 中國博士生Liyuan Liu提出了一個新的優化器RAdam
中國博士生Liyuan Liu提出了一個新的優化器RAdam
但是魚和熊掌不可兼得。Adam、RMSProp這些算法雖然收斂速度很快,當往往會掉入局部最優解的“陷阱”;原始的SGD方法雖然能收斂到更好的結果,但是訓練速度太慢。
最近,一位來自UIUC的中國博士生Liyuan Liu提出了一個新的優化器RAdam。
它兼有Adam和SGD兩者的優點,既能保證收斂速度快,也不容易掉入局部最優解,而且收斂結果對學習率的初始值非常不敏感。在較大學習率的情況下,RAdam效果甚至還優于SGD。
RAdam意思是“整流版的Adam”(Rectified Adam),它能根據方差分散度,動態地打開或者關閉自適應學習率,并且提供了一種不需要可調參數學習率預熱的方法。
一位Medium網友Less Wright在測試完RAdam算法后,給予了很高的評價:
RAdam可以說是最先進的AI優化器,可以永遠取代原來的Adam算法了。
目前論文作者已將RAdam開源,FastAI現在已經集成了RAdam,只需幾行代碼即可直接調用。
補眾家之短
想造出更強的優化器,就要知道前輩們的問題出在哪:
像Adam這樣的優化器,的確可以快速收斂,也因此得到了廣泛的應用。
但有個重大的缺點是不夠魯棒,常常會收斂到不太好的局部最優解 (Local Optima) ,這就要靠預熱(Warmup)來解決——
最初幾次迭代,都用很小的學習率,以此來緩解收斂問題。
為了證明預熱存在的道理,團隊在IWSLT’14德英數據集上,測試了原始Adam和帶預熱的Adam。
結果發現,一把預熱拿掉,Transformer語言模型的訓練復雜度 (Perplexity) ,就從10增到了500。
另外,BERT預訓練也是差不多的情況。
為什么預熱、不預熱差距這樣大?團隊又設計了兩個變種來分析:
缺乏樣本,是問題根源
一個變種是Adam-2k:
在前2000次迭代里,只有自適應學習率是一直更新的,而動量 (Momentum) 和參數都是固定的。除此之外,都沿襲了原始Adam算法。
實驗表明,在給它2000個額外的樣本來估計自適應學習率之后,收斂問題就消失了:

另外,足夠多的樣本可以避免梯度分布變扭曲 (Distorted) :
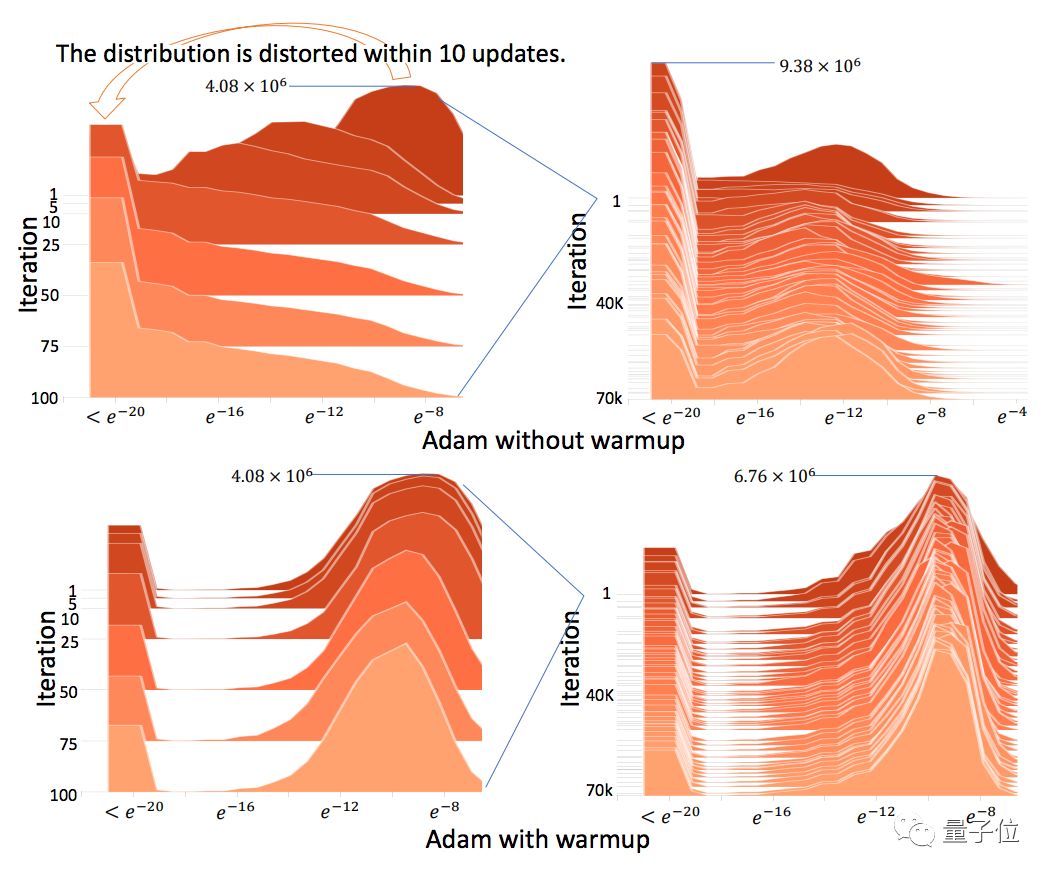

這些發現證明了一點:早期缺乏足夠數據樣本,就是收斂問題的根源。
下面就要證明,可以通過降低自適應學習率的方差來彌補這個缺陷。
降低方差,可解決問題
一個直接的辦法就是:
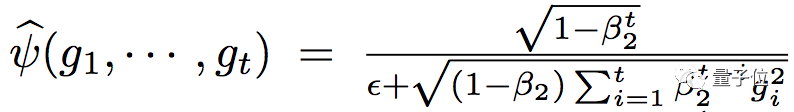
把ψ-cap里面的?增加。假設ψ-cap(. ) 是均勻分布,方差就是1/12?^2。
這樣就有了另一個變種Adam-eps。開始把?設成一個可以忽略的1×10^-8,慢慢增加,到不可忽略的1×10^-4。
從實驗結果看,它已經沒有Adam原本的收斂問題了:
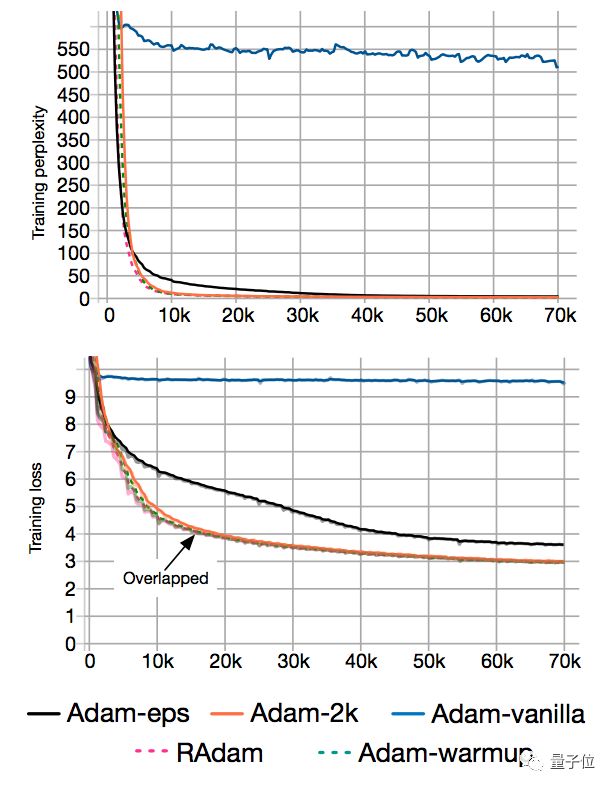
這就證明了,真的可以通過控制方差來解決問題。另外,它和Adam-2k差不多,也可以避免梯度分布扭曲。
然而,這個模型表現比Adam-2k和帶預熱的Adam差很多。
推測是因為?太大,會給自適應學習率帶來重大的偏差 (Bias) ,也會減慢優化的過程。
所以,就需要一個更加嚴格的方法,來控制自適應學習率。
論文中提出,要通過估算自由度ρ來實現量化分析。
RAdam定義
RAdam算法的輸入有:步長αt;衰減率{β1, β2},用于計算移動平均值和它的二階矩。
輸出為θt。
首先,將移動量的一階矩和二階矩初始化為m0,v0,計算出簡單移動平均值(SMA)的最大長度ρ∞←2/(1-β2)-1。
然后按照以下的迭代公式計算出:第t步時的梯度gt,移動量的二階矩vt,移動量的一階矩mt,移動偏差的修正和SMA的最大值ρt。

如果ρ∞大于4,那么,計算移動量二階矩的修正值和方差修正范圍:

如果ρ∞小于等于4,則使用非自適應動量更新參數:
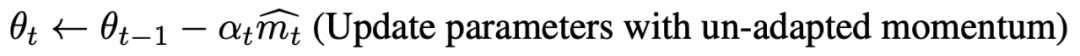
以上步驟都完成后,得出T步驟后的參數θT。
測試結果
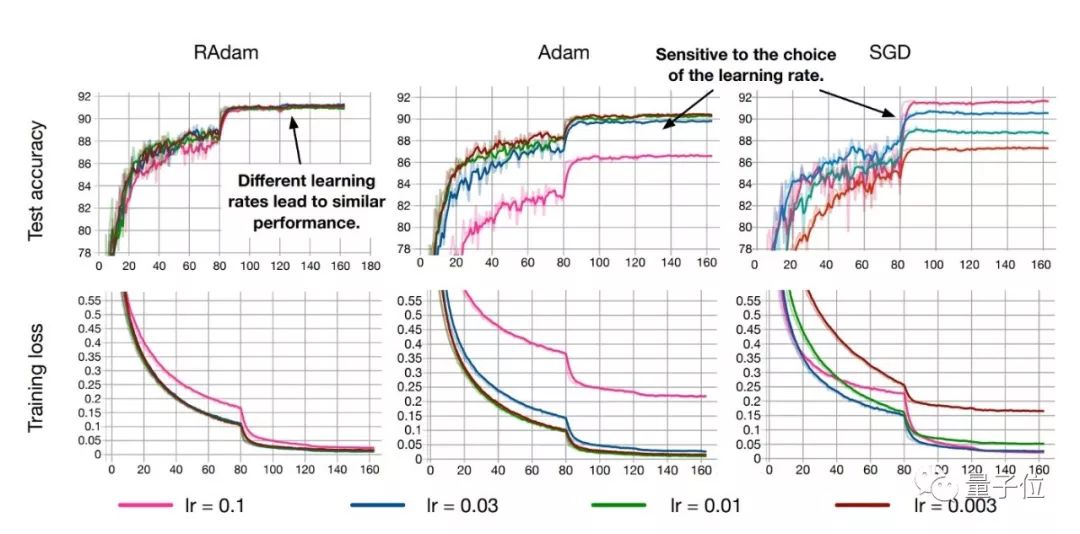
RAdam在圖像分類任務CIFAR-10和ImageNet上測試的結果如下:
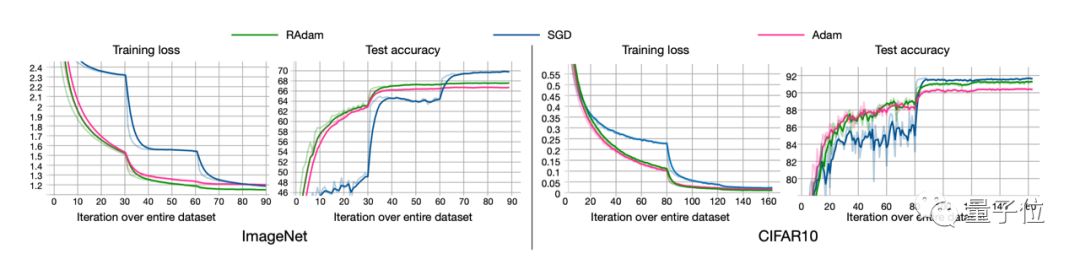
盡管在前幾個周期內整流項使得RAdam比Adam方法慢,但是在后期的收斂速度是比Adam要更快的。
盡管RAdam在測試精度方面未能超越SGD,但它可以帶來更好的訓練性能。
此外,RAdam算法對初始學習率是具有魯棒性的,可以適應更寬范圍內的變化。在從0.003到0.1一個很寬的范圍內,RAdam表現出了一致的性能,訓練曲線末端高度重合。
親測過的網友Less Wright說,RAdam和他今年測試的許多其它論文都不一樣。
其他方法常常是在特定數據集上有良好的效果,但是放在新的數據集上往往表現不佳。
而RAdam在圖像分類、語言建模,以及機器翻譯等等許多任務上,都證明有效。
(也側面說明,機器學習的各類任務里,廣泛存在著方差的問題。)
Less Wright在ImageNette上進行了測試,取得了相當不錯的效果(注:ImageNette是從ImageNet上抽取的包含10類圖像的子集)。在5個epoch后,RAdam已經將準確率快速收斂到86%。
如果你以為RAdam只能處理較小數據集上的訓練,或者只有在CNN上有較好的表現就大錯特錯了。即使大道有幾十億個單詞的數據集的LSTM模型,RAdam依然有比Adam更好的表現。
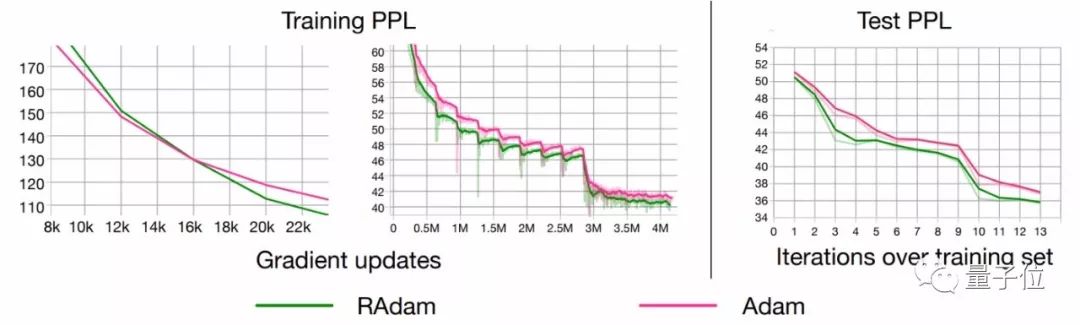
總之,RAdam有望提供更好的收斂性、訓練穩定性,以及幾乎對所有AI應用都用更好的通用性。
關于作者
論文的作者Liyuan Liu是一位90后,本科畢業于中國科學技術大學,曾在微軟亞洲研究院實習。而這項工作,也得益于與微軟的合作。
早在本科期間,Liyuan Liu就師從國家杰出青年基金獲得者,中科大陳恩紅教授,以第一作者的身份在ICDM發表過文章。
2016年,Liyuan Liu小哥本科畢業,加入了美國伊利諾伊大學香檳分校數據挖掘小組(DMG),成為美國計算機協會和IEEE院士韓家煒教授課題組的一名CS博士,從事NLP研究。
讀博以來,Liyuan Liu開始在各大頂會上嶄露頭角。在2018年NLP領域國際頂會EMNLP當中,他的一作論文《Efficient Contextualized Representation: Language Model Pruning for Sequence Labeling》就被收錄為口頭報告。
又是一位閃閃發光的少年英才啊。
論文地址:
https://arxiv.org/abs/1908.03265v1
源代碼:
https://github.com/LiyuanLucasLiu/RAdam
-
AI
+關注
關注
87文章
34274瀏覽量
275449 -
開源
+關注
關注
3文章
3612瀏覽量
43491
原文標題:中國博士生提出最先進AI訓練優化器,收斂快精度高,網友親測:Adam可以退休了
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
VirtualLab 應用:傾斜光柵的參數優化及公差分析
DEKRA德凱林一墨博士榮獲TIC理事會“Merit Award for Advocacy”獎項

開關電源設計指南(完整版)
漢陽大學:研發自供電、原材料基傳感器,開啟人機交互新篇章
南京理工在計算光學顯微成像領域重要研究進展
70多位博士生相聚浙江臺州,只為這行業傳感技術創新
京微齊力受邀參加2024年清華大學工程博士論壇
2024第二屆“必易微杯”ADC芯片設計切磋營圓滿結束
當前主流的大模型對于底層推理芯片提出了哪些挑戰
福祿克公司助力北京交通大學畢業實習活動
2024“一生一芯”暑期宣講會圓滿成功

矽速科技宣布認可“一生一芯”計劃CBAS新認證體系,獲認證同學自動獲得開源實習生聯合培養工程的實習OF

“一生一芯”廈門基地正式啟動
新能源電動汽車充電樁的設計與優化





 工商網監
工商網監
評論