的整個過程。Linux內(nèi)核對網(wǎng)絡(luò)包的接收過程大致可以分為接收到RingBuffer、硬中斷處理、ksoftirqd軟中斷處理幾個過程。其中在ksoftirqd軟中斷處理中,把數(shù)據(jù)包從RingBuffer中摘下來,送到協(xié)議棧的處理,再之后送到用戶進程socket的接收隊列中。
圖1 Linux內(nèi)核接收網(wǎng)絡(luò)包過程 理解了Linux工作原理之后,還有更重要的兩件事情。第一是動手監(jiān)控,會實際查看網(wǎng)絡(luò)包接收的整體情況。第二是調(diào)優(yōu),當(dāng)你的服務(wù)器有問題的時候,你能找到瓶頸所在,并會利用內(nèi)核開放的參數(shù)進行調(diào)節(jié)。 一 先說幾個工具
在正式內(nèi)容開始之前,我們先來了解幾個Linux下監(jiān)控網(wǎng)卡時可用的工具。
1)ethtool
首先第一個工具就是我們在上文中提到的ethtool,它用來查看和設(shè)置網(wǎng)卡參數(shù)。這個工具其實本身只是提供幾個通用接口,真正的實現(xiàn)是都是在網(wǎng)卡驅(qū)動中的。正因為該工具是由驅(qū)動直接實現(xiàn)的,所以個人覺得它最重要。
該命令比較復(fù)雜,我們選幾個今天能用到的說
-i顯示網(wǎng)卡驅(qū)動的信息,如驅(qū)動的名稱、版本等
-S查看網(wǎng)卡收發(fā)包的統(tǒng)計情況
-g/-G查看或者修改RingBuffer的大小
-l/-L查看或者修改網(wǎng)卡隊列數(shù)
-c/-C查看或者修改硬中斷合并策略
實際查看一下網(wǎng)卡驅(qū)動:
# ethtool -i eth0 driver: ixgbe ......這里看到我的機器上網(wǎng)卡驅(qū)動程序是ixgbe。有了驅(qū)動名稱,就可以在源碼中找到對應(yīng)的代碼了。對于ixgbe來說,其驅(qū)動的源代碼位于drivers/net/ethernet/intel/ixgbe目錄下。ixgbe_ethtool.c`下都是實現(xiàn)的供ethtool使用的相關(guān)函數(shù),如果ethtool哪里有搞不明白的,就可以通過這種方式查找到源碼來讀。另外我們前文《圖解Linux網(wǎng)絡(luò)包接收過程》里提到的NAPI收包時的poll回調(diào)函數(shù),啟動網(wǎng)卡時的open函數(shù)都是在這里實現(xiàn)的。
2)ifconfig
網(wǎng)絡(luò)管理工具ifconfig不只是可以為網(wǎng)卡配置ip,啟動或者禁用網(wǎng)卡,也包含了一些網(wǎng)卡的統(tǒng)計信息。
eth0: flags=4163
RX packets:接收的總包數(shù)
RX bytes:接收的字節(jié)數(shù)
RX errors:表示總的收包的錯誤數(shù)量
RX dropped:數(shù)據(jù)包已經(jīng)進入了 Ring Buffer,但是由于其它原因?qū)е碌膩G包
RX overruns:表示了 fifo 的 overruns,這是由于 Ring Buffer不足導(dǎo)致的丟包
3)偽文件系統(tǒng)/proc
Linux 內(nèi)核提供了 /proc 偽文件系統(tǒng),通過/proc可以查看內(nèi)核內(nèi)部數(shù)據(jù)結(jié)構(gòu)、改變內(nèi)核設(shè)置。我們先跑一下題,看一下這個偽文件系統(tǒng)里都有啥:
/proc/sys目錄可以查看或修改內(nèi)核參數(shù)
/proc/cpuinfo可以查看CPU信息
/proc/meminfo可以查看內(nèi)存信息
/proc/interrupts統(tǒng)計所有的硬中斷
/proc/softirqs統(tǒng)計的所有的軟中斷信息
/proc/slabinfo統(tǒng)計了內(nèi)核數(shù)據(jù)結(jié)構(gòu)的slab內(nèi)存使用情況
/proc/net/dev可以看到一些網(wǎng)卡統(tǒng)計數(shù)據(jù)
詳細聊下偽文件/proc/net/dev,通過它可以看到內(nèi)核中對網(wǎng)卡的一些相關(guān)統(tǒng)計。包含了以下信息:
bytes: 發(fā)送或接收的數(shù)據(jù)的總字節(jié)數(shù)
packets: 接口發(fā)送或接收的數(shù)據(jù)包總數(shù)
errs: 由設(shè)備驅(qū)動程序檢測到的發(fā)送或接收錯誤的總數(shù)
drop: 設(shè)備驅(qū)動程序丟棄的數(shù)據(jù)包總數(shù)
fifo: FIFO緩沖區(qū)錯誤的數(shù)量
frame: The number of packet framing errors.(分組幀錯誤的數(shù)量)
colls: 接口上檢測到的沖突數(shù)
所以,偽文件/proc/net/dev也可以作為我們查看網(wǎng)卡工作統(tǒng)計數(shù)據(jù)的工具之一。
4)偽文件系統(tǒng)sysfs
sysfs和/proc類似,也是一個偽文件系統(tǒng),但是比proc更新,結(jié)構(gòu)更清晰。其中的/sys/class/net/eth0/statistics/也包含了網(wǎng)卡的統(tǒng)計信息。
# cd /sys/class/net/eth0/statistics/ # grep . * | grep tx tx_aborted_errors:0 tx_bytes:170699510 tx_carrier_errors:0 tx_compressed:0 tx_dropped:0 tx_errors:0 tx_fifo_errors:0 tx_heartbeat_errors:0 tx_packets:262330 tx_window_errors:0
好了,簡單了解過這幾個工具以后,讓我們正式開始今天的行程。
二 RingBuffer監(jiān)控與調(diào)優(yōu)
前面我們看到,當(dāng)網(wǎng)線中的數(shù)據(jù)幀到達網(wǎng)卡后,第一站就是RingBuffer(網(wǎng)卡通過DMA機制將數(shù)據(jù)幀送到RingBuffer中)。因此我們第一個要監(jiān)控和調(diào)優(yōu)的就是網(wǎng)卡的RingBuffer,我們使用ethtool來查看一下:
# ethtool -g eth0 Ring parameters for eth0: Pre-set maximums: RX: 4096 RX Mini: 0 RX Jumbo: 0 TX: 4096 Current hardware settings: RX: 512 RX Mini: 0 RX Jumbo: 0 TX: 512
這里看到我手頭的網(wǎng)卡設(shè)置RingBuffer最大允許設(shè)置到4096,目前的實際設(shè)置是512。
這里有一個小細節(jié),ethtool查看到的是實際是Rx bd的大小。Rx bd位于網(wǎng)卡中,相當(dāng)于一個指針。RingBuffer在內(nèi)存中,Rx bd指向RingBuffer。Rx bd和RingBuffer中的元素是一一對應(yīng)的關(guān)系。在網(wǎng)卡啟動的時候,內(nèi)核會為網(wǎng)卡的Rx bd在內(nèi)存中分配RingBuffer,并設(shè)置好對應(yīng)關(guān)系。
在Linux的整個網(wǎng)絡(luò)棧中,RingBuffer起到一個任務(wù)的收發(fā)中轉(zhuǎn)站的角色。對于接收過程來講,網(wǎng)卡負責(zé)往RingBuffer中寫入收到的數(shù)據(jù)幀,ksoftirqd內(nèi)核線程負責(zé)從中取走處理。只要ksoftirqd線程工作的足夠快,RingBuffer這個中轉(zhuǎn)站就不會出現(xiàn)問題。但是我們設(shè)想一下,假如某一時刻,瞬間來了特別多的包,而ksoftirqd處理不過來了,會發(fā)生什么?這時RingBuffer可能瞬間就被填滿了,后面再來的包網(wǎng)卡直接就會丟棄,不做任何處理!
那我們怎么樣能看一下,我們的服務(wù)器上是否有因為這個原因?qū)е碌膩G包呢?前面我們介紹的四個工具都可以查看這個丟包統(tǒng)計,拿ethtool來舉例:
# ethtool -S eth0 ...... rx_fifo_errors: 0 tx_fifo_errors: 0
rx_fifo_errors如果不為0的話(在 ifconfig 中體現(xiàn)為 overruns 指標增長),就表示有包因為RingBuffer裝不下而被丟棄了。那么怎么解決這個問題呢?很自然首先我們想到的是,加大RingBuffer這個“中轉(zhuǎn)倉庫”的大小。通過ethtool就可以修改。
# ethtool -G eth1 rx 4096 tx 4096
這樣網(wǎng)卡會被分配更大一點的”中轉(zhuǎn)站“,可以解決偶發(fā)的瞬時的丟包。不過這種方法有個小副作用,那就是排隊的包過多會增加處理網(wǎng)絡(luò)包的延時。所以另外一種解決思路更好,那就是讓內(nèi)核處理網(wǎng)絡(luò)包的速度更快一些,而不是讓網(wǎng)絡(luò)包傻傻地在RingBuffer中排隊。怎么加快內(nèi)核消費RingBuffer中任務(wù)的速度呢,別著急,我們繼續(xù)往下看...
三 硬中斷監(jiān)控與調(diào)優(yōu)
在數(shù)據(jù)被接收到RingBuffer之后,下一個執(zhí)行就是就是硬中斷的發(fā)起。我們先來查看硬中斷,然后再聊下怎么優(yōu)化。
1)監(jiān)控
硬中斷的情況可以通過內(nèi)核提供的偽文件/proc/interrupts來進行查看。
$ cat /proc/interrupts CPU0 CPU1 CPU2 CPU3 0: 34 0 0 0 IO-APIC-edge timer ...... 27: 351 0 0 1109986815 PCI-MSI-edge virtio1-input.0 28: 2571 0 0 0 PCI-MSI-edge virtio1-output.0 29: 0 0 0 0 PCI-MSI-edge virtio2-config 30: 4233459 1986139461 244872 474097 PCI-MSI-edge virtio2-input.0 31: 3 0 2 0 PCI-MSI-edge virtio2-output.0
上述結(jié)果是我手頭的一臺虛機的輸出結(jié)果。上面包含了非常豐富的信息,讓我們一一道來:
網(wǎng)卡的輸入隊列virtio1-input.0的中斷號是27
27號中斷都是由CPU3來處理的
總的中斷次數(shù)是1109986815。
這里有兩個細節(jié)我們需要關(guān)注一下。
(1)為什么輸入隊列的中斷都在CPU3上呢?
這是因為內(nèi)核的一個配置,在偽文件系統(tǒng)中可以查看到。
#cat /proc/irq/27/smp_affinity 8
smp_affinity里是CPU的親和性的綁定,8是二進制的1000,第4位為1,代表的就是第4個CPU核心-CPU3.
(2)對于收包來過程來講,硬中斷的總次數(shù)表示的是Linux收包總數(shù)嗎?
不是,硬件中斷次數(shù)不代表總的網(wǎng)絡(luò)包數(shù)。第一網(wǎng)卡可以設(shè)置中斷合并,多個網(wǎng)絡(luò)幀可以只發(fā)起一次中斷。第二NAPI 運行的時候會關(guān)閉硬中斷,通過poll來收包。
2)多隊列網(wǎng)卡調(diào)優(yōu)
現(xiàn)在的主流網(wǎng)卡基本上都是支持多隊列的,我們可以通過將不同的隊列分給不同的CPU核心來處理,從而加快Linux內(nèi)核處理網(wǎng)絡(luò)包的速度。這是最為有用的一個優(yōu)化手段。
每一個隊列都有一個中斷號,可以獨立向某個CPU核心發(fā)起硬中斷請求,讓CPU來poll包。通過將接收進來的包被放到不同的內(nèi)存隊列里,多個CPU就可以同時分別向不同的隊列發(fā)起消費了。這個特性叫做RSS(Receive Side Scaling,接收端擴展)。通過ethtool工具可以查看網(wǎng)卡的隊列情況。
# ethtool -l eth0 Channel parameters for eth0: Pre-set maximums: RX: 0 TX: 0 Other: 1 Combined: 63 Current hardware settings: RX: 0 TX: 0 Other: 1 Combined: 8
上述結(jié)果表示當(dāng)前網(wǎng)卡支持的最大隊列數(shù)是63,當(dāng)前開啟的隊列數(shù)是8。對于這個配置來講,最多同時可以有8個核心來參與網(wǎng)絡(luò)收包。如果你想提高內(nèi)核收包的能力,直接簡單加大隊列數(shù)就可以了,這比加大RingBuffer更為有用。因為加大RingBuffer只是給個更大的空間讓網(wǎng)絡(luò)幀能繼續(xù)排隊,而加大隊列數(shù)則能讓包更早地被內(nèi)核處理。ethtool修改隊列數(shù)量方法如下:
#ethtool -L eth0 combined 32
我們前文說過,硬中斷發(fā)生在哪一個核上,它發(fā)出的軟中斷就由哪個核來處理。所有通過加大網(wǎng)卡隊列數(shù),這樣硬中斷工作、軟中斷工作都會有更多的核心參與進來。
每一個隊列都有一個中斷號,每一個中斷號都是綁定在一個特定的CPU上的。如果你不滿意某一個中斷的CPU綁定,可以通過修改/proc/irq/{中斷號}/smp_affinity來實現(xiàn)。
一般處理到這里,網(wǎng)絡(luò)包的接收就沒有大問題了。但如果你有更高的追求,或者是說你并沒有更多的CPU核心可以參與進來了,那怎么辦?放心,我們也還有方法提高單核的處理網(wǎng)絡(luò)包的接收速度。
3)硬中斷合并
先來講一個實際中的例子,假如你是一位開發(fā)同學(xué),和你對口的產(chǎn)品經(jīng)理一天有10個小需求需要讓你幫忙來處理。她對你有兩種中斷方式:
第一種:產(chǎn)品經(jīng)理想到一個需求,就過來找你,和你描述需求細節(jié),然后讓你幫你來改
第二種:產(chǎn)品經(jīng)理想到需求后,不來打擾你,等攢夠5個來找你一次,你集中處理
我們現(xiàn)在不考慮及時性,只考慮你的工作整體效率,你覺得那種方案下你的工作效率會高呢?或者換句話說,你更喜歡哪一種工作狀態(tài)呢?很明顯,只要你是一個正常的開發(fā),都會覺得第二種方案更好。對人腦來講,頻繁的中斷會打亂你的計劃,你腦子里剛才剛想到一半技術(shù)方案可能也就廢了。當(dāng)產(chǎn)品經(jīng)理走了以后,你再想撿起來剛被中斷之的工作的時候,很可能得花點時間回憶一會兒才能繼續(xù)工作。
對于CPU來講也是一樣,CPU要做一件新的事情之前,要加載該進程的地址空間,load進程代碼,讀取進程數(shù)據(jù),各級別cache要慢慢熱身。因此如果能適當(dāng)降低中斷的頻率,多攢幾個包一起發(fā)出中斷,對提升CPU的工作效率是有幫助的。所以,網(wǎng)卡允許我們對硬中斷進行合并。
現(xiàn)在我們來看一下網(wǎng)卡的硬中斷合并配置。
# ethtool -c eth0 Coalesce parameters for eth0: Adaptive RX: off TX: off ...... rx-usecs: 1 rx-frames: 0 rx-usecs-irq: 0 rx-frames-irq: 0 ......
我們來說一下上述結(jié)果的大致含義
Adaptive RX: 自適應(yīng)中斷合并,網(wǎng)卡驅(qū)動自己判斷啥時候該合并啥時候不合并
rx-usecs:當(dāng)過這么長時間過后,一個RX interrupt就會被產(chǎn)生
rx-frames:當(dāng)累計接收到這么多個幀后,一個RX interrupt就會被產(chǎn)生
如果你想好了修改其中的某一個參數(shù)了的話,直接使用ethtool -C就可以,例如:
ethtool -C eth0 adaptive-rx on
不過需要注意的是,減少中斷數(shù)量雖然能使得Linux整體吞吐更高,不過一些包的延遲也會增大,所以用的時候得適當(dāng)注意。
四 軟中斷監(jiān)控與調(diào)優(yōu)
在硬中斷之后,再接下來的處理過程就是ksoftirqd內(nèi)核線程中處理的軟中斷了。之前我們說過,軟中斷和它對應(yīng)的硬中斷是在同一個核心上處理的。因此,前面硬中斷分散到多核上處理的時候,軟中斷的優(yōu)化其實也就跟著做了,也會被多核處理。不過軟中斷也還有自己的可優(yōu)化選項。
1)監(jiān)控
軟中斷的信息可以從 /proc/softirqs 讀取:
$ cat /proc/softirqs CPU0 CPU1 CPU2 CPU3 HI: 0 2 2 0 TIMER: 704301348 1013086839 831487473 2202821058 NET_TX: 33628 31329 32891 105243 NET_RX: 418082154 2418421545 429443219 1504510793 BLOCK: 37 0 0 25728280 BLOCK_IOPOLL: 0 0 0 0 TASKLET: 271783 273780 276790 341003 SCHED: 1544746947 1374552718 1287098690 2221303707 HRTIMER: 0 0 0 0 RCU: 3200539884 3336543147 3228730912 3584743459
2)軟中斷budget調(diào)整
不知道你有沒有聽說過番茄工作法,它的大致意思就是你要有一整段的不被打擾的時間,集中精力處理某一項作業(yè)。這一整段時間時長被建議是25分鐘。對于我們的Linux的處理軟中斷的ksoftirqd來說,它也和番茄工作法思路類似。一旦它被硬中斷觸發(fā)開始了工作,它會集中精力處理一波兒網(wǎng)絡(luò)包(絕不只是1個),然后再去做別的事情。
我們說的處理一波兒是多少呢,策略略復(fù)雜。我們只說其中一個比較容易理解的,那就是net.core.netdev_budget內(nèi)核參數(shù)。
# sysctl -a | grep net.core.netdev_budget = 300
這個的意思說的是,ksoftirqd一次最多處理300個包,處理夠了就會把CPU主動讓出來,以便Linux上其它的任務(wù)可以得到處理。那么假如說,我們現(xiàn)在就是想提高內(nèi)核處理網(wǎng)絡(luò)包的效率。那就可以讓ksoftirqd進程多干一會兒網(wǎng)絡(luò)包的接收,再讓出CPU。至于怎么提高,直接修改不這個參數(shù)的值就好了。
# sysctl -w net.core.netdev_budget=600
如果要保證重啟仍然生效,需要將這個配置寫到/etc/sysctl.conf
3)軟中斷GRO合并
GRO和硬中斷合并的思想很類似,不過階段不同。硬中斷合并是在中斷發(fā)起之前,而GRO已經(jīng)到了軟中斷上下文中了。
如果應(yīng)用中是大文件的傳輸,大部分包都是一段數(shù)據(jù),不用GRO的話,會每次都將一個小包傳送到協(xié)議棧(IP接收函數(shù)、TCP接收)函數(shù)中進行處理。開啟GRO的話,Linux就會智能進行包的合并,之后將一個大包傳給協(xié)議處理函數(shù)。這樣CPU的效率也是就提高了。
# ethtool -k eth0 | grep generic-receive-offload generic-receive-offload: on
如果你的網(wǎng)卡驅(qū)動沒有打開GRO的話,可以通過如下方式打開。
# ethtool -K eth0 gro on
GRO說的僅僅只是包的接收階段的優(yōu)化方式,對于發(fā)送來說是GSO。
五 總結(jié)
在網(wǎng)絡(luò)技術(shù)這一領(lǐng)域里,有太多的知識內(nèi)容都停留在理論階段了。你可能覺得你的網(wǎng)絡(luò)學(xué)的滾瓜爛熟了,可是當(dāng)你的線上服務(wù)出現(xiàn)問題的時候,你還是不知道該怎么排查,怎么優(yōu)化。這就是因為只懂了理論,而不清楚Linux是通過哪些內(nèi)核機制將網(wǎng)絡(luò)技術(shù)落地的,各個內(nèi)核組件之間怎么配合,每個組件有哪些參數(shù)可以做調(diào)整。我們用兩篇文章詳細討論了Linux網(wǎng)絡(luò)包的接收過程,以及這個過程中的一些統(tǒng)計數(shù)據(jù)如何查看,如何調(diào)優(yōu)。相信消化完這兩篇文章之后,你的網(wǎng)絡(luò)的理解直接能提升1個Level,你對線上服務(wù)的把控能力也會更加如魚得水。
原文標題:Linux 網(wǎng)絡(luò)包接收過程的監(jiān)控與調(diào)優(yōu)
文章出處:【微信公眾號:Linux愛好者】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
責(zé)任編輯:haq
-
cpu
+關(guān)注
關(guān)注
68文章
11029瀏覽量
215870 -
Linux
+關(guān)注
關(guān)注
87文章
11450瀏覽量
212705
原文標題:Linux 網(wǎng)絡(luò)包接收過程的監(jiān)控與調(diào)優(yōu)
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
如何將Linux安裝包快速轉(zhuǎn)成玲瓏包

xgboost超參數(shù)調(diào)優(yōu)技巧 xgboost在圖像分類中的應(yīng)用
Linux TCP內(nèi)核的參數(shù)設(shè)置與調(diào)優(yōu)

MCF8316A調(diào)優(yōu)指南

MCT8316A調(diào)優(yōu)指南
MCT8315A調(diào)優(yōu)指南
TDA3xx ISS調(diào)優(yōu)和調(diào)試基礎(chǔ)設(shè)施
大數(shù)據(jù)從業(yè)者必知必會的Hive SQL調(diào)優(yōu)技巧
智能調(diào)優(yōu),使步進電機安靜而高效地運行
MMC SW調(diào)優(yōu)算法
TAS58xx系列通用調(diào)優(yōu)指南
Linux網(wǎng)絡(luò)協(xié)議棧的實現(xiàn)
AM6xA ISP調(diào)優(yōu)指南
OSPI控制器PHY調(diào)優(yōu)算法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論