 一種優化深度網絡的降維分解技術解析
一種優化深度網絡的降維分解技術解析

本篇介紹的也是采用了降維的思想來加速網絡推理,但是數學上采用了不同的方法。而且這篇文章提出的方法可以加速深度網絡,其在vgg-16上進行了實驗,獲得了4倍的加速效果,而在imageNet分類中top-5錯誤率僅有0.3%升高。
1、原理
首先我們來看神經網絡中的卷積運算的形式,對于任一個隱藏層,它有c幅輸入圖片,每幅圖片都會和一個卷積核進行卷積運算。假設卷積核大小為kxk,那么就有c個卷積核。我們可以將圖片沿著個數方向重新生成一個維度,圖片就成了一個3D的張量,大小為hxhxc。卷積核為kxkxc,其在kxk方向進行劃窗,而c方向進行求和。每個輸出點實際上是kxkxc個乘法求和結果。這c個卷積核會輸出一幅圖片,如果隱藏層有d個節點,實際上是輸出n幅圖片。如果將kxkxcxd這么大的卷積核進行重新排列,排成一個d行,每行有kxkxc個數據,就稱為了一個矩陣,我們令為W。那么輸入圖片排成一個向量,長度為kxkxc。用矩陣乘法可以表示為:
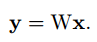
W為一個dx(kkc+1)的維度矩陣,多增加一個1是將bias加在末尾。但是有人會問一幅圖片是hxh個點,現在僅在x向量中取了其kxk個點,那么其他的點如何計算呢?實際上其它點可以看做為多組x向量輸入,在之后降維分解中都考慮在內。
從上述公式看出,計算量復雜度為O(dkkc)。文章中文章可以用于更深網絡的本質原因。
接下來作者重新表達y為:
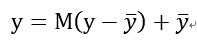
M是一個dxd的矩陣,秩為d’。y-是平均響應,其維度也為d’。但是這里作者為什么引入了y-并沒有講。我想和歸一化有類似作用吧,可以糾正數據沿著網絡傳輸的發散性。經過降維的后的y,其和x關系變為了:
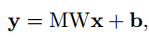
b是新生成的bias,為:
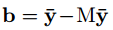
由于M的秩為d’,所以可以進行分解為:
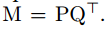
那么就有:
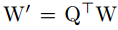

W矩陣變為d’x(kkc+1)大小,因此計算量降低為O(d’kkc)+O(dd’),因為O(dd’)很小,所以計算復雜度變為原來的d’/d。實際上是減小了神經網絡中輸入通道的數量,將輸入通道減少拆分成兩層網絡,如圖中所示。而CP分解的權重通道數沒有變,而是減小了kxk方向維度。
以上公式的導出都是基于y有較低的維數表達,實際中并不會有這樣嚴格的數學性質,因為對于任意輸入x,以及不同訓練集訓練出來的網絡,我們不能保證y的維數實際低于d。所以這變成了一個近似問題,如何選擇一個d’,同時使得新獲得的參數的網絡可以逼近最初結果。作者使用平方差來作為目標函數進行計算:

以上優化問題可以很容易獲得解。實際上是尋找yyT的最大本征值,這類似于PCA方法。通過提取出排列在前幾位最大的本征值,而剩余本征值設置為0來優化網絡參數。最大本征值反應了表達y的信息的能力。然后通過一些矩陣變換就可以得到M矩陣。
上述方法很容易兼容非線性單元,因為考慮非線性單元后,優化目標變為:
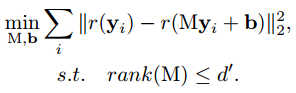
其中r為非線性函數,作者只考慮了ReLu函數的求解。以上目標函數很難求解,因此作者做了一些數學變換,將上述損失函數進行了松弛處理,即引入了z,重新表達為:
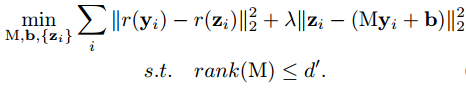
從中看出當lamda逼近無窮時,其目標函數等同于原始目標函數。通過上述方法,可以優化每一層的網絡參數。因為每層網絡的輸出是下層輸入,所以整個優化一層層傳遞下去可以完成整體網絡優化。
2、結果
首先作者選擇了一個10層網絡進行試驗,結果為:
這里symmetric和asymmetric是作者進行非線性優化時,分別使用了原始的輸入結果和近似輸入結果來進行的。實際上是修正每層造成的錯誤沿著層向前積累。可以看出asymmetric比symmetric有更低的錯誤率。
VGG是一個廣泛使用的網絡模型,是一個深度網絡,其被廣泛用于物體識別,圖像分割,視頻分析中。作者在VGG-16上進行了實驗,實驗結果和CP分解的做了對比,如圖:
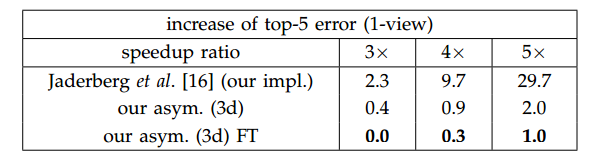
結論
本文介紹了另外一種降維方法,其可以優化深度網絡。個人感覺其還是有一定局限性,首先其在網絡前向傳輸優化時,錯誤率還是會進行積累,這也是僅僅優化了16層VGG的原因,當然這相比CP分解確實加深了。但是類似resnet這樣更深的網絡,作者并沒有報道過。
編輯:hfy
-
神經網絡
+關注
關注
42文章
4814瀏覽量
103577
發布評論請先 登錄
一種基于經優化算法優化過的神經網絡設計FIR濾波器的方法介紹
文本分類中一種混合型特征降維方法
降維空時自適應處理研究

基于譜特征嵌入的腦網絡狀態觀測矩陣降維方法
如何使用FPGA實現高光譜圖像奇異值分解降維技術
一種帶核方法的判別圖正則非負矩陣分解算法

一種基于DSCNN-BILSTM的入侵檢測方法

一種基于DeepFM的深度興趣因子分解機網絡

一種新型的數據采集多視圖降維算法技術
淺析卷積降維與池化降維的對比





 工商網監
工商網監
評論