") 如何利用多個(gè)上下文信息來做同義實(shí)體發(fā)現(xiàn)問題上進(jìn)行了一些新的探索
如何利用多個(gè)上下文信息來做同義實(shí)體發(fā)現(xiàn)問題上進(jìn)行了一些新的探索
命名實(shí)體的同義發(fā)現(xiàn)在許多NLP任務(wù)中起到了重要的作用。同義發(fā)現(xiàn)任務(wù)中一個(gè)核心的問題是如何衡量一對(duì)實(shí)體之間的語義相似度。基于表示學(xué)習(xí)(representation learning)的同義實(shí)體發(fā)現(xiàn)致力于學(xué)習(xí)更好的詞表示(word embedding)或者字符表示(character-level embedding)。這些方法大都可以很好的處理表述相似的同義實(shí)體(例如airplane/aeroplane), 但在衡量語義相似的同義實(shí)體下表現(xiàn)不佳(例如clogged nose/nasal congestion)。近年來,基于上下文(context)的同義實(shí)體發(fā)現(xiàn)多基于分布式語義模型(Distributional Semantics Models)的假設(shè) ,即“在相同的上下文中出現(xiàn)的詞匯在某種程度上有類似的含義“。在實(shí)際應(yīng)用中,一個(gè)命名實(shí)體會(huì)通常出現(xiàn)在許多不同的上下文中。對(duì)于每個(gè)命名實(shí)體,現(xiàn)有基于分布式語義模型的方法大多將單個(gè)上下文的信息拿來做匹配。
IJCAI2020的一篇論文 (“Entity Synonym Discovery via Multipiece Bilateral Context Matching”) 在如何利用多個(gè)上下文信息來做同義實(shí)體發(fā)現(xiàn)問題上進(jìn)行了一些新的探索。作者認(rèn)為對(duì)于一對(duì)命名實(shí)體,若對(duì)每個(gè)實(shí)體能利用多個(gè)不同的上下文來做匹配不僅可以更全面的學(xué)習(xí)其上下文語意表示從而提高衡量實(shí)體之間語義相似度的準(zhǔn)確性,還可以增加匹配的魯棒性,減少因采用某個(gè)低質(zhì)量上下文而引入的噪聲。為了達(dá)到這一目標(biāo),作者在同義詞發(fā)現(xiàn)任務(wù)上將傳統(tǒng)的基于單個(gè)上下文的匹配(single-piece context matching)擴(kuò)展至多個(gè)上下文(multi-piece context),并通過多個(gè)上下文之間的雙向匹配(bilateral context matching) 來學(xué)習(xí)實(shí)體間的相似度,從而用于海量文本中的同義實(shí)體發(fā)現(xiàn)。在公開/特定領(lǐng)域(醫(yī)療),英文/中文文本數(shù)據(jù)集上均取得了較佳的表現(xiàn)。
模型解析
SynonymNet核心idea是對(duì)于每個(gè)命名實(shí)體查找一組(多個(gè))其出現(xiàn)的上下文句子,并通過對(duì)兩組上下文句子之間進(jìn)行匹配得到最終命名實(shí)體間的相似度。那么這樣的匹配要如何實(shí)現(xiàn)呢?
作者采用了如下圖所示的模型結(jié)構(gòu):檢索器 (context retriever)通過檢索的方式從海量文本中選擇一組實(shí)體被提到的句子;編碼器(context encoder)將每一個(gè)上下文信息進(jìn)行編碼; 雙向匹配(bilateral matching)+泄漏單元(leaky unit)則將兩個(gè)實(shí)體對(duì)應(yīng)的兩組上下文信息進(jìn)行雙向匹配;合成器(context aggregation)利用匹配的信息選擇具有代表性,且在匹配中較為informative的上下文信息進(jìn)行多上下文的聚合。作者考慮了兩種不同的架構(gòu):一是針對(duì)二元實(shí)體組 的siamese 結(jié)構(gòu),根據(jù)同義實(shí)體是否匹配進(jìn)行二分類;二是針對(duì)三元實(shí)體組 的triplet 結(jié)構(gòu),希望同義實(shí)體 的得分超過非同義實(shí)體 。
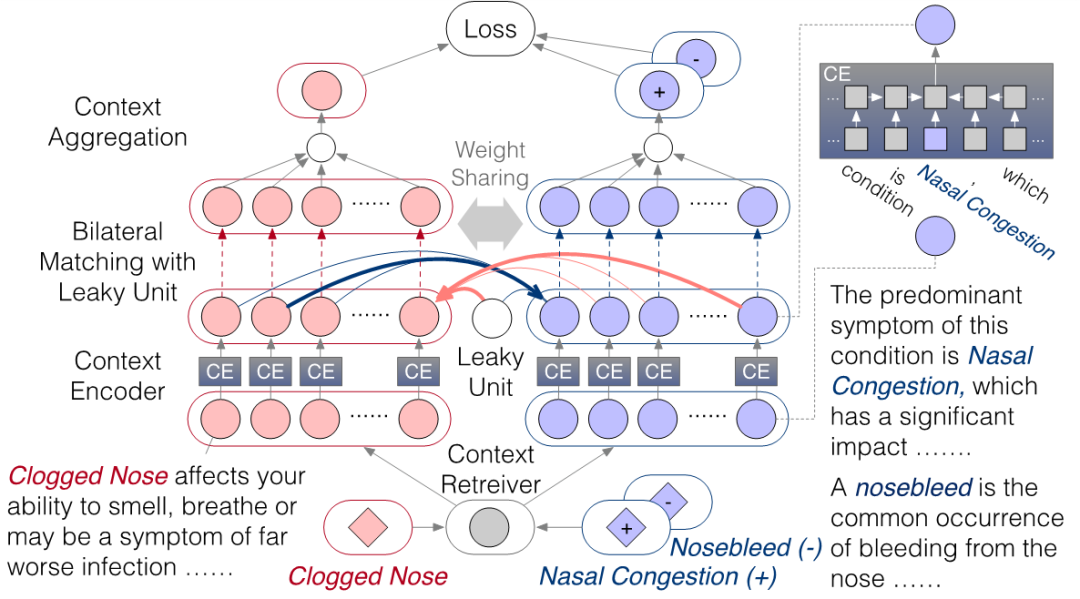
雙向匹配。
對(duì)于一組命名實(shí)體 , 上下文檢索+編碼將器將 轉(zhuǎn)化為了兩組上下文的向量:
對(duì)于每個(gè)提到實(shí)體 的上下文向量 , 作者用bi-linear項(xiàng)來計(jì)算和每一個(gè)提到實(shí)體 的上下文向量 的匹配分?jǐn)?shù):
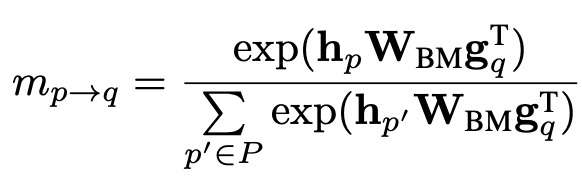
同樣的,對(duì)于每一個(gè)提到實(shí)體 的上下文向量,作者也利用相同的方式計(jì)算匹配分?jǐn)?shù):
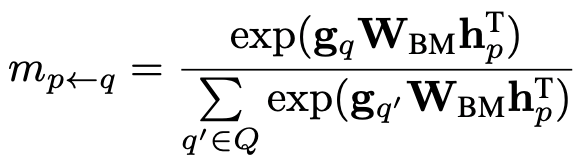
這樣的匹配看似需要進(jìn)行 次,但在實(shí)際實(shí)現(xiàn)中可以通過矩陣乘法進(jìn)行高效計(jì)算:,并通過按行/列取softmax得到兩個(gè)方向的匹配分?jǐn)?shù)。
泄露單元。
當(dāng)需要和多個(gè)上下文進(jìn)行匹配的時(shí)候,可能會(huì)存在沒有高質(zhì)量的上下文進(jìn)行匹配,甚至上下文存在錯(cuò)誤的情況。為了更好的解決這個(gè)問題,作者引入了泄漏單元(leaky unit)的概念。Leaky unit的想法是在雙向匹配時(shí)引入一個(gè)多余的上下文向量 。該向量可以隨模型學(xué)習(xí),目的是為了在沒有高質(zhì)量上下文匹配時(shí)承擔(dān)一些匹配的分?jǐn)?shù),從而減弱低質(zhì)量上下文在匹配過程中帶來的噪聲和干擾。
在每個(gè)匹配方向上,Leaky unit會(huì)額外和/個(gè)上下文向量計(jì)算匹配分?jǐn)?shù):
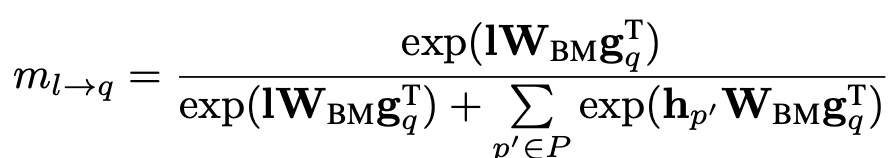
當(dāng)存在某個(gè)低質(zhì)量的上下文,比如因?yàn)閷?shí)體 在句子語義成分中不重要時(shí),其對(duì)應(yīng)的上下文向量 在和提到實(shí)體 的 個(gè)上下文向量進(jìn)行匹配時(shí):
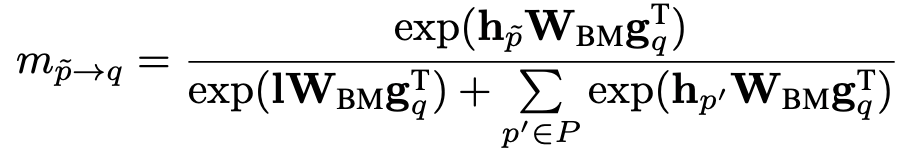
分母中的泄漏單元會(huì)承擔(dān)匹配分?jǐn)?shù); 會(huì)減弱該 在上下文在匹配時(shí)的影響。橫向比較上方兩個(gè)公式的分子:當(dāng) > 時(shí),泄漏單元會(huì)比低質(zhì)量的上下文在匹配中更活躍,占用額外的匹配分?jǐn)?shù),從而減弱低質(zhì)量上下文在匹配時(shí)的分?jǐn)?shù)。
上下文信息聚合。
作者將多個(gè)上下文基于attention思想進(jìn)行聚合。當(dāng)已經(jīng)獲得了 個(gè)上下文之間的匹配分?jǐn)?shù)后,作者認(rèn)為某一個(gè)上下文 在 個(gè)上下文聚合過程中的重要的程度取決于在與另一邊 個(gè)上下文匹配時(shí)最被需要的程度:
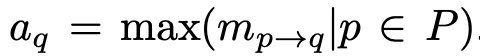
這里的動(dòng)機(jī)是如果 個(gè)上下文和 匹配時(shí)最高的匹配分?jǐn)?shù)已經(jīng)很低,那么可以說明 在整個(gè)匹配過程中不夠informative,聚合時(shí)應(yīng)當(dāng)給較小的attention;反之,如果 在和 個(gè)上下文匹配時(shí)最高的匹配分?jǐn)?shù)很高,那么可以說明 在匹配過程中非常被需要。作為informative的上下文 在聚合時(shí)應(yīng)當(dāng)?shù)玫礁蟮腶ttention。基于這個(gè)思路,聚合時(shí)采用了基于最強(qiáng)匹配分?jǐn)?shù)進(jìn)行的attention聚合,得到聚合后的上下文向量:
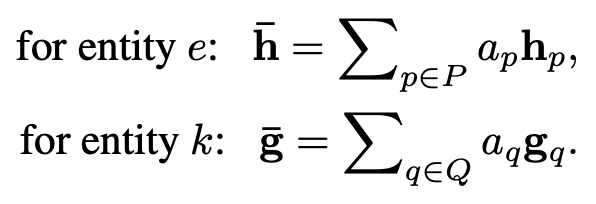
泄漏單元雖然在匹配時(shí)分擔(dān)了匹配分?jǐn)?shù),但泄漏單元不參與聚合過程。因此泄漏單元不會(huì)在聚合過程中貢獻(xiàn)信息給聚合后的上下文向量。這樣是為了保證泄露的噪聲能被隔離開,不去影響最終聚合的質(zhì)量。
siamese/triplet 結(jié)構(gòu)。
作者嘗試了兩種不同的模型結(jié)構(gòu)/損失函數(shù)。siamese 結(jié)構(gòu)以二元實(shí)體組 作為輸入,損失函數(shù)利用聚合后的上下文向量刻畫兩個(gè)實(shí)體同義與否。triplet結(jié)構(gòu)以三元實(shí)體組作為輸入,損失函數(shù)利用聚合后的上下文向量希望同義實(shí)體比非同義實(shí)體獲得更高的分?jǐn)?shù): 大于一個(gè)margin。
實(shí)體發(fā)現(xiàn)流程
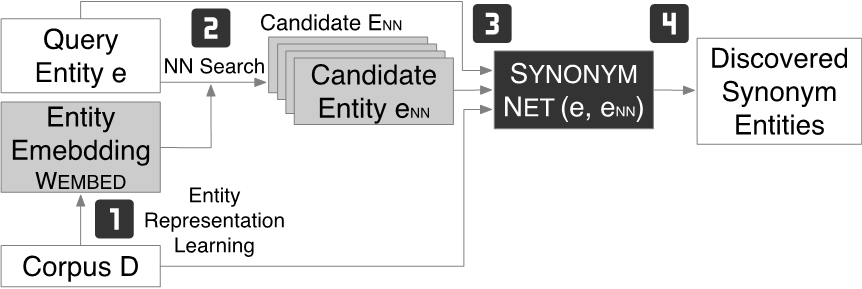
作者利用SynonymNet衡量實(shí)體間語義相似度的能力將其用于文本中的實(shí)體發(fā)現(xiàn)。如圖所示,實(shí)體發(fā)現(xiàn)分為四步:1)根據(jù)文本訓(xùn)練word embedding;2)對(duì)于一個(gè)query entity , 通過其在embedding space上的 最近鄰獲得candidate entity;3)對(duì)于 < query entity, candidate entity > 利用SynonymNet獲得相似度分?jǐn)?shù);4)最后根據(jù)SynonymNet分?jǐn)?shù)獲得同義實(shí)體對(duì)。
實(shí)驗(yàn)表現(xiàn)
作者在Wiki + Freebase, PubMed + UMLS, MedBook + MKG 三個(gè)數(shù)據(jù)集上進(jìn)行了評(píng)估。實(shí)驗(yàn)采用AUC和MAP評(píng)價(jià)采用相同的word embedding時(shí)不同模型結(jié)構(gòu)對(duì)于衡量實(shí)體同義相似度的影響。
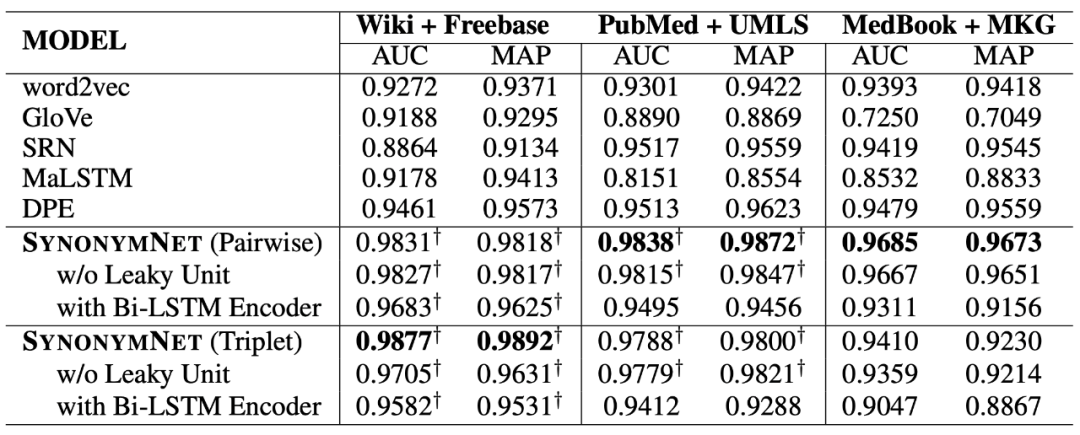
作者對(duì)上下文個(gè)數(shù)對(duì)性能的影響進(jìn)行了評(píng)估。結(jié)果顯示采用多個(gè)上下文進(jìn)行匹配可以降低單個(gè)上下文匹配時(shí)可能帶來的噪聲,從而顯著提高同義相似度的準(zhǔn)確性。
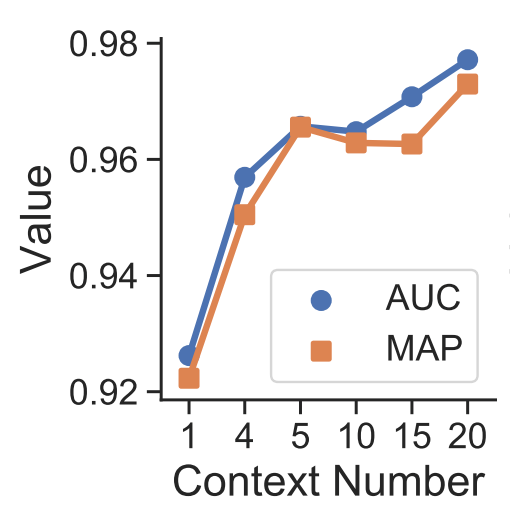
作者還在真實(shí)的同義實(shí)體發(fā)現(xiàn)任務(wù)中進(jìn)行了一些分析。word2vec采用了利用上下文來對(duì)實(shí)體語義進(jìn)行建模的思想,用cosine similarity進(jìn)行embedding最近鄰選取可以得到初篩后的candidate entity。對(duì)于query entity “UNGA”,獲得的candidates雖然大多出現(xiàn)在類似的上下文中,不相關(guān)的實(shí)體仍在前列。經(jīng)過SynonymNet對(duì)于上下文更細(xì)粒度的刻畫,以及多上下文的雙向匹配后,同義實(shí)體的排名變得更靠前了。
總結(jié)
根據(jù)多個(gè)上下文進(jìn)行雙向匹配來確定兩個(gè)實(shí)體同義程度,利用泄漏單元來處理多個(gè)上下文匹配時(shí)可能存在噪音的情況,思路直觀,實(shí)現(xiàn)的方式簡潔。實(shí)驗(yàn)結(jié)果上驗(yàn)證了采用多個(gè)上下文進(jìn)行匹配來帶準(zhǔn)確度和魯棒性上的提升。
該框架對(duì)于編碼器,檢索器的選擇比較靈活。目前文中采用的是bi-LSTM結(jié)構(gòu),和基于transformer的眾多預(yù)訓(xùn)練語言模型碰撞之后說不定也能有一些新的發(fā)現(xiàn)。在需要用多個(gè)上下文進(jìn)行匹配的時(shí)候,如何利用多個(gè)上下文帶來的多樣性,全面地學(xué)習(xí)實(shí)體表示也是一個(gè)很有意思的問題。在處理由之產(chǎn)生的噪聲方面,文中的泄漏單元給出了一個(gè)比較新穎的觀點(diǎn)。
-
編碼器
+關(guān)注
關(guān)注
45文章
3772瀏覽量
137114 -
模型
+關(guān)注
關(guān)注
1文章
3483瀏覽量
49980 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1222瀏覽量
25273
原文標(biāo)題:SynonymNet: 基于多個(gè)上下文雙向匹配的同義實(shí)體發(fā)現(xiàn)
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
編寫一個(gè)任務(wù)調(diào)度程序,在上下文切換后遇到了一些問題求解
關(guān)于進(jìn)程上下文、中斷上下文及原子上下文的一些概念理解
進(jìn)程上下文與中斷上下文的理解
中斷中的上下文切換詳解
基于交互上下文的預(yù)測方法
終端業(yè)務(wù)上下文的定義方法及業(yè)務(wù)模型
基于Pocket PC的上下文菜單實(shí)現(xiàn)
基于Pocket PC的上下文菜單實(shí)現(xiàn)
基于上下文相似度的分解推薦算法
基于低秩重檢測的多特征時(shí)空上下文的視覺跟蹤
Web服務(wù)的上下文的訪問控制策略模型
初學(xué)OpenGL:什么是繪制上下文
如何用上下文注意力來進(jìn)行深度圖像修復(fù)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論