 機器學習算法基礎與流程
機器學習算法基礎與流程

一、什么是機器學習
1. 含義
機器學習machine learning,是人工智能的分支,專門研究計算機怎樣模擬或實現人類的學習行為,其通過各種算法訓練模型,并用這些模型對新問題進行識別與預測。
本質上機器學習是一種從數據或以往的經驗中提取模式,并以此優化計算機程序的性能標準。
2. 解決什么問題
解決復雜規則的問題。如果簡單規則可以實現,則沒必要借助機器學習算法實現。
2009年ACM世界冠軍戴文淵加入百度的時候,百度所有的搜索、廣告都是基于1萬條的專家規則。借助于機器算法,戴文淵把百度廣告的規則從1萬條提升到了1000億條。與此相對應的,百度的收入在四年內提升了八倍。
3. 三個名詞之間的關系
人工智能》機器學習》深度學習
以機器學習算法是否應用了神經網絡作為區分標準,應用了多隱含層神經網絡的機器學習就是深度學習。
4. 對AI產品經理的要求
熟悉機器學習流程(詳見文章第三部分);
了解機器學習可以解決的問題分類(詳見文章第四部分);
了解算法的基本原理;
了解工程實踐中算數據和計算資源三者間的依賴關系等。
二、機器學習的基礎
1. 機器學習的基礎——數據
人工智能產品由數據、算法、計算能力三部分組成,而數據,是其中的基礎。
全球頂尖人工智能科學家李飛飛的成功離不開ImageNet千萬級的數據集。
“ImageNet 讓 AI 領域發生的一個重大變化是,人們突然意識到構建數據集這個苦活累活是 AI 研究的核心,”李飛飛說: “人們真的明白了,數據集跟算法一樣,對研究都至關重要。”“如果你只看 5 張貓的照片,那么你只知道這 5 個攝像機角度、照明條件和最多 5 種不同種類的貓。但是,如果你看過 500 張貓的照片,你就能從更多的例子中發現共同點。”
數據量多大為好?
千級別:基本要求,可以解決簡單手寫體數字識別問題,例如MNIST;
萬級別:一般要求,可以解決圖片分類問題,例如cifar-100;
千萬級:比較好,例如ImageNet,準確率2%左右,超過了人類5.1%。
2. 數據的衡量
人工智能產品對數據除了有量的要求,還有質的要求,衡量數據質量的標準包括四個R:關聯度relevancy(首要因素)、可信性reliability(關鍵因素)、范圍range、時效性recency。
數據獲取地址:
ICPSR:www.icpsr.umich.edu
美國政府開放數據:www.data.gov
加州大學歐文分校:archive.ics.uci.edu/ml
數據堂:www.datatang.com
三、機器學習的流程
機器學習的流程可以劃分為以下幾個主要步驟:目標定義、數據收集、數據預處理、模型訓練、準確率測試、調參、模型輸出。
機器學習流程拆解:
1. 目標定義
確認機器學習要解決的問題本質以及衡量的標準。
機器學習的目標可以被分為:分類、回歸、聚類、異常檢測等。
2. 數據采集
原始數據作為機器學習過程中的輸入來源是從各種渠道中被采集而來的。
3. 數據預處理
普通數據挖掘中的預處理包括數據清洗、數據集成、數據轉換、數據削減、數據離散化。
深度學習數據預處理包含數據歸一化(包含樣本尺度歸一化、逐樣本的均值相減、標準化)和數據白化。需要將數據分為三種數據集,包括用來訓練模型的訓練集(training set),開發過程中用于調參(parameter tuning)的驗證集(validation set)以及測試時所使用的測試集(test set)。
數據標注的質量對于算法的成功率至關重要。
4. 模型訓練
模型訓練流程:每當有數據輸入,模型都會輸出預測結果,而預測結果會用來調整和更新W和B的集合,接著訓練新的數據,直到訓練出可以預測出接近真實結果的模型。
5. 準確率測試
用第三步數據預處理中準備好的測試集對模型進行測試。
6. 調參
參數可以分為兩類,一類是需要在訓練(學習)之前手動設置的參數,即超參數(hypeparameter),另外一類是通常不需要手動設置、在訓練過程中可以被自動調整的參數(parameter)。
調參通常需要依賴經驗和靈感來探尋其最優值,本質上更接近藝術而非科學,是考察算法工程師能力高低的重點環節。
7. 模型輸出
模型最終輸出應用于實際應用場景的接口或數據集。
四、算法分類
機器學習囊括了多種算法,通常按照模型訓練方式和解決任務的不同進行分類。
1. 按照模型訓練方式不同,可以分為
(1)監督學習supervised learning
定義:監督學習指系統通過對帶有標記信息的訓練樣本進行學習,以盡可能準確地預測未知樣本的標記信息。
常見的監督學習類算法包括:人工神經網絡artificial neural network、貝葉斯bayesian、決策樹decision tree、線性分類器linear classifier(svm支持向量機)等。
(2)無監督學習unsupervised learning
定義:無監督學習指系統對沒有標記信息的訓練樣本進行學習,以發現數據中隱藏的結構性知識。
常見的無監督學習類算法包括:人工神經網絡artificial neural network、關聯規則學習association rule learning、分層聚類hierarchical clustering、聚類分析cluster analysis、異常檢測anomaly detection等。
(3)半監督學習semi-supervised learning
含義:半監督學習指系統在學習時不僅有帶有標記信息的訓練樣本,還有部分標記未知信息的訓練樣本。
常見的半監督學習算法包括:生成模型generative models、低密度分離low-density separation、基于圖形的方法graph-based methods、聯合訓練co-training等。
(4)強化學習reinforcement learning
定義:強化學習指系統從不標記信息,但是會在具有某種反饋信號(即瞬間獎賞)的樣本中進行學習,以學到一種從狀態到動作的映射來最大化累積獎賞,這里的瞬時獎賞可以看成對系統的某個狀態下執行某個動作的評價。
常見的強化學習算法包括:Q學習Q-learning、狀態-行動-獎勵-狀態-行動state-action-reward-state-action,SARSA、DQN deep Q network、策略梯度算法policy gradients、基于模型強化學習model based RL、時序差分學習temporal different learning等。
(5)遷移學習transfer learning
定義:遷移學習指通過從已學習的相關任務中轉移知識來改進學習的新任務,雖然大多數機器學習算法都是為了解決單個任務而設計的,但是促進遷移學習的算法的開發是機器學習社區持續關注的話題。
遷移學習對人類來說很常見,例如,我們可能會發現學習識別蘋果可能有助于識別梨,或者學習彈奏電子琴可能有助于學習鋼琴。
常見的遷移學習算法包括:歸納式遷移學習inductive transfer learning、直推式遷移學習transductive transfer learning、無監督式遷移學習unsupervised transfer learning、傳遞式遷移學習transitive transfer learning等。
(6)深度學習deep learning
定義:深度學習是指多層的人工神經網絡和訓練它的方法。一層神經網絡會把大量矩陣數字作為輸入,通過非線性激活方法取權重,再產生另一個數據集合作為輸出。
這就像生物神經大腦的工作機理一樣,通過合適的矩陣數量,多層組織鏈接一起,形成神經網絡“大腦”進行精準復雜的處理,就像人們識別物體標注圖片一樣。
常見的深度學習算法包括:深度信念網絡deep belief machines、深度卷積神經網絡deep convolutional neural networks、深度遞歸神經網絡deep recurrent neural networks、深度波爾茲曼機deep boltzmann machine,DBM、棧式自動編碼器stacked autoencoder、生成對抗網絡generative adversarial networks等。
遷移學習與半監督學習的區別:遷移學習的初步模型是完整的,半監督學習的已標注部分無法形成完整的模型。
2. 按照解決任務的不同分類,可以分為
(1)二分類算法two-class classification,解決非黑即白的問題。
(2)多分類算法muti-class classification,解決不是非黑即白的多種分類問題。
(3)回歸算法regression,回歸問題通常被用來預測具體的數值而非分類。除了返回的結果不同,其他方法與分類問題類似。我們將定量輸出,或者連續變量預測稱為回歸;將定性輸出,或者離散變量預測稱為分類。
(4)聚類算法clustering,聚類的目標是發現數據的潛在規律和結構。聚類通常被用做描述和衡量不同數據源間的相似性,并把數據源分類到不同的簇中。
(5)異常檢測anomaly detection,異常檢測是指對數據中存在的不正常或非典型的分體進行檢測和標志,有時也稱為偏差檢測。異常檢測看起來和監督學習問題非常相似,都是分類問題。都是對樣本的標簽進行預測和判斷,但是實際上兩者的區別非常大,因為異常檢測中的正樣本(異常點)非常小。
3. 對AI產品經理的要求
產品經理應了解和掌握每種常見算法的基本邏輯、最佳使用場景以及每種算法對數據的需求。
這樣有助于:
建立必要的知識體系以與研發人員進行良好的交流;
在團隊需要的時候提供必要的幫助;
識別和評估產品迭代過程中的風險、成本、預期效果等。
五、各類算法的對比
1. 算法與學習過程的對比
監督學習——上課:有求知欲的學生從老師那里獲取知識、信息,老師提供對錯指示、告知最終答案的學習過程;
無監督學習——自習:沒有老師的情況下,學生自習的過程;
強化學習下——自測:沒有老師提示的情況下,自己對預測的結果進行評估的方法。
2. 算法適用場景的影響因素
業務核心問題;
數據大小、質量;
計算時間要求;
算法精度要求。
3. 算法優缺點及適用場景
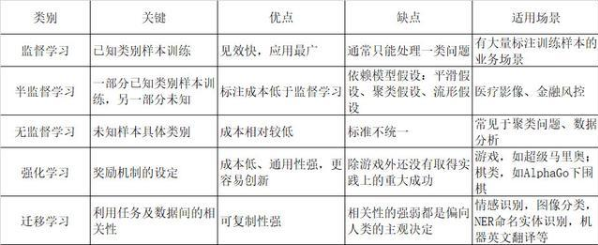
注意:
(1)目前監督學習和強化學習是目前應用范圍最廣且效果最好的機器學習方式。
(2)深度學習將在后續的文章中單獨介紹。
(3)半監督學習依賴以下3個模型假設才能確保它良好的學習性能。
1)平滑假設(Smoothness Assumption)
位于稠密數據區域的兩個距離很近的樣例的類標簽相似,當兩個樣例北稀疏區域分開時,它們的類標簽趨于不同。
2)聚類假設(Cluster Assumption)
當兩個樣例位于同一聚類簇時,它們在很大的概率在有相同的類標簽。這個假設的等價定義為低密度分類假設(Low Density Separation Assumption),即分類決策邊界應該穿過稀疏數據區域,而避免將稠密數據區域的樣例劃分到決策邊界兩側。
3)流形假設(Manifold Assumption)
將高維數據嵌入到低維流形中,當兩個樣例位于低維流形中的一個小局部鄰域內時,它們具有相似的類標簽。
-
人工智能
+關注
關注
1806文章
49028瀏覽量
249503 -
機器學習
+關注
關注
66文章
8503瀏覽量
134614
發布評論請先 登錄
FPGA在機器學習中的具體應用
【「# ROS 2智能機器人開發實踐」閱讀體驗】視覺實現的基礎算法的應用
機器學習模型市場前景如何
算法加速的概念、意義、流程和應用
華為云 Flexus X 實例部署安裝 Jupyter Notebook,學習 AI,機器學習算法
傳統機器學習方法和應用指導

如何選擇云原生機器學習平臺
什么是機器學習?通過機器學習方法能解決哪些問題?

NPU與機器學習算法的關系
LSTM神經網絡與其他機器學習算法的比較
人工智能、機器學習和深度學習存在什么區別

LIBS結合機器學習算法的江西名優春茶采收期鑒別






 工商網監
工商網監
評論