 電子發(fā)燒友App
電子發(fā)燒友App


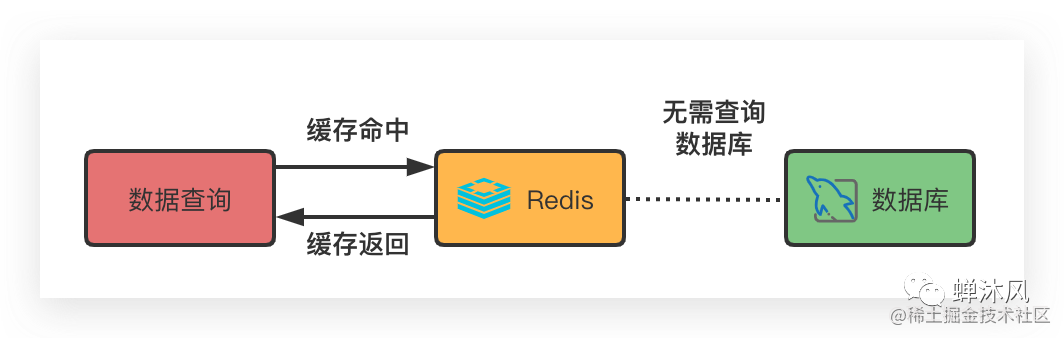
如今,緩存系統(tǒng)的應(yīng)用非常廣泛,能夠用來提高并發(fā)數(shù)、數(shù)據(jù)吞吐量,提高快速響應(yīng)能力。那么當數(shù)據(jù)量達到一定程度,單機環(huán)境可能就顯得有些力不從心了,就需要一個分布式緩存系統(tǒng)。
1.緩存系統(tǒng)的選擇
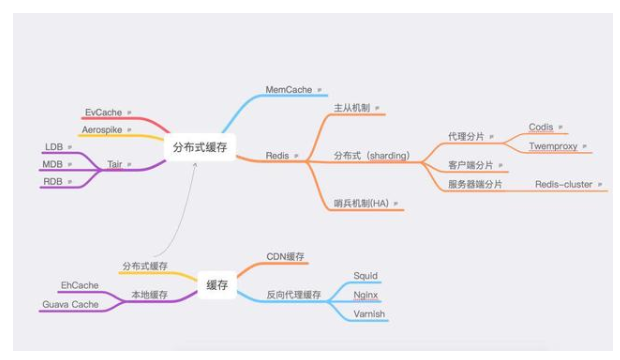
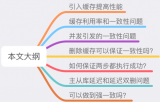
圖1-1
1.1緩存分類
如上圖所示,首先緩存大致可以分為四大類。
CDN緩存:CDN即內(nèi)容分發(fā)網(wǎng)絡(luò),CDN邊緣節(jié)點將數(shù)據(jù)緩存起來。
反向代理緩存:如Nginx的緩存。
本地緩存:代表的有EhCache和GuavaCache。
分布式緩存:各緩存系統(tǒng)。
1.2分布式緩存
本文主要探討各分布式緩存系統(tǒng),如圖1-1所示,列出了五種:
其中EvCache和Aerospike使用場景不是那么通用和廣泛。
EvCache:是Netflix的基于Memcached&Spymemcached的緩存方案。
Aerospike:是可基于SSD的KVNoSQL數(shù)據(jù)庫。
除此之外,還有三種常見緩存系統(tǒng)。
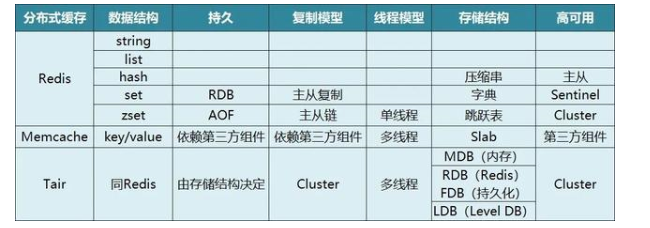
Tair:阿里開源,跨機房、性能隨結(jié)點添加線性上升、適用大數(shù)據(jù)量。Tair還有三種引擎。
LDB:基于googlelevelDB,支持KV和類HashMap結(jié)構(gòu),性能稍低,持久化可靠性最高。
MDB:基于Memcache,支持KV和類HashMap,性能最優(yōu),不支持持久化存儲。
RDB:基于Redis。
Memcache:不支持數(shù)據(jù)同步、分布式支持較差。
Redis:社區(qū)活躍、使用最多。
綜上所述,在一般情況下,考慮到適用性和穩(wěn)定性,Redis是搭建緩存系統(tǒng)的最優(yōu)選擇。以下將基于Redis介紹。
2.Redis集群緩存方案
如頂部圖1-1所示,列出了Redis的集群高可用的方案,基本可以分為三種。
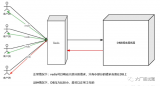
2.1主從機制
常見的集群架構(gòu),搭建簡單,主要實現(xiàn)讀寫分離和備份,可以由Master負責讀寫,Slave負責備份。但存在故障恢復(fù)復(fù)雜、水平拓展難、寫能力受限等問題。結(jié)構(gòu)圖如下:
2.2哨兵機制
RedisSentinel是社區(qū)版本推出的原生高可用解決方案。由一或多個哨兵實例監(jiān)視任意個主從服務(wù)器,且在Master宕機時,自動將宕機服務(wù)器屬下的Slave服務(wù)器升級為主服務(wù)器,從而保證系統(tǒng)的可用性。較主從實現(xiàn)的監(jiān)控、選主。但問題主要是要保證Master的HA切換。結(jié)構(gòu)圖如下:
2.3“分布式”
到這里以上兩種機制其實只能算作“集群”,并非嚴格意義上的“分布式”。接著來看看分布式方案。
集群強調(diào)高可用,分布式在集群的基礎(chǔ)上又強調(diào)協(xié)作。
3.Redis分布式緩存方案
任何分布式存儲系統(tǒng),首先面臨的就是sharding(分片)問題,如頂部圖1-1所示該問題有為三種解決方法。
3.1客戶端分片
顧名思義,將數(shù)據(jù)分片的路由功能交給客戶端,但這是一種靜態(tài)分片,維護性差。基本是不予考慮的。
3.2代理分片
通過代理分發(fā)到具體的redis實例。有兩個常用解決方案。
Twemproxy:Twitter開源,輕量級,不再維護,無法平滑地擴容/縮容,運維也不是很友好,性能一般。
Codis:豌豆莢開源,支持水平拓展,運維平臺完善,性能較Twemproxy快。Codis在國內(nèi)使用的較多,同時代理分片的思路也有很多公司在此基礎(chǔ)開發(fā)了自己的二次方案。不過Codis也不再維護。
其實,這兩種代理分片的方案,都是在Redis官方未推出良好的分布式方案時的產(chǎn)生的,在官方更新提供更優(yōu)策略后都不再維護。
3.3服務(wù)器端分片
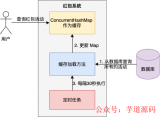
這就要談到Redis官方方案Redis-cluster。
在Redis3.0之前是沒有較好的分布式方案的,這也是第三方方案出現(xiàn)的原因。3.0開始,官方推出了去中心化的分布式方案。集群中包含16384個散列槽,每個節(jié)點負責其中一部分。
先看下拓撲圖:
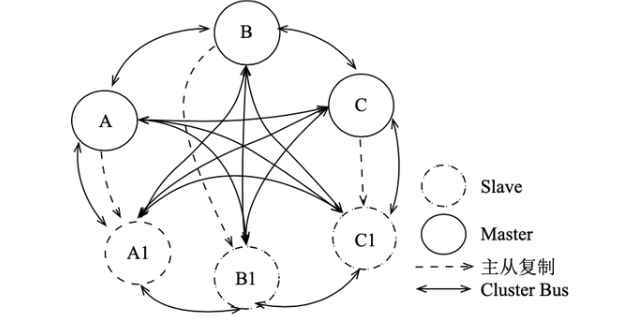
每個節(jié)點打開兩個TCP連接,一個負責給客戶端提供服務(wù),一個負責節(jié)點間通信。
此刻要說說CAP了:Consistency(一致性)、Availability(可用性)、Partitiontolerance(分區(qū)容錯性)。對分布式系統(tǒng)而言,CAP必須犧牲一者。RedisCluster的設(shè)計目標主要是高性能、高可用和高擴展,只好拋棄一部分數(shù)據(jù)一致性。
數(shù)據(jù)一致性:由于RedisCluster使用異步復(fù)制,在某些情況下如Master宕機但未同步至Slave,可能會導致丟失寫入。在絕對需要支持同步寫入時,可通過WAIT命令實現(xiàn),可使得丟失寫入的可能性大大降低。
可用性:當集群中一部分節(jié)點故障后,集群整體能響應(yīng)客戶端讀寫請求。
節(jié)點間定時互ping,當超過一半Master判定某節(jié)點失敗,則標記為FAIL,且會向集群廣播節(jié)點下線的消息。如下線節(jié)點是帶有槽的主節(jié)點,則要從它的從節(jié)點選出一個替換。
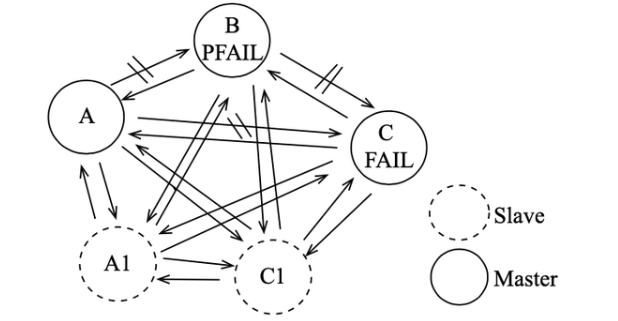
高性能和拓展:操作某個key時,不會先找到節(jié)點再處理,而是直接直接重定向到該節(jié)點,同時相較代理分片也少了proxy的連接損耗。
但是在進行multiplekey操作時需要keys位于同一個slot上,需要使用hashtags,使用{}強制將某些key映射到每個slot,以便進行multiple。
在拓展方面,RedisCluster最大支持線性拓展1000個節(jié)點,將新節(jié)點加入集群后可以通過命令指定和平均的從已有節(jié)點分配slot。
4.緩存常見問題
以上介紹了簡單介紹了常見緩存系統(tǒng),并具體列出了基于Redis的集群方案。下面談一談緩存系統(tǒng)常見的問題。
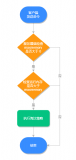
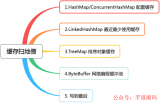
如下圖所示,列出七個常見問題。
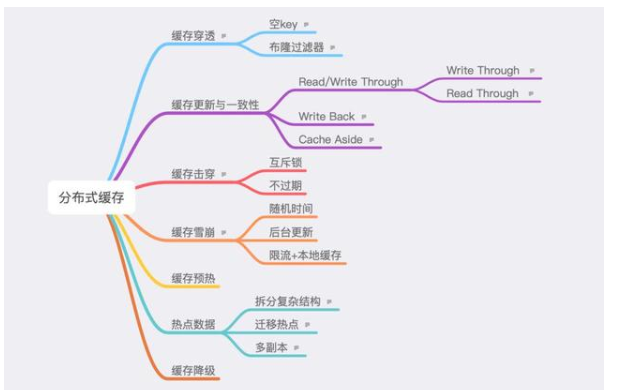
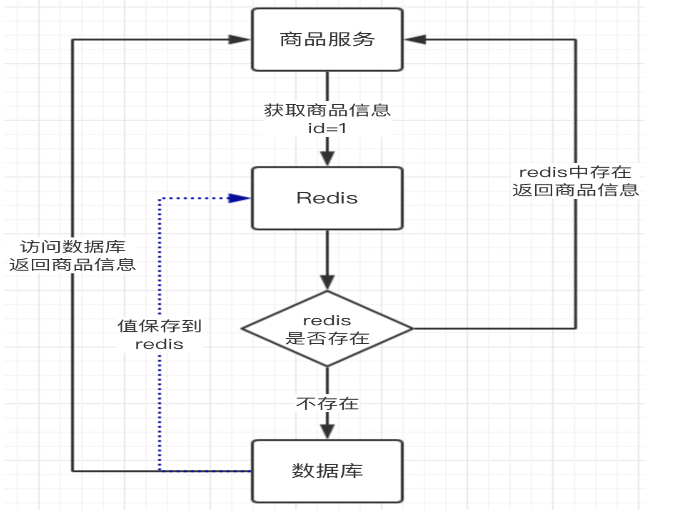
4.1.緩存穿透
指訪問不存在的數(shù)據(jù),從而繞過緩存,直接請求到了數(shù)據(jù)源,當請求過多,就會對DB造成壓力。
空key:指對于不存在的數(shù)據(jù)也將key存空值入緩存系統(tǒng),這樣下次訪問也會得到返回。但只適用于空數(shù)據(jù)key有限、key重復(fù)請求概率高,如果量大且不重復(fù),就會造成很多無用key的創(chuàng)建。
布隆過濾器:布隆過濾器是一個很長的二進制向量和一系列隨機映射函數(shù)。可用于檢索一個元素是否在一個集合中加一層對空值的過濾器,空間和時間效率都很高。但由于hash產(chǎn)生的碰撞可能存在誤判,以及因不存儲key導致的無法刪除。適用于空數(shù)據(jù)key各不同、重復(fù)請求概率低。
4.2.緩存擊穿
緩存擊穿實際是緩存雪崩的一個特例。指當某些熱點key過期時,就會有大量的請求擊穿到DB。
互斥鎖:在緩存失效的時候,不立即loaddb,可以先用如SETNX等命令去set一個mutexkey,當操作返回成功時,說明拿到鎖,此刻該線程進行l(wèi)oaddb的操作并更新緩存;否則未拿到鎖就(可休眠一段)重試get緩存的方法。但要注意死鎖風險。
不過期
這里的不過期有兩個概念,一個指未設(shè)過期時間,那是真的不過期,那沒事了。
另一個是指通過業(yè)務(wù)邏輯,將key的過期時間進行存儲,請求是判斷是否小于值,是則后臺異步更新。
4.3.緩存雪崩
同一時刻大量緩存失效(故障),請求到了DB。
隨機時間:在設(shè)置過期時間時,可以在基礎(chǔ)時間上+一個隨機的時間,等于實現(xiàn)了分批過期。
后臺更新:將更新失效的工作交給后臺定時線程。
限流+本地緩存:如ehcache本地緩存+Hystrix限流。
雙緩存:類似于設(shè)置主從緩存,從key不過期。
4.4.緩存更新與一致性
如果保證數(shù)據(jù)一致性。列出四種更新策略:
CacheAside:最常用的。失效時回源取數(shù)據(jù),更新;命中時,返回緩存數(shù)據(jù);更新時先數(shù)據(jù)源更新,再更新緩存。
WriteBack:更新數(shù)據(jù)時,只更新緩存,不更新數(shù)據(jù)源。緩存異步批量更新數(shù)據(jù)庫。
Read/WriteThrough
WriteThrough:當有數(shù)據(jù)更新時,如未命中緩存,直接更新數(shù)據(jù)庫,并返回。如命中緩存,則更新緩存,再由Cache自己更新數(shù)據(jù)庫。
ReadThrough:更新數(shù)據(jù)源由緩存系統(tǒng)操作,讀取數(shù)據(jù)時如緩存失效,則取回源數(shù)據(jù)更新緩存。
4.5.熱點數(shù)據(jù)
對于熱點數(shù)據(jù)的處理方法。
拆分復(fù)雜結(jié)構(gòu):如二級數(shù)據(jù)結(jié)構(gòu),進行拆分,這樣熱點key就被拆為若干個的key分布到不同節(jié)點。
遷移熱點:對于RedisCluster而言可以將熱點key所在的slot單獨遷移到一個節(jié)點,降低其他節(jié)點壓力。
多副本:復(fù)制多份緩存副本,將請求分散到多個節(jié)點上,減輕單臺緩存服務(wù)器壓力,適合多讀少寫。
4.6.緩存預(yù)熱
指可以將某些的緩存數(shù)據(jù)提前加載到緩存系統(tǒng),提前避免在如熱點數(shù)據(jù)大量請求到庫。
4.7.緩存降級
指當訪問量劇增、服務(wù)出現(xiàn)問題或非核心服務(wù)影響到核心流程的性能時,仍需保證主服務(wù)可用。可根據(jù)一些關(guān)鍵數(shù)據(jù)自動降級,也可配置開關(guān)人工降級。
5.RedisCluster使用
對于RedisCluster環(huán)境的搭建和基礎(chǔ)使用非常簡單。
無論基于何種方式,只要搭建好n臺redis服務(wù)并保證各服務(wù)間可以互相通訊后,任意進入一個redis服務(wù)鍵入:
redis-cli--clustercreateIP1:port1IP2:port2IP3:port3IP4:port4IP5:port5IP6:port6。。。--cluster-replicas1即可。之后可以使用clusternode和clusterinfo命令查看集群、節(jié)點信息。
而對于廣大JAVA開發(fā),SpringDataRedis從1.7起即支持RedisCluster,只需配置Master節(jié)點地址(和密碼)。
spring.redis.cluster.nodes=ip1:port1,ip2:port2,ip3:port3
加入依賴
compile(“org.springframework.boot:spring-boot-starter-data-redis”)即可通過RedisTemplate使用。
6.總結(jié)
本文從緩存系統(tǒng)的選擇出發(fā),基于Redis介紹了幾種集群方案并重點說明了RedisCluster方案。之后列出緩存系統(tǒng)常見問題及常見解決方案,最后對使用做了簡單說明。
當然,如何去落地,如何解決這些問題還需要根據(jù)實際場景具體分析和處理。
責任編輯人:CC






















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論