") Adam模型的新改進(jìn)“Rectified Adam”
Adam模型的新改進(jìn)“Rectified Adam”

UIUC華人博士生團(tuán)隊提出了對常用機(jī)器學(xué)習(xí)模型優(yōu)化器Adam的新改進(jìn)RAdam,省去了使用Adam必須的“預(yù)熱”環(huán)節(jié),既能保證學(xué)習(xí)率和收斂速度,又能有效避免模型陷入“局部最優(yōu)解”的陷阱,堪稱Adam的優(yōu)秀接班人!
近日,UIUC的華人博士生Liyuan Liu等人的一篇新論文中介紹了Adam模型的新改進(jìn)“Rectified Adam”(簡稱RAdam)。這是基于原始Adam作出的改進(jìn),它既能實現(xiàn)Adam快速收斂的優(yōu)點,又具備SGD方法的優(yōu)勢,令模型收斂至質(zhì)量更高的結(jié)果。
有國外網(wǎng)友親測,效果拔群。
以下是網(wǎng)友測試過程和RAdam的簡介:
我已經(jīng)在FastAI框架下測試了RAdam,并快速獲得了高精度新記錄,而不是ImageNette上兩個難以擊敗的FastAI排行榜得分。我今年測試了許多論文中的模型,大部分模型似乎在文中給出的特定數(shù)據(jù)集上表現(xiàn)良好,而在我嘗試的新的數(shù)據(jù)集上表現(xiàn)不佳。但RAdam不一樣,看起來真的實現(xiàn)了性能提升,可能成為vanilla Adam的永久“接班人”。
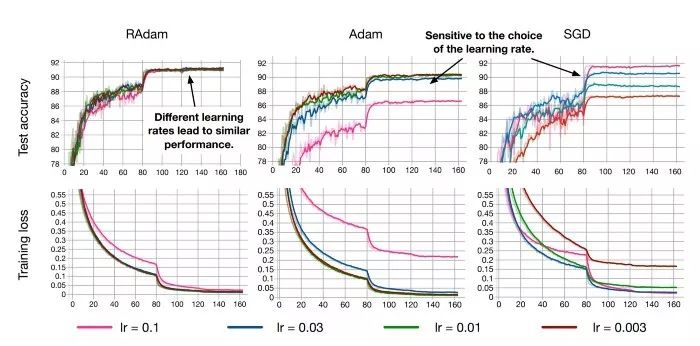
RAdam具備在多種學(xué)習(xí)率下的強大性能,同時仍能快速收斂并實現(xiàn)更高的性能(CIFAR數(shù)據(jù)集)
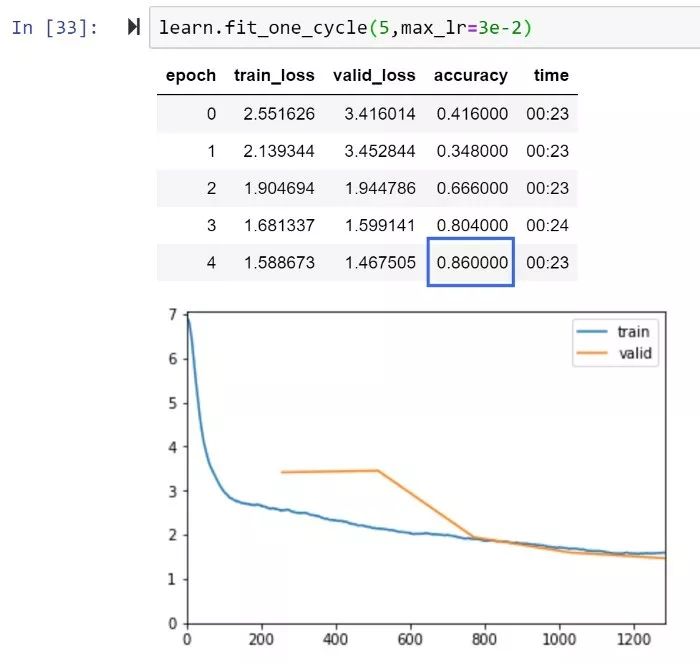
RAdam和XResNet50,5個epoch精度即達(dá)到86%

Imagenette排行榜:達(dá)到當(dāng)前最高性能84.6%
下面來看看RAdam的內(nèi)部機(jī)制,看看為什么能夠?qū)崿F(xiàn)更優(yōu)質(zhì)的收斂,更好的訓(xùn)練穩(wěn)定性(相對所選擇的學(xué)習(xí)率更不敏感),為何基于幾乎所有AI應(yīng)用都能實現(xiàn)更好的準(zhǔn)確性和通用性。

不只是對于CNN:RAdam在Billion Word Dataset上的表現(xiàn)優(yōu)于LSTM
RAdam:無需預(yù)熱,避免模型收斂至“局部最優(yōu)解”
作者指出,雖然每個人都在努力實現(xiàn)快速穩(wěn)定的優(yōu)化算法,但包括Adam,RMSProp等在內(nèi)的自適應(yīng)學(xué)習(xí)率優(yōu)化器都存在收斂到質(zhì)量較差的局部最優(yōu)解的可能。因此,幾乎每個人都使用某種形式的“預(yù)熱”方式來避免這種風(fēng)險。但為什么需要預(yù)熱?
由于目前對AI社區(qū)中對于“預(yù)熱”出現(xiàn)的潛在原因,甚至最佳實踐的理解有限,本文作者試圖揭示這個問題的基礎(chǔ)。他們發(fā)現(xiàn),根本問題是自適應(yīng)學(xué)習(xí)率優(yōu)化器具有太大的變化,特別是在訓(xùn)練的早期階段,并且可能由于訓(xùn)練數(shù)據(jù)量有限出現(xiàn)過度跳躍,因此可能收斂至局部最優(yōu)解。
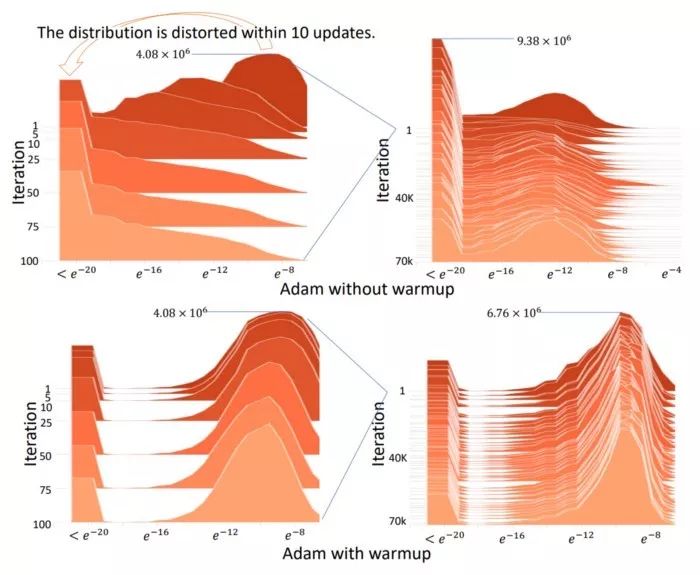
使用原始Adam必須預(yù)熱,否則正態(tài)分布會變得扭曲,是否預(yù)熱的分布對比見上圖
因此,當(dāng)優(yōu)化器僅使用有限的訓(xùn)練數(shù)據(jù)時,采用“預(yù)熱”(這一階段的學(xué)習(xí)率要慢得多)是自適應(yīng)優(yōu)化器要求抵消過度方差的要求。
簡而言之,vanilla Adam和其他自適應(yīng)學(xué)習(xí)速率優(yōu)化器可能會基于訓(xùn)練早期數(shù)據(jù)太少而做出錯誤決策。因此,如果沒有某種形式的預(yù)熱,很可能在訓(xùn)練一開始便會收斂局部最優(yōu)解,這使得訓(xùn)練曲線由于糟糕的開局而變得更長、更難。
然后,作者在不用預(yù)熱的情況下運行了Adam,但是在前2000次迭代(adam-2k)中避免使用動量,結(jié)果實現(xiàn)了與“Adam+預(yù)熱”差不多的結(jié)果,從而驗證了“預(yù)熱”在訓(xùn)練的初始階段中起到“降低方差”的作用,并可以避免Adam在沒有足夠數(shù)據(jù)的情況下在開始訓(xùn)練時即陷入局部最優(yōu)解。
適用于多個數(shù)據(jù)集,堪稱Adam的優(yōu)秀“接班人”
我們可以將“預(yù)熱”作為降低方差的方法,但所需的預(yù)熱程度未知,而且具體情況會根據(jù)數(shù)據(jù)集不同而變化,本文確定了一個數(shù)學(xué)算法,作為“動態(tài)方差減少器”。作者建立了一個“整流項”,可以緩慢而穩(wěn)定地允許將自適應(yīng)動量作為基礎(chǔ)方差的函數(shù)進(jìn)行充分表達(dá)。完整模型是這樣的:

作者指出,在某些情況下,由于衰減率和基本方差的存在,RAdam可以在動量等效的情況下退化為SGD。
實驗表明,RAdam優(yōu)于傳統(tǒng)的手動預(yù)熱調(diào)整,其中需要預(yù)熱或猜測需要預(yù)熱的步驟數(shù)。RAdam自動提供方差縮減,在各種預(yù)熱長度和各種學(xué)習(xí)率下都優(yōu)于手動預(yù)熱。
總之,RAdam可以說是AI最先進(jìn)的優(yōu)化器,可以說是Adam的優(yōu)秀接班人!
-
函數(shù)
+關(guān)注
關(guān)注
3文章
4381瀏覽量
64883 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8503瀏覽量
134619 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1224瀏覽量
25447
原文標(biāo)題:Adam可以換了?UIUC中國博士生提出RAdam,收斂快精度高,大小模型通吃
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
FA模型卡片和Stage模型卡片切換
FA模型訪問Stage模型DataShareExtensionAbility說明
改進(jìn)電壓模型的異步電機(jī)無速度傳感器矢量控制
改進(jìn)GPC算法在永磁同步電機(jī)控制系統(tǒng)中的應(yīng)用
FPGA 大神 Adam Taylor 使用 ALINX VD100(AMD Versal系列)開發(fā)平臺實現(xiàn)圖像處理

KaihongOS操作系統(tǒng)FA模型與Stage模型介紹
如何將 ADAM 采集模塊的 Modbus 原始值轉(zhuǎn)換成物理值?

如何將Cycle模型轉(zhuǎn)換為中間表示 (IR)?
明晚開播 |數(shù)據(jù)智能系列講座第5期:理解并改進(jìn)基礎(chǔ)模型

直播預(yù)約 |數(shù)據(jù)智能系列講座第5期:理解并改進(jìn)基礎(chǔ)模型





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論