 美國公司構建新型機器學習模型,可從音頻中捕捉到重大安全事故的信息
美國公司構建新型機器學習模型,可從音頻中捕捉到重大安全事故的信息
在美國各大主要城市,市民一天24小時會切到數千個公共第一響應者無線電波,這些信息用于給500多萬用戶提供火災、搶劫和失蹤等突發事件的實時安全警報。每天人們收聽音頻的總時長會超過1000小時,這給需要開發新城市的公司帶來了挑戰。
因此,我們構建了一個機器學習模型,它可以從音頻中捕捉到重大安全事故的信息。
定制的軟件適用無線電(SDR)會捕捉大范圍內的無線電頻率(RF),將優化后的音頻片段發送到ML模型進行標記。標記后的片段會被發送至操作分析員,他們將在app中記錄事件,最后通知事故地點附近的用戶。
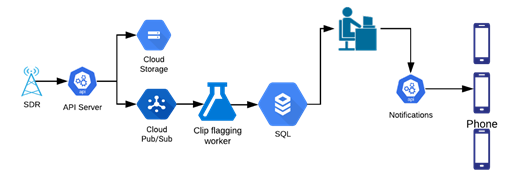
安全警報工作流程(圖自作者)
為適應問題領域,調整一個公共語音轉文本引擎
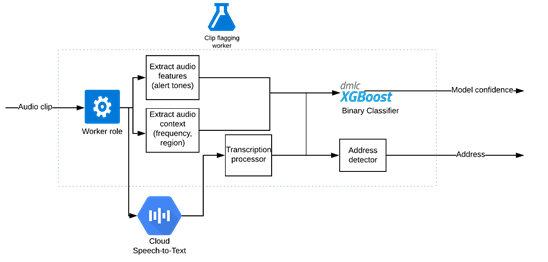
運用公共語音轉文本引擎的剪輯分類器 (圖自作者)
依據單詞錯誤率(WER),我們將從一個性能最好的語音轉文本引擎著手。很多警察使用的特殊代碼都不是白話,例如,紐約警察局官員會發送“信號13”來請求后備部隊。
我們使用語音上下文定制詞匯表。為適應領域,我們還擴充了一些詞匯,例如,“assault”并不通俗,但常見于領域中,模型應檢測出“assault”而不是“a salt”。
調整參數之后,我們能夠在一些城市獲得相對準確的轉錄。接下來,我們要使用音頻片段的轉錄數據,找出哪些與市民相關。
基于轉錄和音頻特征的二值分類器
我們建立了一個二進制分類問題的模型,其中轉錄作為輸入,置信水平作為輸出,XGBoost算法為數據集提供了最好的性能。
我們從一位前執法部門工作人員處了解到,在重大事件的無線電廣播之前,一些城市會發出特殊警報音以引起當地警方的注意。這個“額外”的特征使我們的模型更加可靠,尤其是在轉錄出錯的情況下。其他一些有用的特征是警察頻道和傳輸ID。
我們在操作流程中對ML模型進行了測試。運行了幾天后,我們注意到在事件中,那些只使用帶了模型標記的片段的分析員未出差錯。
我們在幾個城市推出了這種模式。現在一個分析師可以同時處理多個城市的音頻,這在以前是不可能的。隨著投入運營的閑置產能增多,我們得以開發新的城市。
超越公共語音轉文本引擎
這個模型并不是解決所有問題的靈丹妙藥,我們只能在少數幾個音質好的城市使用它。公共語音轉文本引擎是按照聲學剖面不同于收音機的音素模型訓練的,因此,轉錄的質量有時是不可靠的。對于那些非常嘈雜的老式模擬系統來說,轉錄是完全不可用的。
我們嘗試了多個來源的多個模型,但沒有一個是按照與數據集相似的聲學剖面訓練的,全都無法處理嘈雜的音頻。
我們試著用在保證管道其他部分不變的情況下由數據訓練出的語音轉文本引擎,替換原語音轉文本引擎。然而,為了音頻,我們需要幾百小時的轉錄數據,而生成這些數據耗時耗財。
我們還有個優化過程的選擇,就是只抄寫詞匯表中定義為“重要”的單詞,并為不相關的單詞添加空格,但這仍然只是在逐步減少工作量而已。最后,我們決定為問題領域建立一個定制的語音處理管道。
用于關鍵詞識別的卷積神經網絡
因為我們只關心關鍵字,所以并不需要知道單詞正確的順序,由此可簡化問題為關鍵字識別。這就簡單多了,我們決定使用在數據集上訓練的卷積神經網絡(CNN)。
在循環神經網絡(RNNs)或長短期記憶(LSTM)模型之上使用卷積神經網絡(CNN)意味著我們可以更快地訓練和重復。我們評估了Transformer模型,其大致相同,但需要大量硬件才能運行。
由于我們只在音頻段之間尋找短期的依賴關系來檢測單詞,計算簡單的CNN似乎優于Transformer模型,同時它能騰出硬件空間,從而可以通過超參數調整更加靈活。
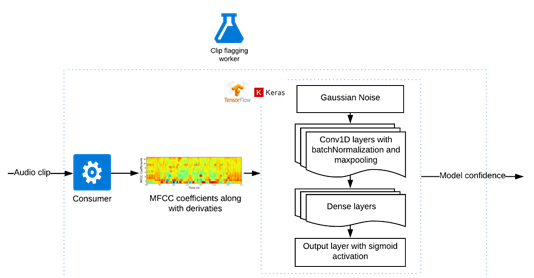
用于識別關鍵字并運用了卷積神經網絡的剪輯標記模型(圖自作者)
音頻片段會被分成固定時長的子片段。如果詞匯表中的一個單詞出現了,該子片段會被加上一個正標簽。然后,如果在某個片段中發現任何這樣的子片段,該音頻片段會被標記為有用。
在訓練過程中,我們嘗試改變子片段的時長以判斷其如何影響融合性能。長的片段讓模型更難確定片段的哪個部分會有用,也讓模型更難調試。短片段意味著部分單詞會出現在多個剪輯中,這使得模型更難識別出它們。調整這個超參數并找到一個合理的時長是能做到的。
對于每個子片段,我們將音頻轉換成梅爾倒譜系數(MFCC),并添加一階和二階導數,特征以25ms的幀大小和10ms的步幅生成。然后,通過Tensorflow后端輸入到基于Keras序列模型的神經網絡中。
第一層是高斯噪聲,這使得模型耐得住不同無線信道之間的噪聲差異。我們嘗試了另一種方法,人為地將真實的噪音疊加到片段上,但這大大放緩了訓練,卻沒有顯著的性能提升。
然后,我們添加了Conv1D、BatchNormalization和MaxPooling1D三個后續層。批處理規范化有助于模型收斂,最大池化有助于使模型耐得住語音和信道噪聲的細微變化。另外,我們試著增加了脫落層,但這些脫落層并未有效改進模型。
最后,添加一個密集連接的神經網絡層,將其注入到一個有著sigmoid函數激活的單一輸出密集層。
生成標記數據
音頻剪輯的標記過程(圖自作者)
為了標記訓練數據,我們把問題領域的關鍵字列給了注釋者,并要求他們如果有詞匯表里的單詞出現,必須為片段標記好開始和結束位置和單詞標簽。
為了確保注釋的可靠性,我們在注釋器之間有10%的重疊,并計算了它們在重疊片段上的表現。一旦有了大約50小時的標記數據就會啟動訓練,我們會在重復訓練的過程中不斷收集數據。
由于詞匯表中的一些單詞比另一些單詞更為常見,模型針對于普通單詞來說表現正常,但是對于僅有較少示例的單詞卻遇到了困難。
我們試圖將單字發音覆蓋在其他片段中,借以人為制造示例。然而,性能的提升與這些單詞的實際標記量不相稱。最終,模型對于常用詞等會更加敏感,我們在未被標記的音頻片段上運行該模型,并消除掉那些含有已習得單詞的片段,這有助于減少未來標記時多余的詞語。
模型的發行
經過幾次重復的數據收集和超參數調整,我們已能訓練出一個對詞匯表里的詞語具有高查全率和精準捕捉能力的模型。高查全率對于捕捉關鍵的安全警報非常重要。標記的片段會在發送警報之前被收聽,因此誤報不是一個大問題。
我們在紐約市的一些區對這個模型進行了測試,該模型能夠將音頻音量降低50–75%(取決于頻道),它明顯超越了我們在公共語音轉文本引擎上訓練的模型,因為紐約由于模擬系統有非常嘈雜的音頻。
令人驚訝的是,盡管模型是根據紐約市的數據訓練的,但它也可以很好地切換到芝加哥的音頻。在收集了幾個小時的芝加哥片段之后,從紐約市模型中學到的東西轉移到芝加哥,該模型也表現良好。
語音處理管道與定制的深度神經網絡廣泛適用于來自美國主要城市的警察音頻。它從音頻中發現了重大的安全事故,使全國范圍的市民能夠迅速向城市廣播,履行保護社區安全的使命。
在RNN、LSTM或Transformer中選擇計算簡單的CNN架構,以及簡化標記過程,這些都是重大的突破,使我們能在限時限材的情況下超越公共語音轉文本模型。
責編AJX
-
音頻
+關注
關注
29文章
3025瀏覽量
83046 -
RF
+關注
關注
65文章
3171瀏覽量
168515 -
機器學習
+關注
關注
66文章
8492瀏覽量
134102
發布評論請先 登錄
云酷人員定位歷史軌跡功能:事故追溯中的關鍵利器與安全管理革命
采用LifeCam運行TIDA-00361_LCr3000程序進行到投影儀標定步驟,如何使LifeCam Cinema相機捕捉到投影儀投射的棋盤格圖像?
KiCad 9 探秘(三):定位與捕捉功能的增強
使用ADS1299EEG-FE analysis-scope捕捉到的波形和user-guide里的參考波形不一致,為什么?
從信號發生器發出一個正弦波到AFE509EVM的信號輸入通道,捕捉的信息很奇怪,為什么?
安森美SmartROI功能在機器視覺中的優勢

android系統使用appe播放audio資源,相關進程被kill之后appe無法再次打開的原因?
構建語音控制機器人 - 線性模型和機器學習
飛凌嵌入式-ELFBOARD 解決PCB布線時無法捕捉到焊盤中心的問題
【《時間序列與機器學習》閱讀體驗】+ 時間序列的信息提取
Keysight InfiniiVision 4000 X 系列示波器






 工商網監
工商網監
評論