 數據倉庫開發技術的重要一環:ETL
數據倉庫開發技術的重要一環:ETL
大家都知道數據倉庫,是為企業所有級別的決策制定過程,提供所有類型數據支持的戰略集合。因此越來越多的企業和管理者對數據倉庫格外關注。做好數據倉庫開發,一靠工具,二靠技術。就工具方面來說,很多云廠商已經提供了相當成熟和完備的解決方案。
以我們華為云舉例,目前華為云的數據倉庫服務 GaussDB(DWS)已經做到了:實時、簡單、安全可信的企業級融合數據倉庫,并可借助DWS Express將查詢分析擴展至數據湖。基于華為GaussDB產品的云原生服務,也可以兼容標準SQL和PostgreSQL/Oracle生態。所以,在工具完備的情況下,開發者們更關注的應該是技術層面。今天小編要和大家分享的,就是構建數據倉庫的重要一環:ETL。
ETL是將業務系統的數據經過抽取、清洗轉換之后加載到數據倉庫的過程,是構建數據倉庫的重要一環,用戶從數據源抽取出所需的數據,經過數據清洗,最終按照預先定義好的數據倉庫模型,將數據加載到數據倉庫中。目的是將企業中的分散、零亂、標準不統一的數據整合到一起,為企業的決策提供分析依據。
ETL算法概覽
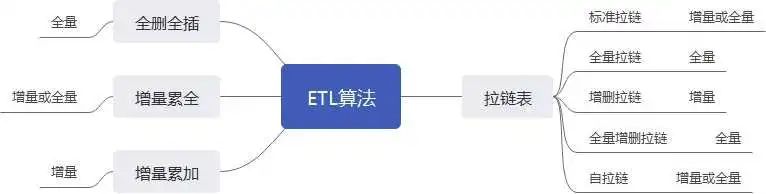
算法應用場景概覽
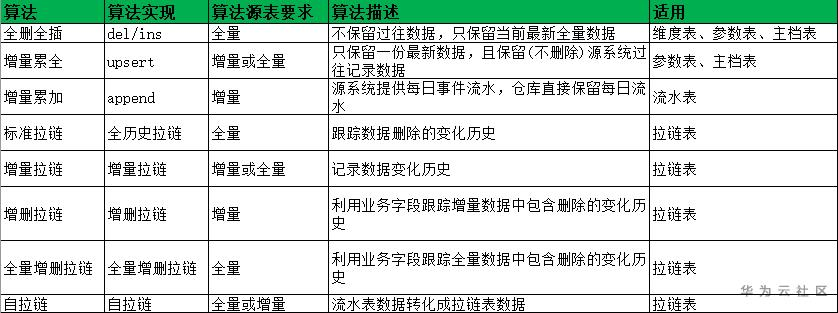
以上共計累積了8種ETL算法,其中主要分成4大類,增量累加、拉鏈算法是更符合數據倉庫歷史數據追蹤的算法,但現實中基于業務及性能考慮,往往存在全刪全插、增量累全算法的數據表應用。
全刪全插模型
即Delete/Insert實現邏輯;
應用場景
主要應用在維表、參數表、主檔表加載上,即適合源表是全量數據表,該數據表業務邏輯只需保存當前最新全量數據,不需跟蹤過往歷史信息。
算法實現邏輯
1.清空目標表; 2.源表全量插入;
ETL代碼原型
--1.清理目標表 TRUNCATE TABLE <目標表>; -- 2. 全量插入 INSERT INTO <目標表> (字段***) SELECT 字段*** FROM <源表> ***JOIN <關聯數據> WHERE ***;
增量累全模型
即Upsert實現邏輯;
應用場景
主要應用在參數表、主檔表加載上,即源表可以是增量或全量數據表,目標表始終最新最全記錄。
算法實現邏輯
1.利用PK主鍵比對; 2.目標表和源表PK一致的變化記錄,更新目標表; 3.源表存在但目標表不存在,直接插入;
ETL代碼原型
--1.生成加工源表 Create temp Table <臨時表> ***; INSERT INTO <臨時表> (字段***) SELECT 字段*** FROM <源表> ***JOIN <關聯數據> WHERE *** ; -- 2. 可利用Merge Into實現累全能力,當前也可以采用分步Delete/Insert或Update/Insert操作 Merge INTO <目標表> As T1 (字段***) Using <臨時表> as S1 on (***PK***) when Matched then update set Colx = S1.Colx *** when Not Matched then INSERT (字段***) values (字段*** )
增量累加模型
即Append實現邏輯;
應用場景
主要應用在流水表加載上,即每日產生的流水、事件數據,追加到目標表中保留全歷史數據。流水表、快照表、統計分析表等均是通過該邏輯實現。
算法實現邏輯
1.源表直接插入目標表;
ETL代碼原型
-- 1.插入目標表 INSERT INTO <目標表> (字段***) SELECT 字段*** FROM <源表> ***JOIN <關聯數據> WHERE ***;
全歷史拉鏈模型
拉鏈表背景知識
概念 拉鏈表是一張至少存在PK字段、跟蹤變化的字段、開鏈日期、閉鏈日期組成的數據倉庫ETL數據表;
益處 根據開鏈、閉鏈日期可以快速提取對應日期有效數據; 對于跟蹤源系統非事件流水類表數據,拉鏈算法發揮越大作用,源業務系統通常每日變化數據有限,通過拉鏈加工可以大大降低每日打快照帶來的空間開銷,且不損失數據變化歷史;
示例 提取指定日期有效數據
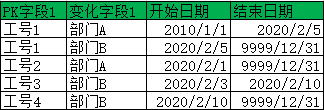
提取2020年2月5日當日有效數據
Select* From <目標表> Where 開始日期<=date'2020-02-05' And 結束日期 >date'2020-02-05';
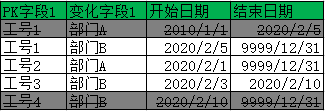
最終提取到數據:
應用場景
全歷史拉鏈,跟蹤源表全量變化歷史,若源表記錄不存在,則說明數據閉鏈;根據PK新拉一條有效記錄。
算法實現邏輯
1.提取當前有效記錄; 2.提取當日源系統最新數據; 3.根據PK字段比對當前有效記錄與最新源表,更新目標表當前有效記錄,進行閉鏈操作; 4.根據全字段比對最新源表與當前有效記錄,插入目標表;
ETL代碼原型
--1.提取當前有效記錄 Insert into <臨時表-開鏈-pre> (不含開閉鏈字段***) Select 不含開閉鏈字段*** From <目標表> Where 結束日期 =date'<最大日期>'; ; -- 2. 提取當日源系統最新數據 <源表臨時表-cur> -- 3 今天全部開鏈的數據,即包含今天全新插入、數據發生變化的記錄 Insert Into <臨時表-增量-ins> Select 不含開閉鏈字段*** From <源表臨時表-cur> where (不含開閉鏈字段***) not in (Select 不含開閉鏈字段*** From <臨時表-開鏈-pre> ); -- 4 今天需要閉鏈的數據,即今天發生變化的記錄 Insert into <臨時表-增量-upd> Select 不含開閉鏈字段***,開始時間 From <臨時表-開鏈-pre> where (不含開閉鏈字段***) not in (Select 不含開閉鏈字段*** From <臨時表-開鏈-cur> ); -- 5 更新閉鏈數據,即歷史記錄閉鏈(刪除-插入替代更新) DELETE FROM <目標表> WHERE (PK***) IN (Select PK*** From <臨時表-增量-upd>) AND 結束日期=date'<最大日期>'; INSERT INTO <目標表> (不含開閉鏈字段***,開始時間,結束日期) Select 不含開閉鏈字段***,開始時間,date'<數據日期>' From <臨時表-增量-upd>; -- 6 插入開鏈數據,即當日新增記錄 INSERT INTO <目標表> . (不含開閉鏈字段***,開始時間,結束日期) Select 不含開閉鏈字段***,date'<數據日期>',date'<最大日期>' From <臨時表-增量-ins>;
增量拉鏈模型
應用場景
增量拉鏈,目的是追蹤數據增量變化歷史,根據PK比對新拉一條開鏈數據;
算法實現邏輯
1.提取上日開鏈數據; 2.PK相同變化記錄,關閉舊記錄鏈,開啟新記錄鏈; 3.PK不同,源表存在,新增開鏈記錄
ETL代碼原型
--1.提取當前有效記錄 Insert into <臨時表-開鏈-pre> (不含開閉鏈字段***) Select 不含開閉鏈字段*** From <目標表> Where 結束日期 =date'<最大日期>'; -- 2. 提取當日源系統增量記錄 <源表臨時表-cur> -- 3. 提取當日源系統新增記錄 Insert into <臨時表-增量-ins> Select 不含開閉鏈字段*** From <臨時表-開鏈-cur> where (***PK***) not in (select ***PK*** from <臨時表-開鏈-pre>); -- 4. 提取當日源系統歷史變化記錄 Insert into <臨時表-增量-upd> Select 不含開閉鏈字段*** From <臨時表-開鏈-cur> inner join <臨時表-開鏈-pre> on (***PK 等值***) where (***變化字段 非等值***); -- 5. 更新歷史變化記錄,關閉歷史舊鏈,開啟新鏈 update <目標表> AS T1 SET <***變化字段 S1賦值***>,結束日期 = date'<數據日期>' FROM <臨時表-增量-upd> AS S1 WHERE ( <***PK 等值***> ) AND T1.結束日期 =date'<最大日期>' ; INSERT INTO <目標表> (不含開閉鏈字段***,開始時間,結束日期) SELECT 不含開閉鏈字段***,date'<數據日期>',date'<最大日期>' FROM <臨時表-增量-upd>; -- 6. 插入全新開鏈數據 INSERT INTO <目標表> (不含開閉鏈字段***,開始時間,結束日期) SELECT 不含開閉鏈字段***,date'<數據日期>',date'<最大日期>' FROM <臨時表-增量-ins>;
增刪拉鏈模型
應用場景
主要是利用業務字段跟蹤增量數據中包含刪除的變化歷史。
算法實現邏輯
1.提取上日開鏈數據; 2.提取源表非刪除記錄; 3.PK相同變化記錄,關閉舊記錄鏈,開啟新記錄鏈; 4.PK比對,源表存在,新增開鏈記錄; 5.提取源表刪除記錄; 6.PK比對,舊開鏈記錄存在,關閉舊記錄鏈;
ETL代碼原型
--1.清理目標表《待續...》 TRUNCATE TABLE <目標表>; -- 2. 全量插入 INSERT INTO <目標表> (字段***) SELECT 字段*** FROM <源表> ***JOIN <關聯數據> WHERE ***;
全量增刪拉鏈模型
應用場景
主要是利用業務字段跟蹤全量數據中包含刪除的變化歷史。
算法實現邏輯
1.提取上日開鏈數據; 2.提取源表非刪除記錄; 3.PK相同變化記錄,關閉舊記錄鏈,開啟新記錄鏈; 4.PK比對,源表存在,新增開鏈記錄; 5.提取源表刪除記錄; 6.PK比對,舊開鏈記錄存在,關閉舊記錄鏈; 7.PK比對,提取舊開鏈存在但源表不存在記錄,關閉舊記錄鏈;
ETL代碼原型
-- 1. 清理目標表,《待續...》 TRUNCATE TABLE <目標表>; -- 2. 全量插入 INSERT INTO <目標表> (字段***) SELECT 字段*** FROM <源表> ***JOIN <關聯數據> WHERE ***;
自拉鏈模型
應用場景
主要將流水表數據轉化成拉鏈表數據。
算法實現邏輯
借助源表業務日期字段,和目標表開鏈、閉鏈日期比對,首尾相接,拉出全歷史拉鏈;
ETL代碼原型
--1.清理目標表,《待續...》 TRUNCATE TABLE <目標表>; -- 2. 全量插入 INSERT INTO <目標表> (字段***) SELECT 字段*** FROM <源表> ***JOIN <關聯數據> WHERE ***;
其它說明
1.根據數據倉庫最佳實踐,所有數據表通常還會包含一些控制字段,即插入日期、更新日期、更新源頭字段,這樣對于數據變化敏感的數據倉庫,可以進一步追蹤數據變化歷史; 2.ETL算法本身是為了更好服務于數據加工過程,實際業務實現過程中,并不局限于傳統算法,即涉及到更多適應業務的自定義的ETL算法。
原文標題:8種優秀ETL算法推薦!數據倉庫開發者看過來~
文章出處:【微信公眾號:華為開發者社區】歡迎添加關注!文章轉載請注明出處。
-
ETL
+關注
關注
0文章
21瀏覽量
9536 -
數據倉庫
+關注
關注
0文章
61瀏覽量
10631
原文標題:8種優秀ETL算法推薦!數據倉庫開發者看過來~
文章出處:【微信號:Huawei_Developer,微信公眾號:華為開發者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
惠倫晶體邀您相約2025中國國際新能源汽車展
兆易創新2024年深圳人社公益培訓圓滿收官

灌區泵站信息化監控運維管理系統方案
汽車擺臂行業生產設備數據采集及集成

智慧消防監管平臺:科技賦能,重塑消防安全新生態
交流單相端子(焊片)連接濾波器的重要性與應用
明達技術工業級邊緣計算網關:智能制造的智慧紐帶

認識PCB碳油工藝:電路板創新的重要一環
漢得利BESTAR BMV1022H09雙向線性馬達的性能
數據倉庫與數據庫的主要區別
5G技術引領固定無線接入(FWA)飛速增長






 工商網監
工商網監
評論