 Nirkin提出單編碼器 - 多解碼器網絡架構和算法對換臉質量的影響
Nirkin提出單編碼器 - 多解碼器網絡架構和算法對換臉質量的影響

迪士尼新研究實現百萬像素圖像和視頻換臉,說不定未來大熒幕電影也會使用換臉技術了。
deepfakes 技術可以用于圖像和視頻換臉,但它能否用于大制作電影和電視節目中呢?迪士尼最新放出的一則視頻 demo 展示了這種可能性。
近日迪士尼在歐洲圖形學會透視研討會(EGSR)上發表研究,展示了首個百萬像素逼真換臉技術。
效果是不是還不錯。這樣的效果雖然并不足以用于漫威電影,但它是換臉技術邁出的新一步。
來自迪士尼的研究者表示,這項技術的創新點在于能夠達到百萬像素質量。百萬像素或許不再是高質量圖像的代名詞,畢竟手機自帶攝像頭就能達到千萬像素。但是截至目前,換臉技術一直注重平滑的面部轉換,不注重提高像素。
你可能在手機上看到過效果好到爆炸的換臉視頻,但是如果把它們放在更大的屏幕上呈現,就會出現很多瑕疵。研究者表示,他們用開源 deepfake 模型 DeepFakeLab 創建的視頻分辨率最高也只有 256*256 像素。相比之下,迪士尼新模型能夠讓視頻的分辨率提升到 1024*1024 像素。
那么,百萬像素換臉是如何實現的呢?
首個百萬像素換臉方法
迪士尼的這項研究發表在歐洲圖形學會透視研討會(EGSR)上,提出了一種在圖像和視頻中實現全自動換臉的算法。據研究者稱,這是首個渲染百萬像素逼真結果的方法,且輸出結果具備時序一致性。
具體來說,該研究提出了一個漸進式訓練的多路 comb 網絡,以及一種保持亮度和對比度的混合方法。
具體而言,雖然漸進式訓練能夠生成高分辨率圖像,但將架構和訓練數據擴展至兩人以上可以使生成的表情具備更高的保真度。
此外,在將生成的表情合成到目標人臉時,研究者調整混合策略,以保持對比度和低頻光照。
最后,研究者在人臉關鍵點穩定算法中融入了一種細化策略,以實現時序穩定性,這對于處理高分辨率視頻來說至關重要。
在實驗部分,研究者通過控制變量研究來驗證該方法對換臉質量的影響,并與流行的 SOTA 方法進行了比較。
百萬像素分辨率下執行逼真換臉的整體流程:
該流程包括如下四個步驟:
對于圖像 x_t,檢測人臉并定位人臉關鍵點;
將人臉分辨率歸一化為 1024×1024,保存歸一化參數;
將歸一化人臉饋入網絡,并保存第 s 個解碼器的輸出 x?_s;
使用步驟 2 保存的歸一化參數,在圖像 x?_s 上反轉圖像歸一化結果。最后,借助該研究提出的合成方法,將生成的圖像與圖像 x_t 混合。
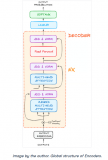
而該流程中,最核心的組件無疑是模型本身了。該研究使用的單編碼器 - 多解碼器網絡架構:
此外,研究者還介紹了實現人臉關鍵點對齊和穩定的方法,以確保換臉圖像的時序一致性,以及保持光照和對比度的圖像合成流程。此處不再贅述,詳情參見原論文。
與當前 SOTA 方法的對比
該方法與 DeepFakes、DeepFaceLab 和 Nirkin 等人提出方法的換臉效果對比。從左到右依次為:目標圖像、源圖像、該方法在 1024×1024 和 256×256 分辨率下的成像效果,以及其他三種方法的成像效果。
控制變量研究
研究者執行以下四種實驗,來查看該研究提出的單編碼器 - 多解碼器網絡架構和算法對換臉質量的影響:
漸進式訓練 VS 一次性訓練整個網絡;
使用多路 comb 模型 VS 單獨的雙路模型;
該研究提出的保持對比度的多頻段合成方法 VS 泊松融合方法;
該研究中人臉關鍵點穩定方法的影響。
為漸進式訓練與非漸進式訓練的成像效果對比,可以看出,漸進式訓練的成像效果優于非漸進式訓練。
為使用多路 comb 模型與雙路模型的成像效果對比:
方法與泊松融合方法的成像效果對比。從圖中可以看出,該方法可以更好地保留目標人臉的全局光照特征,而泊松融合方法導致人臉出現了某種「漂白」效果。
人臉關鍵點穩定結果:
缺陷
盡管能夠以高分辨率進行逼真的人臉轉換,但是迪士尼提出的這一方法仍然存在缺陷。例如,無法基于數據恰當捕獲的表情和姿勢,可能會導致不完善的生成結果,比如模糊和其它偽影。
責任編輯:pj
-
解碼器
+關注
關注
9文章
1173瀏覽量
41950 -
編碼器
+關注
關注
45文章
3793瀏覽量
137976 -
數據
+關注
關注
8文章
7255瀏覽量
91807
發布評論請先 登錄
Transformer架構中解碼器的工作流程
TWL6040 用于便攜式應用的 8 通道高質量低功耗音頻編解碼器數據手冊
解碼未來:數字編碼器如何重塑智能世界


增量式編碼器單圈和多圈怎么知道,如何分辯?
編碼器的作用與信號轉換原理 編碼器與解碼器的關系和作用

無線網解碼器怎么用
無線解碼器的質量標準是什么
磁電編碼器和光電編碼器的區別
解碼器和控制器區別是什么
全景聲解碼器






 工商網監
工商網監
評論