") 混合CPU和模擬內(nèi)存AI處理器的發(fā)明專利解析
混合CPU和模擬內(nèi)存AI處理器的發(fā)明專利解析
英特爾發(fā)明的混合處理架構(gòu)的人工智能芯片,通過將CPU與模擬內(nèi)存AI處理器相耦合,從而達(dá)到加速神經(jīng)網(wǎng)絡(luò)運算的目的。
英特爾在2019年發(fā)布了兩款Nervana NNP系列新的處理器,目的在于加速人工智能模型的訓(xùn)練。據(jù)悉,英特爾的這兩款芯片是以2016年收購的Nervana Systems命名,在人工智能訓(xùn)練以及數(shù)據(jù)分析等方面有著極大的價值。
而英特爾與英偉達(dá)作為AI芯片競爭的主要成員,均在AI領(lǐng)域奮起發(fā)力,其中,英特爾主導(dǎo)AI推理市場,而英偉達(dá)主導(dǎo)AI訓(xùn)練芯片。
但是用于神經(jīng)網(wǎng)絡(luò)處理的加速器系統(tǒng),仍然存在著許多問題,例如由于與從存儲器到數(shù)字處理單元的數(shù)據(jù)傳輸?shù)膸捪拗贫鴮?dǎo)致的問題,這些加速器通常需要在片外存儲器和數(shù)字處理單元之間傳輸大量數(shù)據(jù),而這種數(shù)據(jù)傳輸會導(dǎo)致延遲和功耗的不良增加。
為此,英特爾在2020年7月30日申請了一項名為“混合CPU和模擬內(nèi)存人工智能處理器”的發(fā)明專利(公開號:US 2020/0242458 A1),申請人為英特爾公司,該專利旨在提供用于實現(xiàn)通用處理器的混合處理架構(gòu)的技術(shù)。
根據(jù)該專利目前公開的資料,讓我們一起來看看這項混合處理架構(gòu)的人工智能芯片吧。
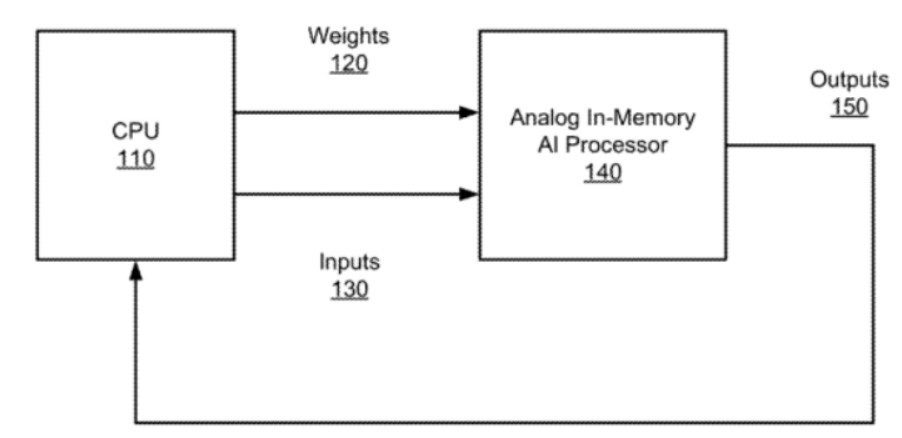
如上圖,為這種混合處理器的頂級框圖,可以看到,CPU與模擬內(nèi)存AI處理器相耦合,CPU是通用處理器,例如我們熟知的x86架構(gòu)處理器。模擬存儲器中AI處理器可以通過數(shù)字訪問電路從CPU接收加權(quán)因子和輸入數(shù)據(jù)130,并基于加權(quán)因子和數(shù)據(jù)執(zhí)行模擬神經(jīng)網(wǎng)絡(luò)處理。
模擬內(nèi)存中AI處理器包括多個MN層,可以將它們配置為卷積神經(jīng)網(wǎng)絡(luò)層和全連接層,并且可以任意的組合使用,卷積神經(jīng)網(wǎng)絡(luò)層的處理結(jié)果也可以通過數(shù)字訪問電路提供給CPU作為輸出150。
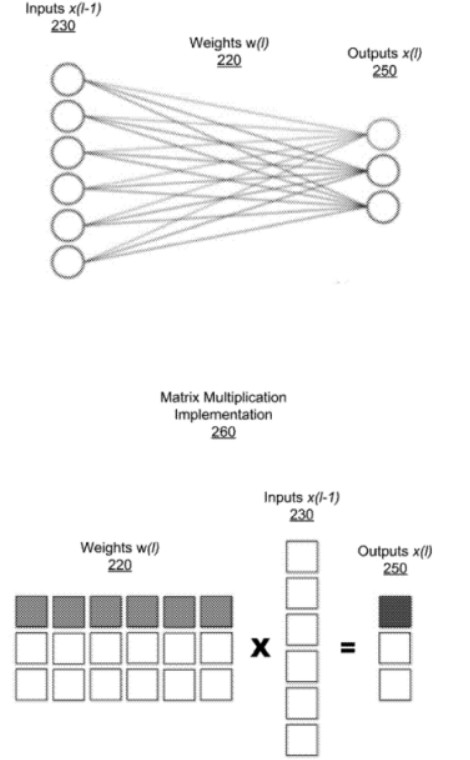
如上圖,展示了全連接層的網(wǎng)絡(luò)層和該層的矩陣乘法實現(xiàn),網(wǎng)絡(luò)層接受來自于上一層的輸入230,并將權(quán)重w(220)應(yīng)用于輸入x(230)和輸出x(250)之間的每個連接,由此將網(wǎng)絡(luò)實現(xiàn)為矩陣乘法運算,如260所示,將輸出的每個元素計算為權(quán)重220行與輸入230列之間的點積。
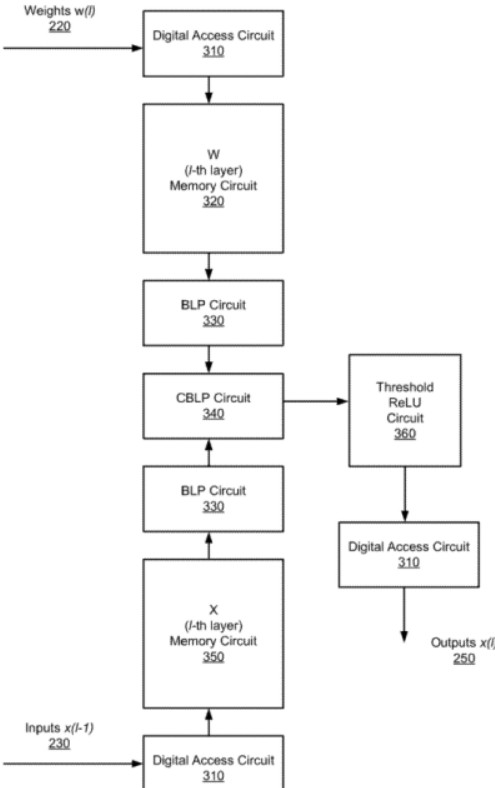
如上圖,為該專利中的模擬內(nèi)存人工智能處理器的框圖,AI處理器用來實現(xiàn)完全連接的單個神經(jīng)網(wǎng)絡(luò)層,其中包括數(shù)字訪問電路310、第一存儲器電路320、第二存儲器電路350、位線處理器電路330、交叉位線處理器電路340以及閾值整流線性單元(ReLU)電路360。
這些電路的作用就是實現(xiàn)各種點乘運算以及模擬乘法運算,這些運算是深度神經(jīng)網(wǎng)絡(luò)中常用的操作,而人工智能芯片就是在硬件的層面上對于這些運算進行實現(xiàn),而直接從硬件層面進行運算的好處就在于會更加的快捷以及有較高的效率。
具體而言,交叉位線處理器電路通過定時電容器上的電流積分來執(zhí)行點積運算的模擬乘法部分,該電路實際上是一個與開關(guān)串聯(lián)的電容器。在位線上感測到的電壓作為被乘數(shù)輸入之一,通過與電容器產(chǎn)生電流,另一個被乘數(shù)用來控制串聯(lián)開關(guān)的時序,以使開關(guān)導(dǎo)通的持續(xù)時間與第二個開關(guān)成比例。從而通過電荷累積來執(zhí)行點積運算的模擬求和部分。
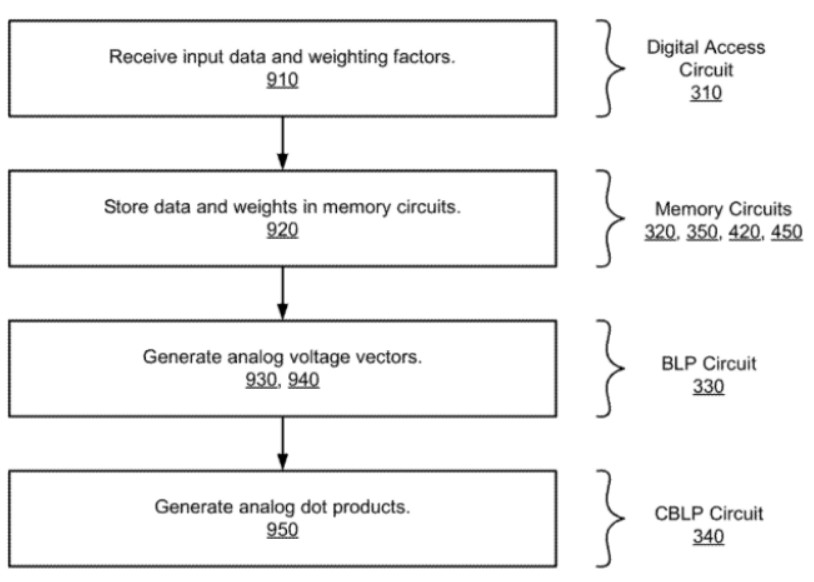
最后,是這種用于模擬內(nèi)存中神經(jīng)網(wǎng)絡(luò)處理的方法的流程圖,如上圖所示,可以看出,這種方法包括了多個階段和子過程,分別對應(yīng)著上述的系統(tǒng)架構(gòu)來實現(xiàn)。首先,用于模擬內(nèi)存中神經(jīng)網(wǎng)絡(luò)處理的方法通過數(shù)字訪問電路從CPU中接收輸入數(shù)據(jù)和加權(quán)因子而開始運算。
接著,將輸入數(shù)據(jù)存儲在第一存儲電路中,并將加權(quán)因子存儲在第二存儲電路中,存儲電路用于模擬內(nèi)存計算。其次,由第一存儲電路生成模擬電壓值,有第二存儲電路生成模擬電壓值的第二序列。最后,再由交叉位線處理器計算一系列的模擬點積,從而完成整個運算過程。
以上就是英特爾發(fā)明的混合處理架構(gòu)的人工智能芯片,通過將CPU與模擬內(nèi)存AI處理器相耦合,從而達(dá)到加速神經(jīng)網(wǎng)絡(luò)運算的目的。這種技術(shù)特別適用于AI平臺,例如在智能家居控制系統(tǒng)、機器人、虛擬助手等方面均可以發(fā)揮重要的作用。
關(guān)于嘉德
深圳市嘉德知識產(chǎn)權(quán)服務(wù)有限公司由曾在華為等世界500強企業(yè)工作多年的知識產(chǎn)權(quán)專家、律師、專利代理人組成,熟悉中歐美知識產(chǎn)權(quán)法律理論和實務(wù),在全球知識產(chǎn)權(quán)申請、布局、訴訟、許可談判、交易、運營、標(biāo)準(zhǔn)專利協(xié)同創(chuàng)造、專利池建設(shè)、展會知識產(chǎn)權(quán)、跨境電商知識產(chǎn)權(quán)、知識產(chǎn)權(quán)海關(guān)保護等方面擁有豐富的經(jīng)驗。
責(zé)任編輯:tzh
-
處理器
+關(guān)注
關(guān)注
68文章
19807瀏覽量
233557 -
芯片
+關(guān)注
關(guān)注
459文章
52184瀏覽量
436205 -
AI
+關(guān)注
關(guān)注
87文章
34233瀏覽量
275391 -
人工智能
+關(guān)注
關(guān)注
1804文章
48713瀏覽量
246511
發(fā)布評論請先 登錄
歐菲光再添兩項國家發(fā)明專利
端側(cè) AI 音頻處理器:集成音頻處理與 AI 計算能力的創(chuàng)新芯片
中微公司發(fā)明專利再獲中國專利獎殊榮
Ampere發(fā)布最新192核12內(nèi)存通道AmpereOne M處理器
善思微入選四川企業(yè)發(fā)明專利擁有量百強企業(yè)榜
篤行不怠,踔厲奮發(fā),華普微又一科技成果獲發(fā)明專利授權(quán)

內(nèi)存和微處理器的互聯(lián)演變
芯啟源取得GNSS有源功分器發(fā)明專利證書
微處理器與CPU的關(guān)系
盛顯科技:在拼接處理器上配置混合矩陣的步驟是什么?
ARM處理器和CPU有什么區(qū)別
盛顯科技:拼接處理器為什么要配置混合矩陣?

村田起訴國產(chǎn)電感龍頭順絡(luò)電子侵犯發(fā)明專利







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論