 電子發燒友App
電子發燒友App


1. 前言:為什么要用緩存?
用戶數增長,架構演變,數據量增大,開始考慮怎么去做性能優化。
而性能優化的第一定律就是:優先考慮使用緩存。
2. 緩存的基本原理
2.1 緩存的作用
1、加快數據訪問速度;
2、減輕后端應用和數據存儲的負載壓力。
2.2 緩存的特征
1、命中率:命中率 = 命中數 / 請求數。
這是衡量緩存有效性的重要指標。命中率越高,表明緩存的使用率越高。
2、最大元素(最大空間)。
一旦緩存中元素數量超過這個值(或者緩存數據空間超過其最大支 持空間),將會觸發淘汰策略。
3、淘汰策略。
這個我前文其實已經說過。
FIFO(First In First Out) 先進先出,淘汰最早數據。
判斷存儲時間,離目前最遠的數據優先淘汰。
LRU (Least Recently Used)剔除最近最少使用。
判斷最近使用時間,離目前最遠的數據優先淘汰。
LFU (Least Frequently Used)剔除最近使用頻率最低的數據。
在一段時間內,數據被使用次數最少的,優先淘汰。
具體可以看這篇文章常見的緩存剔除策略 & LRU與LFU的區別。
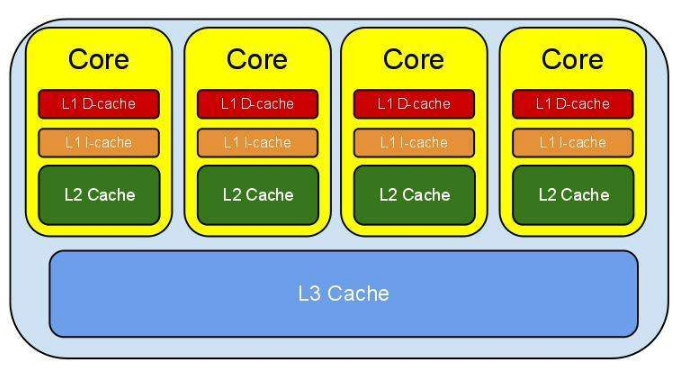
3. 緩存的分類
緩存的主要手段有:瀏覽器緩存、CDN、反向代理、本地緩存、分布式緩存、數據庫緩存。
在解讀《大型網站技術架構》一文中,其實已經說到過。
我們一般說做性能優化時是指后三個:本地緩存、分布式緩存、數據庫緩存。
前面三個緩存策略屬于網站前端的范疇。
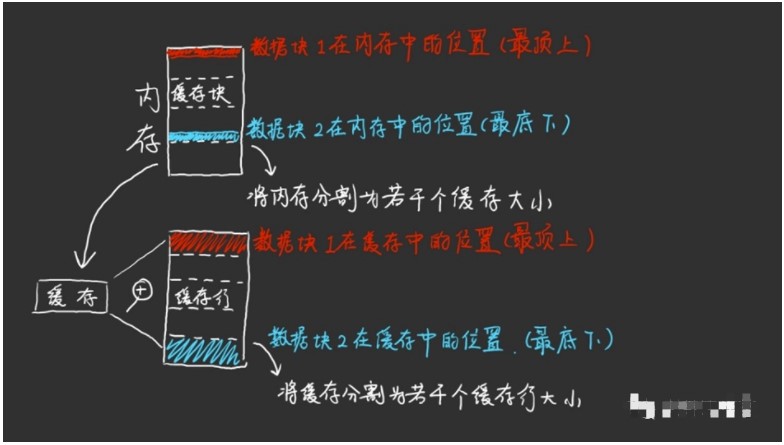
從硬件介質上來看,緩存分為內存和硬盤兩種。
但從技術上,又可以分成內存、硬盤文件、數據庫。
我們通常意義上說的緩存一般都是基于內存的。
因為只有內存,才足夠快。
數據庫緩存一般也是基于內存的,但這個活一般是DBA在配置數據庫的時候就設置好了。
對于大部分開發人員來說,我們一般所說的緩存優化都是基于本地緩存(ocal cache)和遠程緩存(remote cache)。
而現在遠程緩存這個詞一般也被分布式緩存這個常用方案所代指。
4. 什么時候使用緩存?
4.1 緩存的使用判斷
什么時候使用緩存的判斷其實比較簡單,抓住兩點就行了:
1、是不是熱點數據?
所謂熱點,一般是遵循二八定律,即百分之八十的訪問集中在百分之二十的數據上。
2、是不是讀比寫多?
這個比例一般為2:1。
4.2 什么時候不應該使用緩存?
反過來就是了。
1、沒有熱點數據不要使用緩存,也沒什么意義。
因為內存資源是比較寶貴的。
2、頻繁修改的數據不要使用緩存。
因為可能寫入后還來不及讀取就已失效或被淘汰,并且容易產生臟讀。
4.3 合理使用緩存
最后,最重要的是確認是否需要使用緩存?
確定了后,再選擇合適的緩存工具及使用緩存的方式。
5. 緩存時常見的一些問題
使用緩存優點很多,但也存在一些很常見的問題。雙刃之劍,就看怎么用了。
列舉一些我們工作中常見的一些緩存問題,并給出至少一種解決方案。
5.1 緩存更新帶來的數據不一致與臟讀
緩存更新的常見策略有:
1、先更新數據庫再更新緩存;
2、先更新數據庫再刪除緩存;
3、先刪除緩存再更新數據庫;
4、定時清理緩存;
5、有請求訪問數據時,判斷緩存是否過期,過期從數據庫中刷新緩存。
在這幾種方案中,如果修改緩存與數據庫不在同一個事物中,就帶來了數據不一致和臟讀的問題。
對應方案1:先刪除緩存再更新數據庫,并且在同一個事物中。
對應方案2:緩存自動失效后,另外的異步線程進行緩存更新。
對應方案3:緩存更新在并發、分布式要考慮鎖,redis天生就是單線程,比較有優勢。
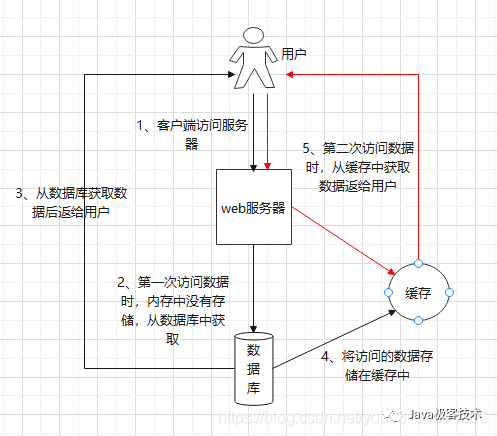
5.2 怎么做緩存預熱
緩存預熱是指在用戶可訪問服務之前,將熱點數據加載到緩存的操作,這樣可以有效避免上線后瞬時大流量造成系統不可用。
緩存預熱的一般性策略:
1、開發個緩存刷新功能,手工刷新;
2、項目啟動的時候自動進行加載(一般為字典表等數據量不大的數據);
3、設置個定時器,自動刷新緩存;
4、提前統計熱點數據,事先批量加載到如redis這樣緩存工具中。
5.3 緩存重建
緩存失效后,重建熱點緩存,如果耗時較長,在重建過程中,性能、負載不好。
對應方案:
1、正常情況下,交錯緩存失效時間,減輕緩存壓力;
2、崩潰失效的情況下,可以使用帶持久化功能的緩存來恢復,比如Redis;
3、如果是MongoDB則不太一樣,它是采用mmap來將數據文件映射到內存中,所以當MongoDB重啟時,這些映射的內存并不會清掉,不需要進行緩存重建與預熱。
5.4 緩存雪崩與可用性
緩存雪崩:緩存在同一時間失效時,訪問直達數據庫層,可能導致DB掛掉、系統崩潰。
對應方案1:交錯緩存失效時間或隨機緩存失效時間。
對應方案2:主從熱備(Redis sentinel)。
對應方案3:集群/水平切分(Redis Cluster、一致性哈希)。
5.5 緩存穿透
緩存穿透:持續高并發訪問某個不存在的Key。
對應方案1:空值緩存。
對應方案2:布隆過濾器(bloom filter) + bitmap。窮舉可能訪問的數據放入bitmap中,使用hash訪問。
5.6 緩存擊穿
緩存擊穿:熱點Key失效,高并發請求,直擊數據庫。
緩存擊穿與緩存穿透很相似,不同點是是緩存擊穿前訪問的是真實的熱點數據,只是在某一剎那失效了,造成了擊穿的效果。
這樣看,它其實也是緩存雪崩的一個特例。與雪崩的區別即在于擊穿是對于特定的熱點數據,而雪崩是全部數據。
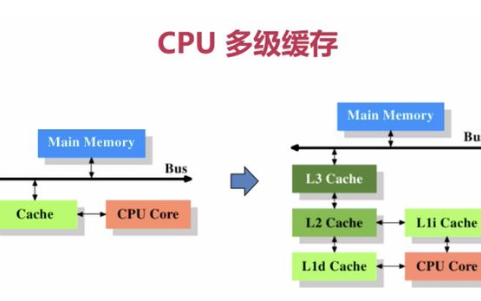
對應方案:多級緩存及交錯失效時間 + LRU 淘汰算法。
對于熱點數據進行二級或多級緩存,并對于不同級別的緩存設定不同的失效時間,緩解雪崩。
此外可使用LRU的變種算法LRU-K緩存數據。
5.7 緩存降級
緩存降級是服務降級中的一環。
在訪問量劇增,導致服務出現問題時,為了保證核心服務可用,防止發生緩存雪崩,可進行服務降級。
以redis為例,比較常見的做法就是,不去數據庫查詢,而是直接返回默認值給用戶。
緩存降級也可根據日志級別進行預案設置。
6. 分布式緩存的選型
說了這么多緩存的原理與策略,說說我們在實際工作中應該怎么去做緩存選型。
以下就是常用的幾種緩存工具。
6.1 Ehcache
Ehcache是純Java開源的緩存框架,最早從hibernate發展而來,現在算是springboot中的官配緩存工具,整合簡單。特點如下:
快速,針對大型高并發系統場景,Ehcache的多線程機制有相應的優化改善;
簡單,很小的jar包,簡單配置就可直接使用,單機場景下無需過多的其他服務依賴;
支持多種的緩存策略,靈活;
緩存數據有兩級:內存和磁盤,與一般的本地內存緩存相比,有了磁盤的存儲空間,將可以支持更大量的數據緩存需求;
具有緩存和緩存管理器的偵聽接口,能更簡單方便的進行緩存實例的監控管理;
支持多緩存管理器實例,以及一個實例的多個緩存區域。
6.2 Guava Cache
Guava Cache是Google開源的Java重用工具集庫Guava里的一款緩存工具,特點如下:
自動將entry節點加載進緩存結構中;
當緩存的數據超過設置的最大值時,使用LRU算法移除;
具備根據entry節點上次被訪問或者寫入時間計算它的過期機制;
緩存的key被封裝在WeakReference引用內;
緩存的Value被封裝在WeakReference或SoftReference引用內;
統計緩存使用過程中命中率、異常率、未命中率等統計數據。
6.3 Memcache
memcache本身不支持分布式,是通過客戶端的路由處理來達到分布式解決方案的目的。特點如下:
memcache使用預分配內存池的方式管理內存;
所有數據存儲在物理內存里;
非阻塞IO復用模型,純KV存取操作;
多線程,效率高,會遇到鎖等上下文切換問題;
只支持簡單KV數據類型;
數據不支持持久化。
6.4 Redis
Redis是當前主流的高性能內存數據庫,多用于存儲緩存數據,并能實現輕量級的MQ功能。特點如下:
臨時申請空間,可能導致碎片;
有VM機制,能存儲更多數據,超過內存空間后會導致swap,降低效率;
非阻塞IO復用模型,支持額外CPU計算:排序、聚合,會影響IO性能;
單線程,無鎖,無上下文切換,單實例無法利用多核性能;
支持多種數據類型:string / hash / list / set / sorted set;
數據支持持久化:AOF(語句增量)/RDB(fork全量);
天然支持高可用分布式方案sentinel +;
cluster(故障自動轉移+集群)。
6.5 推薦
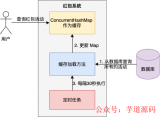
通常情況下,單機我們會用Ehcache,甚至java自己的concurrenthashmap來實現緩存。分布式一般使用redis。















 工商網監
工商網監
評論