") 簡要分析AI芯片的性能分析和應(yīng)用介紹
簡要分析AI芯片的性能分析和應(yīng)用介紹
各大半導(dǎo)體廠商紛紛發(fā)布了人工智能相關(guān)產(chǎn)品。九月初,先是華為的麒麟970集成了寒武紀(jì)的人工智能加速器IP。之后,蘋果在其發(fā)布會上展示了新一代的A11 Bionic SoC,其中集成了neural engine加速器。Imagination也不甘落后,在蘋果之后也發(fā)布了PowerVR NNA神經(jīng)網(wǎng)絡(luò)處理器IP。九月底,Nvidia的開源深度學(xué)習(xí)加速器(DLA)正式上線,幾乎與之同時,Intel也公布了Loihi芯片。本文將盤點(diǎn)以上幾款產(chǎn)品,分析異同。
華為、蘋果、Imagination:面向手機(jī)的成熟產(chǎn)品發(fā)布,移動端AI時代的敲門磚
2016年初,以Eyeriss為代表的深度學(xué)習(xí)加速器芯片乘著人工智能興起的東風(fēng)紛紛破土而出。目前基于深度學(xué)習(xí)的人工智能算法需要很大的計(jì)算量,而傳統(tǒng)CPU芯片上用于計(jì)算的ALU數(shù)目并不多,性能不足以支持深度學(xué)習(xí)算法的流暢執(zhí)行。
另外,GPU雖然在云端服務(wù)器獲得大規(guī)模應(yīng)用,但是一方面GPU架構(gòu)的功耗太大,無法在移動端廣泛使用;另一方面GPU最適合的是深度學(xué)習(xí)訓(xùn)練,在深度學(xué)習(xí)的推理應(yīng)用中因?yàn)镚PU基于batch運(yùn)算的模式導(dǎo)致延遲過大,也不適合在移動端使用。
深度學(xué)習(xí)加速器目前主打的是性能和能效比,其性能能幫助深度學(xué)習(xí)的推理流暢執(zhí)行,而其能效比則保證了算法加速過程中不會消耗太多電池,可以在移動端長時間使用。目前在移動領(lǐng)域,智能攝像頭、無人機(jī)、手機(jī)等都是深度學(xué)習(xí)加速器潛在的應(yīng)用領(lǐng)域,其中以手機(jī)的應(yīng)用市場最大。
關(guān)于深度學(xué)習(xí)加速器的用法,一般分為芯片和IP兩種。芯片的代表如Movidius的Myriad系列(以及基于Myriad芯片的neural stick產(chǎn)品)和,用戶可以把芯片集成到自己的系統(tǒng)中來做深度學(xué)習(xí)加速。然而,在BOM可謂寸土寸金的手機(jī)領(lǐng)域,額外加一塊芯片加速深度學(xué)習(xí)幾乎不可能,可行的做法是在手機(jī)SoC里面集成一塊深度學(xué)習(xí)加速器IP,在手機(jī)執(zhí)行深度學(xué)習(xí)應(yīng)用的時候可以把計(jì)算放到加速器模塊去執(zhí)行。

華為、蘋果和Imagination紛紛發(fā)布人工智能加速IP
華為、蘋果和Imagination發(fā)布的深度學(xué)習(xí)加速器產(chǎn)品都是這樣的IP模塊。這些模塊經(jīng)過長期設(shè)計(jì)和驗(yàn)證,已經(jīng)非常成熟,可以進(jìn)入大規(guī)模生產(chǎn)階段。產(chǎn)品能進(jìn)入量產(chǎn)階段意味著之前已經(jīng)經(jīng)過了長期的技術(shù)積累,正如蘋果和華為透露他們的人工智能加速IP至少在兩年前就已經(jīng)立項(xiàng)了,可見這些手機(jī)巨頭對于人工智能的遠(yuǎn)見和拿下市場的決心。
目前手機(jī)上的人工智能應(yīng)用應(yīng)該說還處于非常初期的階段,硬件和軟件屬于“先有雞還是先有蛋”的境況:在沒有深度學(xué)習(xí)加速硬件的情況下開發(fā)手機(jī)端的人工智能應(yīng)用,會導(dǎo)致硬件限制執(zhí)行速度,用戶體驗(yàn)不好;
而如果沒有手機(jī)端的人工智能相關(guān)應(yīng)用,硬件廠商往往就不會想到要去做專門的深度學(xué)習(xí)加速器。而華為、蘋果和Imagination推出的手機(jī)端深度學(xué)習(xí)加速器IP可謂是打破了這個僵局,成為手機(jī)端人工智能應(yīng)用普及的敲門磚。
華為、蘋果和Imagination公布的加速器峰值性能分別是1.96 TOPS、0.6 TOPS和4TOPS,而實(shí)測的性能麒麟970可以到300 GOPS(執(zhí)行VGG-16模型),Imagination約750 GOPS(執(zhí)行GoogleNet模型),蘋果的實(shí)測數(shù)據(jù)還沒有公布,估計(jì)也是在100 GOPS的數(shù)量級。這樣的數(shù)字能夠支持基礎(chǔ)的深度學(xué)習(xí)算法:
目前,蘋果宣稱其A11中的neural engine主要是加速Face ID應(yīng)用,而華為的展示項(xiàng)目則是實(shí)時物體辨識。預(yù)期在未來,這些人工智能加速器的應(yīng)用場景會遠(yuǎn)遠(yuǎn)多于這些,同時也促成移動端人工智能應(yīng)用的井噴式發(fā)展。
另一方面,我們也應(yīng)該看到,100GOPS數(shù)量級的算法運(yùn)行計(jì)算量更大的實(shí)時物體檢測(object detection,從畫面中同時定位并識別多個物體)還不夠流暢,因此深度學(xué)習(xí)IP還有不少進(jìn)步的空間。
Nvidia DLA:為AI生態(tài)鋪路的前瞻性產(chǎn)品
與華為、蘋果等定制深度學(xué)習(xí)IP模塊不同,Nvidia選擇了開源其深度學(xué)習(xí)加速架構(gòu)DLA。目前,DLA已經(jīng)在github上發(fā)布了其RTL代碼可供編譯、仿真以及驗(yàn)證,預(yù)計(jì)在未來Nvidia將進(jìn)一步公布其C模型等重要設(shè)計(jì)組件。
Nvidia DLA最主要的部分是計(jì)算單元,據(jù)悉目前DLA會使用Winograd算法來減小卷積的計(jì)算開銷,同時也會使用數(shù)據(jù)壓縮技術(shù),來減少DRAM訪問時的數(shù)據(jù)流量。
Nvidia同時給出了NVDLA構(gòu)成的兩種系統(tǒng),在比較復(fù)雜的大系統(tǒng)中, DLA的接口包括與處理器交互的IRQ/CSB,與片外DRAM交互的DBBIF,以及與SRAM交互的SRAMIF,而在小系統(tǒng)的例子中,則省去了SRAMIF,因?yàn)樾∠到y(tǒng)中的SRAM比較寶貴可能沒有可供NVDLA使用的部分。
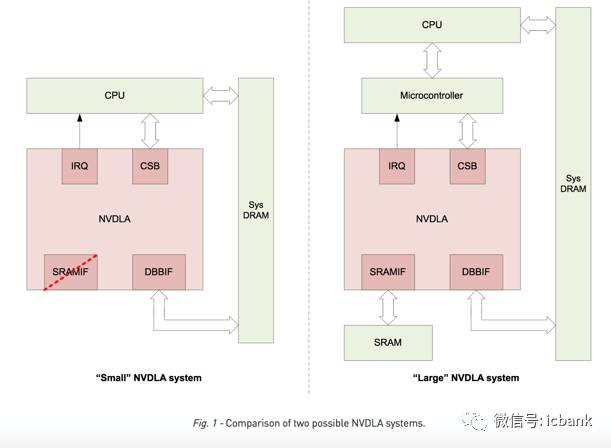
在性能方面,NVDLA在使用2048個MAC的時候可以每秒完成269次ResNet-50推理,相當(dāng)于2.1TOPS的性能,當(dāng)然其對于內(nèi)存的帶寬要求也達(dá)到了20GB/s,接近DDR4系列的最高帶寬。

那么,Nvidia為什么選擇了開源的形態(tài)呢?通過觀察,我們不難發(fā)現(xiàn)目前在人工智能硬件領(lǐng)域,Nvidia已經(jīng)成為云端人工智能加速的主宰者,而在發(fā)展?jié)摿薮蟮臒o人車領(lǐng)域,Nvidia也接連推出多款GPU產(chǎn)品布局,在競爭中也處于領(lǐng)跑地位。
在這些Nvidia具有競爭優(yōu)勢的領(lǐng)域,Nvidia的GPU都是作為一種性能強(qiáng)勁的計(jì)算加速器存在的。然而,對于產(chǎn)品種類多樣而更適合使用SoC產(chǎn)品形態(tài)的移動領(lǐng)域,Nvidia一直沒有打開局面。
之前Nvidia曾經(jīng)推出過TK系列和TX系列作為帶有深度學(xué)習(xí)和機(jī)器視覺硬件加速特性的SoC來試水移動市場,可惜這些產(chǎn)品的功耗都在10W左右,而且成本很高,導(dǎo)致一直無法占領(lǐng)移動端人工智能加速市場。Nvidia最擔(dān)心的恐怕就是有一家芯片廠商在移動端人工加速市場脫穎而出,由下至上挑戰(zhàn)Nvidia在人工智能加速硬件領(lǐng)域的地位。
因此,Nvidia開源其DLA加速模塊,其實(shí)是讓全球的SoC廠商幫Nvidia一起優(yōu)化DLA加速模塊,并且?guī)椭鶱vidia搶占移動端市場。另一方面,開源DLA也能加速移動端人工智能加速硬件的成熟,這樣當(dāng)硬件不再成為瓶頸后,移動端人工智能應(yīng)用將迎來爆發(fā)。而Nvidia作為深度學(xué)習(xí)模型訓(xùn)練(GPU)以及優(yōu)化(TensorRT)工具鏈生態(tài)環(huán)境的實(shí)際掌控者,在移動端人工智能市場真正蓬勃發(fā)展后,即使DLA不帶來收入也能從人工智能產(chǎn)業(yè)鏈的上游獲得大量收益,因此開源DLA的舉動是Nvidia布局人工智能生態(tài)的重要一步。
Intel Loihi:神經(jīng)擬態(tài)芯片,試驗(yàn)性產(chǎn)品
與前述的幾家公司不同,Intel推出的Loihi是一款基于神經(jīng)擬態(tài)(neuromorphic)的芯片。目前最流行的深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)中,神經(jīng)網(wǎng)絡(luò)把人類的神經(jīng)系統(tǒng)的統(tǒng)計(jì)行為抽象為一系列運(yùn)算(高維卷積以及非線性運(yùn)算)的數(shù)學(xué)系統(tǒng),與真正的生物神經(jīng)工作并不相同,而之前介紹的幾款產(chǎn)品(以及絕大多數(shù)其他人工智能加速器硬件)都是加速這類經(jīng)典神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)的。
神經(jīng)擬態(tài)則是幾乎完全照搬生物神經(jīng)系統(tǒng),試圖在模型中完全重現(xiàn)生物神經(jīng)的工作方式(例如引入神經(jīng)元電勢可以充放電,在電勢超過一定閾值后神經(jīng)元就會放出電脈沖到其他相鄰的神經(jīng)元)。理論上,這種神經(jīng)擬態(tài)芯片可以由異步系統(tǒng)實(shí)現(xiàn),并且有很低的功耗。然而,目前神經(jīng)擬態(tài)結(jié)構(gòu)如何訓(xùn)練仍然是學(xué)術(shù)界沒有解決的問題。
Intel發(fā)布的Loihi聲稱可以自我學(xué)習(xí),然而學(xué)習(xí)的效果如何還不得而知。應(yīng)該說在模型訓(xùn)練問題還沒有解決前,神經(jīng)擬態(tài)就基本無法與經(jīng)典的深度學(xué)習(xí)在主流人工智能應(yīng)用里正面競爭,而主要會用在一些實(shí)驗(yàn)性的應(yīng)用,例如利用神經(jīng)擬態(tài)芯片去完成腦科學(xué)研究,或者做一些專用場合的高效數(shù)據(jù)處理(例如三星就使用過IBM的True North神經(jīng)擬態(tài)芯片來實(shí)現(xiàn)動態(tài)視覺傳感器,只有在畫面發(fā)生變化的時候該傳感器才會記錄)。而Intel發(fā)布的Loihi,也更多是一款試驗(yàn)性質(zhì)的產(chǎn)品。
為什么大家紛紛推出AI芯片產(chǎn)品?
在一個月中,幾家大公司相繼發(fā)布AI芯片,這首先說明人工智能應(yīng)用真正獲得了市場的認(rèn)可。如果我們回顧芯片市場,會發(fā)現(xiàn)總是先有軟件應(yīng)用出現(xiàn),該應(yīng)用在得到認(rèn)可后快速發(fā)展很快遇到硬件瓶頸,于是推動相應(yīng)硬件的開發(fā),而在硬件瓶頸突破后,該應(yīng)用又會獲得更快速的普及,從而形成一個正循環(huán)。目前人工智能正處于該循環(huán)的第二步,即硬件限制了人工智能應(yīng)用的普及,尤其是在移動端的普及,而各大硬件廠商正是看到了人工智能的巨大潛力,于是紛紛開發(fā)相關(guān)芯片并爭相發(fā)布。
在未來的移動人工智能市場,由于移動產(chǎn)品的多樣性(如要求高性能但是允許高功耗的智能攝像頭市場,要求高性能但是同時要求低延遲和低功耗的無人機(jī)市場,要求中等性能但是對成本和功耗要求很高的手機(jī)市場,以及要求超低功耗但是對于性能要求也不高的物聯(lián)網(wǎng)市場),預(yù)計(jì)還是會有多家公司分別占領(lǐng)不同的市場,而不太會出現(xiàn)一家獨(dú)大通吃所有市場的情況。未來人工智能芯片預(yù)計(jì)會進(jìn)入群雄逐鹿的時代。
-
人工智能
+關(guān)注
關(guān)注
1804文章
48677瀏覽量
246276 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5554瀏覽量
122458 -
AI芯片
+關(guān)注
關(guān)注
17文章
1968瀏覽量
35687
發(fā)布評論請先 登錄
ESD技術(shù)文檔:芯片級ESD與系統(tǒng)級ESD測試標(biāo)準(zhǔn)介紹和差異分析
Nordic nRF54 系列芯片:開啟 AI 與物聯(lián)網(wǎng)新時代?
N9020A 頻譜分析儀介紹:性能、特點(diǎn)及應(yīng)用

芯片失效分析的方法和流程
調(diào)制信號的性能分析
什么是半導(dǎo)體芯片的失效切片分析?
FIB技術(shù):芯片失效分析的關(guān)鍵工具

云端AI開發(fā)環(huán)境分析
深蕾半導(dǎo)體HDMI AI分析盒子






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論