 在語音處理中,通過使用大數據可以輕松解決很多任務
在語音處理中,通過使用大數據可以輕松解決很多任務
在語音處理中,通過使用大量數據可以輕松解決很多任務。例如,將語音轉換為文本的 自動語音識別 (Automatic Speech Recognition,ASR)。相比之下,“非語義”任務側重于語音中含義以外的其他方面,如“副語言(Paralinguistic)”任務中包含了語音情感識別等其他類型的任務,例如發言者識別、語言識別和某些基于語音的醫療診斷。完成這些任務的訓練系統通常利用盡可能大的數據集來確保良好結果。然而,直接依賴海量數據集的機器學習技術在小數據集上進行訓練時往往不太成功。
為了縮小大數據集和小數據集之間的性能差距,可以在大數據集上訓練 表征模型 (Representation Model),然后將其轉移到小數據集的環境中。表征模型能夠通過兩種方式提高性能:將高維數據(如圖像和音頻)轉換到較低維度進而訓練小模型,而且表征模型還可以用作預訓練。此外,如果表征模型小到可以在設備端運行或訓練,就能讓原始數據始終保留在設備中,在為用戶提供個性化模型好處的同時,以保護隱私的方式提高性能。雖然表征學習已普遍用于文本領域(如 BERT和 ALBERT)和圖像領域(如 Inception 層 和 SimCLR),但這種方法在語音領域尚未得到充分利用。
下:使用大型語音數據集訓練模型,然后將其推廣到其他環境;左上:設備端個性化 - 個性化的設備端模型將安全和隱私相結合;中上:嵌入向量的小模型 - 通用表征將高維度、少示例的數據集轉換到低維度,同時不降低準確率;較小的模型訓練速度更快,并且經過正則化。右上:全模型微調 - 大數據集可以使用嵌入向量模型作為預訓練以提高性能
如果沒有一個衡量“語音表征有用性”的標準基準,就很難顯著地改進通用表征,尤其是對于非語義語音任務。盡管 T5框架系統地評估了文本嵌入向量,并且視覺領域任務自適應基準 (VTAB) 對圖像嵌入向量評估進行了標準化,兩者均促進了相應領域表征學習的進展,但對于非語義語音嵌入向量卻沒有類似基準。
在“Towards Learning a Universal Non-Semantic Representation of Speech”中,我們對語音相關應用的表征學習做出了三項努力:
提出一個比較語音表征的非語義語音 (NOn-Semantic Speech,NOSS) 基準,其中包括多樣化的數據集和基準任務,例如語音情感識別、語言識別和發言者識別。這些數據集可在TensorFlow Datasets 的“音頻”部分中找到。
創建并開源了 TRIpLet Loss 網絡 (TRILL),此全新模型小到可以在設備端執行和微調,同時仍然優于其他表征模型。
進行了大規模研究來比較不同的表征,并開源了用于計算新表征性能的代碼。
Towards Learning a Universal Non-Semantic Representation of Speech
https://arxiv.org/abs/2002.12764
這些數據集
https://tensorflow.google.cn/datasets/catalog/overview#audio
TensorFlow Datasets
https://tensorflow.google.cn/datasets/
TRIpLet Loss 網絡
https://aihub.cloud.google.com/s?q=nonsemantic-speech-benchmark
開源
https://github.com/google-research/google-research/tree/master/non_semantic_speech_benchmark
語音嵌入向量的新基準
為了能夠有效指導模型開發,基準必須包含具有類似解決方案的任務,并排除存在顯著差異的任務。既往工作或為獨立處理各種潛在語音任務,或為將語義任務和非語義任務歸納在一起。我們的工作在一定程度上通過關注在語音任務子集上表現良好的神經網絡架構,提高了非語義語音任務的性能。
NOSS 基準的任務選擇依據:
多樣性 - 需要覆蓋一系列使用案例;
復雜性 - 應該具有挑戰性;
可用性,特別強調開源任務。
我們結合了具有不同規模和任務的六個數據集。
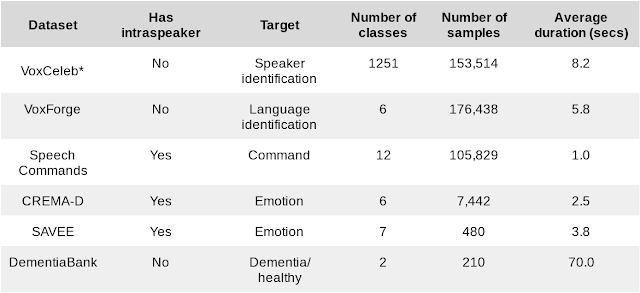
下游基準任務的數據集
*我們的研究使用根據內部政策篩選的數據集子集計算 VoxCeleb 結果
我們還引入了三個額外的演講者內部任務,并測試個性化場景下的性能。在具有 k 個演講者的某些數據集中,我們可以創建 k 個不同的任務,只針對單一演講者進行訓練和測試。整體性能是各演講者的平均值。三個額外的演講者內部任務衡量了嵌入向量適應特定演講者的能力,這是個性化設備端模型的必要能力。隨著 ML 向智能手機和物聯網延伸,這些模型變得越來越重要。
為了幫助研究人員比較語音嵌入向量,我們已經將基準中的六個數據集添加到 TensorFlow Datasets 中(在“音頻”部分),并開源了評估框架。
將基準中的六個數據集添加到 TensorFlow Datasets 中
https://tensorflow.google.cn/datasets/catalog/overview#audio
開源了評估框架
https://github.com/google-research/google-research/tree/master/non_semantic_speech_benchmark
TRILL:非語義語音分類的新技術
在語音領域中,從一個數據集學習嵌入向量并將其應用到其他任務不如其他模式中那樣普遍。然而,使用一項任務的數據幫助另一項任務(不一定是嵌入向量)的遷移學習,作為一種更為通用的技術,具有一些引人注目的應用,例如個性化語音識別器和少量樣本的語音模仿:文本到語音的轉換。過去已經有多種語音表征,但其中大多是在較小規模和較低多樣性的數據上進行訓練,或主要在語音識別上進行測試,或兩者皆有。
我們基于約 2500 小時語音的大型多樣化數據集 AudioSet 為起點,創建跨環境和任務的實用數據衍生語音表征。我們通過先前的度量學習工作得出簡單的自監督標準,在此標準上訓練嵌入向量模型 - 來自相同音頻的嵌入向量在嵌入向量空間中應該比來自不同音頻的嵌入向量更為接近。與 BERT 和其他文本嵌入向量類似,自監督損失函數不需要標簽,只依賴于數據本身的結構。這種自監督形式最適合非語義語音,因為非語義現象在時間上比 ASR 和其他亞秒級語音特征更穩定。這種簡單的自監督標準捕獲了下游任務所用的大量聲學特性。
AudioSet
https://research.google.com/audioset/
TRILL 損失:來自相同音頻的嵌入向量在嵌入空間中比來自不同音頻的嵌入向量更為接近
TRILL 架構基于 MobileNet,其速度適合在移動設備上運行。為了在這種小架構上實現高準確率,我們在不降低性能的同時從更大的 ResNet50 模型中提取出嵌入向量。
基準結果
我們首先比較了 TRILL 與其他深度學習表征的性能。這些表征并不局限于語音識別,并在類似的不同數據集上進行訓練。此外,我們還將 TRILL 與熱門的 OpenSMILE 特征提取器進行比較。OpenSMILE 使用預深度學習技術(如:傅里葉變換系數、使用基音測量的時間序列的“基音跟蹤”等)以及隨機初始化網絡,這些技術已被證明是強大的基線。
為了對不同性能特征的任務進行性能匯總,我們首先針對給定的任務和嵌入向量訓練少量的簡單模型,選擇最佳結果。然后,為了了解特定嵌入向量對所有任務的影響,我們以模型和任務為解釋變量,對觀察到的精度進行了線性回歸計算。模型對準確率的影響即為回歸模型中的相關系數。對于給定任務,從一種模型切換到另一種模型時,產生的準確率變化的差異預計為下圖中 y 值。
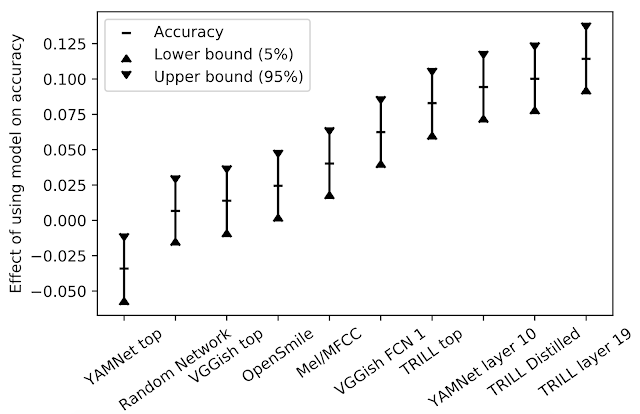
對模型準確率的影響
在我們的研究中,TRILL 性能優于其他表征。TRILL 的成功在于訓練數據集的多樣性、網絡的上下文大窗口以及 TRILL 訓練損失的通用性,最后一項因素保留了大量聲學特征,而不是過早地關注特定方面。需要注意的是,來自網絡層的中間表征往往更具有通用性。中間表征更大,時間粒度更細,在分類網絡的情況下,它們保留了更通用的信息,而不像訓練它們的類那樣具體。
通用模型的另一個優勢是可以在新任務上初始化模型。當新任務的樣本量較小時,相較于從頭訓練模型,對現有模型進行微調可能會獲得更好的結果。盡管沒有針對特定數據集進行超參數調整,但使用此技術,我們仍然在六個基準任務的三個任務上取得了新的 SOTA 結果。
為了更新的表征,我們還在Interspeech 2020 Computational Paralinguistics Challenge (ComParE) 的口罩賽道中進行了測試。在挑戰中,模型必須預測發言者是否佩戴口罩,因為口罩會影響語音。口罩的影響有時微乎其微,并且音頻片段只有一秒。TRILL 線性模型表現比基線模型更好的性能,該模型融合了許多不同模型的特征,如傳統的光譜和深度學習特征。
Interspeech 2020 Computational Paralinguistics Challenge (ComParE)
http://www.compare.openaudio.eu/compare2020/
基線模型
http://compare.openaudio.eu/wp-content/uploads/2020/05/INTERSPEECH_2020_ComParE.pdf
總結
評估 NOSS 的代碼位于 GitHub,數據集位于 TensorFlow Datasets,TRILL 模型位于 AI Hub。
GitHub
https://github.com/google-research/google-research/tree/master/non_semantic_speech_benchmark
TensorFlow Datasets
https://tensorflow.google.cn/datasets/catalog/overview#audio
AI Hub
https://aihub.cloud.google.com/s?q=nonsemantic-speech-benchmark
非語義語音基準可幫助研究人員創建語音嵌入向量,適用于包括個性化和小數據集問題的各種環境。我們將 TRILL 模型提供給研究界,作為等待超越的基線嵌入向量。
致謝
這項工作的核心團隊包括 Joel Shor、Aren Jansen、Ronnie Maor、Oran Lang、Omry Tuval、Felix de Chaumont Quitry、Marco Tagliasacchi、Ira Shavitt、Dotan Emanuel 和 Yinnon Haviv。我們還要感謝 Avinatan Hassidim 和 Yossi Matias 的技術指導。
原文標題:通過自監督學習對語音表征與個性化模型進行改善
文章出處:【微信公眾號:TensorFlow】歡迎添加關注!文章轉載請注明出處。
-
大數據
+關注
關注
64文章
8949瀏覽量
139396 -
語言識別
+關注
關注
0文章
15瀏覽量
4900
原文標題:通過自監督學習對語音表征與個性化模型進行改善
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
明遠智睿SSD2351核心板在語音對講與HMI領域的創新應用
適用于Oracle的Devart Excel插件:輕松管理數據





 工商網監
工商網監
評論