 Linux內核:soft lockup是由于什么原因導致的呢?
Linux內核:soft lockup是由于什么原因導致的呢?
提到soft lockup,大家都不會陌生:
BUG:softlockup-CPU#3stuckfor23s![kworker/332]
這個幾乎和panic,oops并列,也是非常難以排查甚至比panic更麻煩。至少panic之后你可以去分析一個靜態的尸體,然而soft lockup,那是一個動態的過程,甚至轉瞬即逝,自帶自愈功能。
那么soft lockup是由于什么原因導致的呢?
幾乎沒有這方面的文章,能找到的也只有個別的案例分析,所以我想趁著周末降至來寫一篇關于soft lockup的通用解釋。
首先澄清兩個關于soft lockup的誤區:
soft lockup并不僅僅是由死循環引起的。
soft lockup并不是說在一段代碼里執行了23秒,22秒。
這里簡單解釋一下上面的兩點。
事實上,死循環并不一定會導致soft lockup,比如Linux內核生命周期內的0號進程就是一個死循環,此外很多的內核線程都是死循環。
此外,更難指望一段代碼可以執行20多秒,要對現代計算機的速度有所概念。
soft lockup發生的真實場景是:
soft lockup是針對單獨CPU而不是整個系統的。
soft lockup指的是發生的CPU上在20秒(默認)中沒有發生調度切換。
第一點無須解釋,下面重點看第二點。
很顯然,只要讓一個CPU在20秒左右的時間內都不發生進程切換,就會觸發soft lockup,這個“20秒內不切換”就是soft lockup發生的根因!
好了,現在我們來看20秒不切換的場景。
死循環的情況
這是最簡單的場景,但細節往往不像看起來那么簡單。比如你寫了一個死循環在內核中執行,它一定會導致soft lockup嗎?
我們來看一個內核死循環:
#include
加載這個模塊,會soft lockup嗎?
我們知道,雖然loop thread是一個死循環,但是它看起來正如一個普通用戶態進程一樣,在執行i++循環的時候,其實是可以被其它task搶占掉的,這是最基本的進程調度的常識。
但是如果你真的去加載這個模塊,你會發現在有些機器上,它確實會soft lockup,但有的機器上不會,這又是為什么?
這里的關鍵在于內核搶占。你看下自己系統內核的配置文件,如果下面的配置打開,意味著上述模塊的死循環不會造成soft lockup:
CONFIG_PREEMPT=y
如果這個配置沒有開,那么便刑不上內核了,因為它在內核態執行,所以沒有誰可以搶占它,進而發生soft lockup。
我們對上述的死循環代碼是否會觸發soft lockup已經很明確了,下面我們看另一種情況。
如果死循環不在內核線程上下文,而是在軟中斷上下文,會怎樣?
很顯然,軟中斷不能被進程搶占,所以一定會soft lockup。
當然,如果真的發生了死循環導致的soft lockup,那肯定是在一個循環代碼中執行超過20秒了,不說20秒,如果無人干涉,200000秒都是有的…
現在我們來看另一種復雜的情況,即timer的情況。在討論timer時,我假設系統的內核搶占是開啟的,這樣更容易分類討論,否則,如果關閉了內核搶占,那么事情會變得更加嚴重。
timer的情況
我們先看下面的timer回調函數:
static void timer_func(unsigned long data){ mdelay(1); mod_timer(&timer, jiffies + 200);}
僅僅執行1ms的函數,它會導致超過20秒不調度切換的soft lockup嗎?
初看,應該不會,但是如果我們詳細看了Linux內核timer的執行原理,就會明白:
pending在一個CPU上的所有過期timer是順序遍歷執行的。
一輪timer的順序遍歷執行是持有自旋鎖的。
這意味著在執行一輪過期timer的過程中,watchdog實時線程將無法被調度從而喂狗,這意味著:
同一CPU上的過期timer積累到一定量,其回調函數的延時之和大于20秒,將會soft lockup。
我們需要進一步了解一下Linux timer的工作機制。
可以把timer的執行過程抽象成下面的邏輯:
run_timers(){ while (now > base.early_jiffies) { for_each_timer(timer, base.list) { detach_timer(timer) forward_early_jiffies(base) call_timer_fn(timer) } }}
很簡單的流程,內核把當前過期的timer執行到結束。run_timers可以在軟中斷上下文中執行,也可以在softirqd內核線程上下文中執行,為了營造soft lockup,我們假設它是在時鐘中斷退出時的軟中斷上下文中執行的(記住之前還有個假設,即系統是開啟內核搶占的!),此時,run_timers不能被watchdog搶占。
如果一個timer中耗時1ms,那么一個循環需要20000個timer遍歷執行,才能湊齊20秒的不能被搶占的時間,進而引發soft lockup。我的天,20000個timer,不可思議!
其實根本就不需要20000個timer,200個足矣!
問題就出現在call_timer_fn,它實際上是調用該timer回調函數的封裝!我們知道,timer回調函數中執行了mod_timer的操作,它的邏輯如下:
mod_timer(timer, expires){ list_add_timer(timer, expires, base.list)}
它事實上是把timer又插回了list,如果我們把這個list看作是一條時間線的話,它事實上只是往后移了expires這么遠的距離:
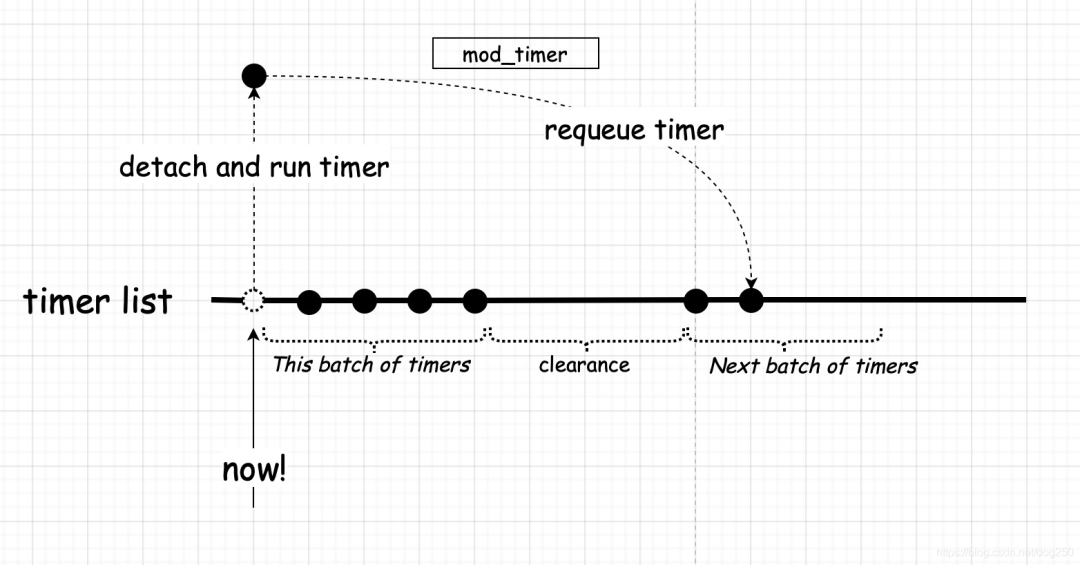
假設所有timer的expire都是固定的常量,如果:
我們的timer的足夠多,多到按照其expires重新requeue時恰好能填補中間的那段空隙。
我們的timer回調函數耗時恰好和timer的expires流逝速率相一致。
那么,兩個甚至多個batch就合并成了一個batch,這意味著一輪timer的執行將不會結束!
我們來試一下:
#include
我的測試虛擬機HZ為1000,這意味1ms將會產生一次時鐘中斷,我們以每個timer函數持鎖執行1ms,一共400個timer來加載模塊,看下結果:
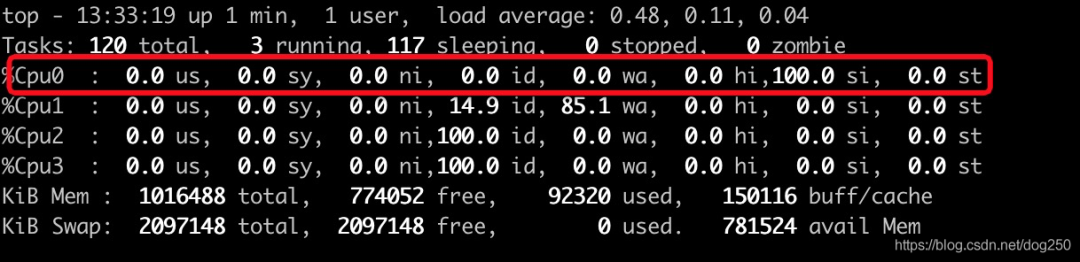
單核跑滿,這意味著timer已經拼接成龍,20秒后,我們將看到soft lockup:
事實上,每個timer回調函數delay 800us,一共200個timer即可觸發soft lockup!使用這個代碼,你基本可以確定你要測試的機器的timer執行時間的安全閾值。
這就是timer導致的soft lockup的動力學。
關于HZ1000
1ms間隔的時鐘中斷對于服務器而言是悲哀的,1ms的時間無法容納太多的timer,也不允許每個timer中有哪怕稍微的合理耗時,1ms一次中斷很容易觸發run_timers在軟中斷上下文中被執行,但很遺憾,這就是事實。
拋開timer不談,HZ1000更多的意義在于快速響應事件而不是增加系統吞吐,這對服務器的單機性能是有傷害的!
說了這么多,現在讓我們考慮一下現實。
除了不要在內核中寫死循環之外,我們也不應該讓timer回調函數執行過久,特別是系統中timer特別多,且expires特別短的情況下。
回到現實中,我們來看一個實例。
假設你使用的內核版本還不支持TCP的lockless listener,那么我們特別要注意一個函數,即inet_csk_reqsk_queue_prune:
這是一個在TCP的per listener的timer中執行的函數。
這個函數的實現采用兩層循環,循環耗時取決于:
外層循環:該listener的backlog大小,受程序配置控制。
內層循環:該listener的半連接隊列的大小,受系統快照控制。
如果系統中的listener特別多,在收到SYN掃描攻擊時,特別容易陷入soft lockup的深淵!幸運的是,這個問題已經在TCP lockless listener的版本中修了,它的效果如下:
將per listener的半連接隊列timer換成了per request timer,減少了回調函數處理耗時。
per request timer增加了timer的數量,會不會抵消縮短回調耗時帶來的收益,需要攻擊來驗證。
我們看一個相關issue和patch:
https://patchwork.ozlabs.org/patch/452426/
好了,再次回到核心主題。
觸發soft lockup的當然不止死循環和timer,我只是用這兩個來說明soft lockup的動力學,即超過2倍的kernel.watchdog_thresh時間不能進行進程調度,就會觸發soft lockup告警。至于說stuck for 23s!那只是表象,并不是如其字面表達的那樣,23秒的時間在執行一段代碼。
此外,頻繁的spinlock,rwlock也會導致soft lockup,我這有一個關于IPv6路由查詢機制的實例,詳情參見:
https://blog.csdn.net/dog250/article/details/91046131
總之,所有的情況將不勝枚舉,也不可能通過一篇文章來展示,所以說,遇到此類問題,還是要有一個明確的排查思路或者說范式,才能快速定位問題的根因并且解決之。
當然了,經理并不關注這些爛八七糟的東西。
-
cpu
+關注
關注
68文章
11041瀏覽量
216051 -
Linux
+關注
關注
87文章
11465瀏覽量
212840
原文標題:Linux內核為什么會發生soft lockup?
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
ADS1118讀取內部溫度傳感器溫度值偏高,有什么原因導致偏高呢?
TLC7135發燙、發熱是什么原因導致的?
電芯抽芯是什么原因導致的
運放輸出失真是什么原因導致的?

程序跑到H723ZGT6的flash擦除那一段命令就死機,什么原因導致的呢?
OPA388低頻振蕩是什么原因導致的?
INA826檢測時出現較大幅度偏移,導致結果偏大或偏小是什么原因導致的呢?
STM32G071KBT6復位引腳震蕩是什么原因導致的?
導致NMEA2000插頭針座變形的原因






 工商網監
工商網監
評論