 電子發燒友App
電子發燒友App











 創作
創作 發文章
發文章 發帖
發帖  提問
提問  發資料
發資料 發視頻
發視頻資料介紹
描述
該項目介紹了我們對基于稱為 AdderNet 的新型深度學習模型的硬件推理加速器設計和優化的研究。通過用絕對和 (SAD) 內核替換計算密集型卷積 (CONV) 操作,可以通過具有成本效益的加法器/減法器電路消除大量乘法器,這可以提高計算吞吐量,因為硬件限制。我們在 FPGA 設備上展示了基線 ResNet-20 實現 (CNN-ResNet-20) 和兩個 AdderNet 設計變體 (ADD-ResNet-20) 之間的比較研究。我們利用自動 HLS(高級綜合)和手動轉換將 SAD 操作映射到 Xilinx Zynq MPSoC 的 FPGA DSP 塊 (DSP48E2)。尤其是,當 DSP48 模塊配置為 SIMD(單指令多數據)模式時,我們可以用一個 DSP 模塊和最少的 LUT 邏輯資源支持至少兩個 SAD 操作。在這個研究階段,我們選擇使用一個 DSP 來支持 2 個 SAD 操作,以增加 10% 的 LUT 和 5% 的推理時間開銷為代價,總共可以減少 45.43% 的 DSP 利用率。這些結果鼓勵我們探索新的深度學習加速器設計策略,以利用新興的基于 SAD 內核的 AdderNet 模型以及每個 DSP ≥4 SAD 的積極 SIMD 配置來提高推理吞吐量。我們選擇使用 1 個 DSP 支持 2 個 SAD 操作,以增加 10% 的 LUT 和 5% 的推理時間開銷為代價,總共可以減少 45.43% 的 DSP 利用率。這些結果鼓勵我們探索新的深度學習加速器設計策略,以利用新興的基于 SAD 內核的 AdderNet 模型以及每個 DSP ≥4 SAD 的積極 SIMD 配置來提高推理吞吐量。我們選擇使用 1 個 DSP 支持 2 個 SAD 操作,以增加 10% 的 LUT 和 5% 的推理時間開銷為代價,總共可以減少 45.43% 的 DSP 利用率。這些結果鼓勵我們探索新的深度學習加速器設計策略,以利用新興的基于 SAD 內核的 AdderNet 模型以及每個 DSP ≥4 SAD 的積極 SIMD 配置來提高推理吞吐量。
卷積神經網絡(CNN)已廣泛應用于計算機視覺任務領域。例如工業檢測、自主視覺和機器人檢測。然而,由于其大量的乘法運算和參數,很難將這些標準神經網絡部署到具有效率吞吐量和功耗的嵌入式設備中。作為一種解決方案,AdderNet 在深度神經網絡,尤其是卷積神經網絡 (CNN) 中使用這些大規模乘法,以獲得更便宜的加法以降低計算成本。
?
?
Function.1 CNN
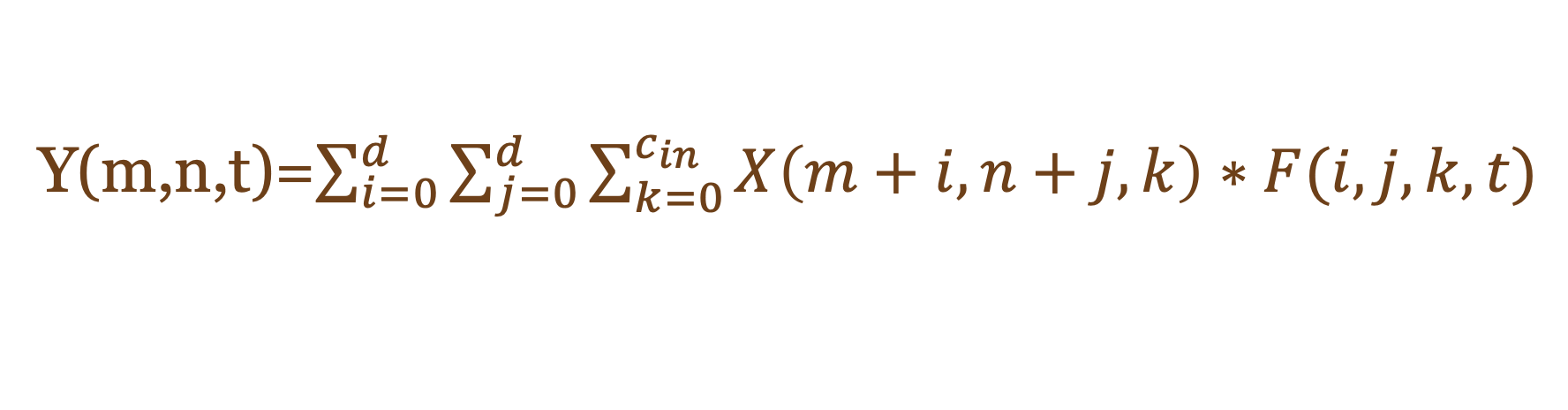
Function.2 人工神經網絡
?
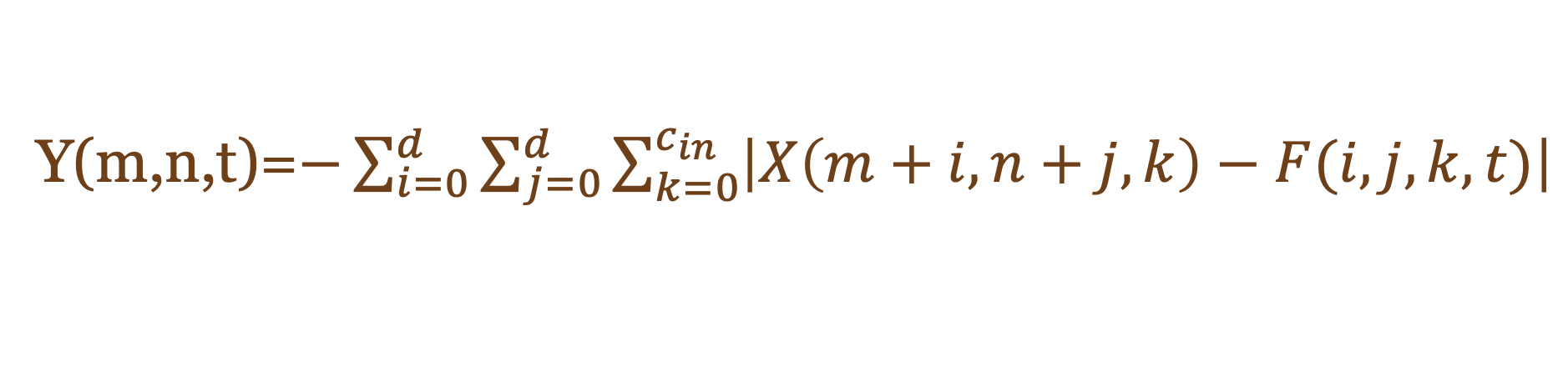
?
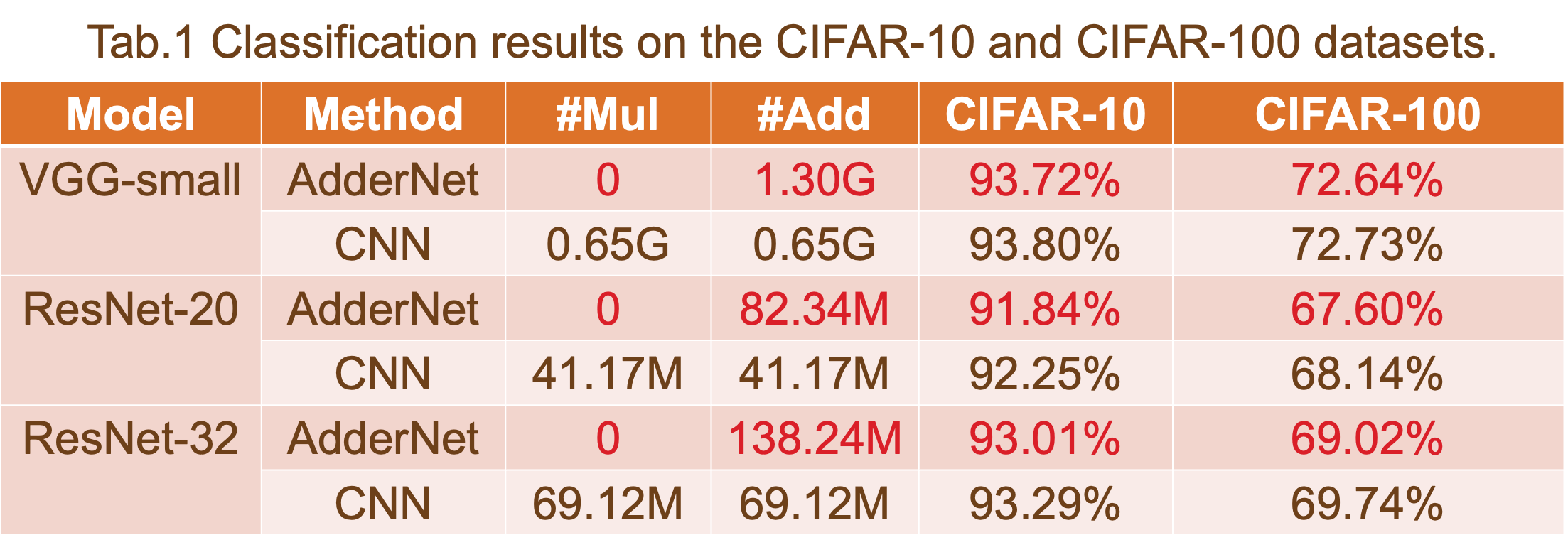
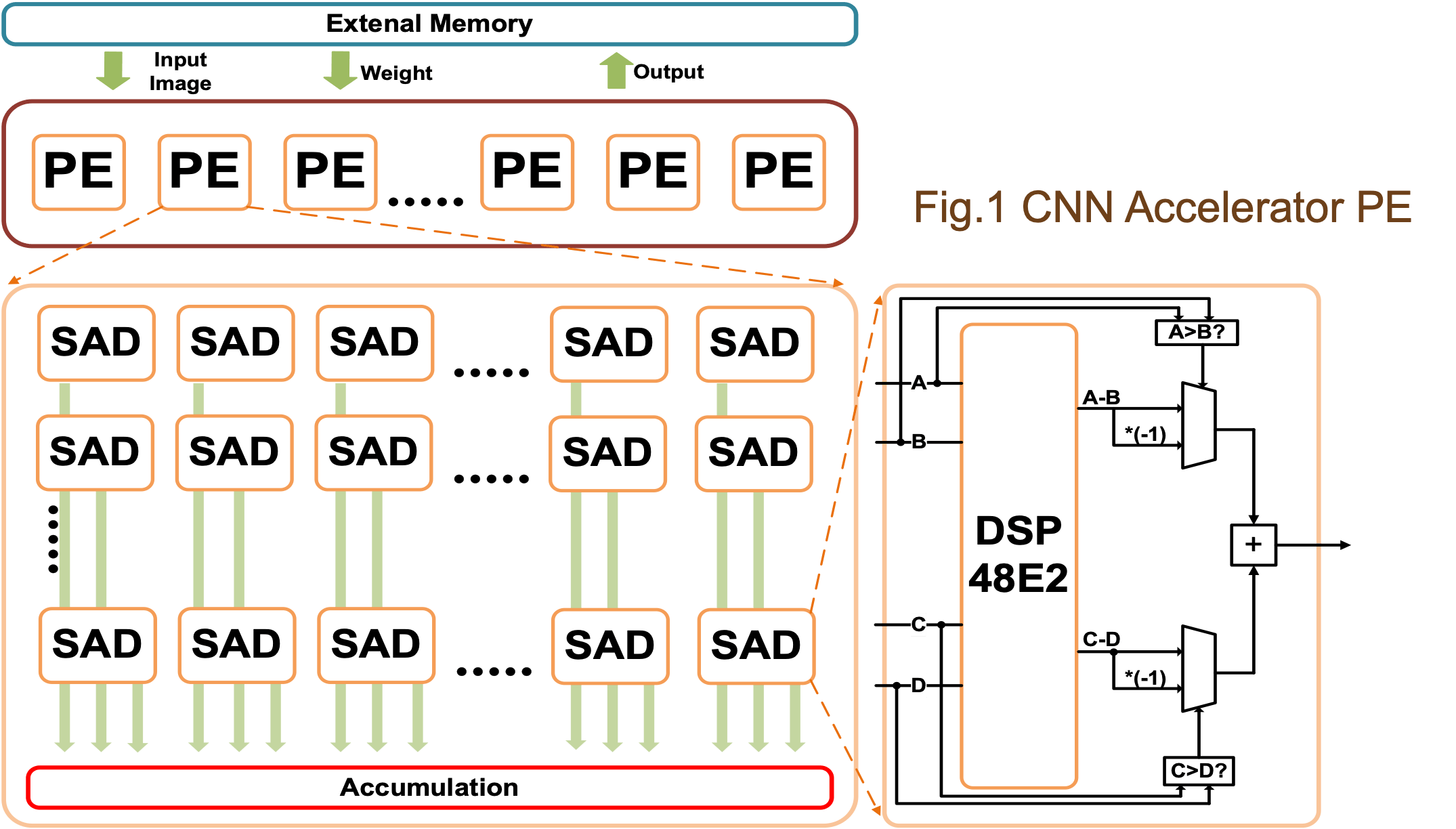
作為案例研究,我們選擇 ResNet-20-CIFAR10 作為基線設計。ResNet-20-CIFAR10的處理引擎如圖1所示。據我們所知,CNN 加速器有兩種通用方法:單個 PE 和多個 PE。在這項工作中,我們在應用程序中使用了多個 PE 以獲得更好的吞吐量。
?
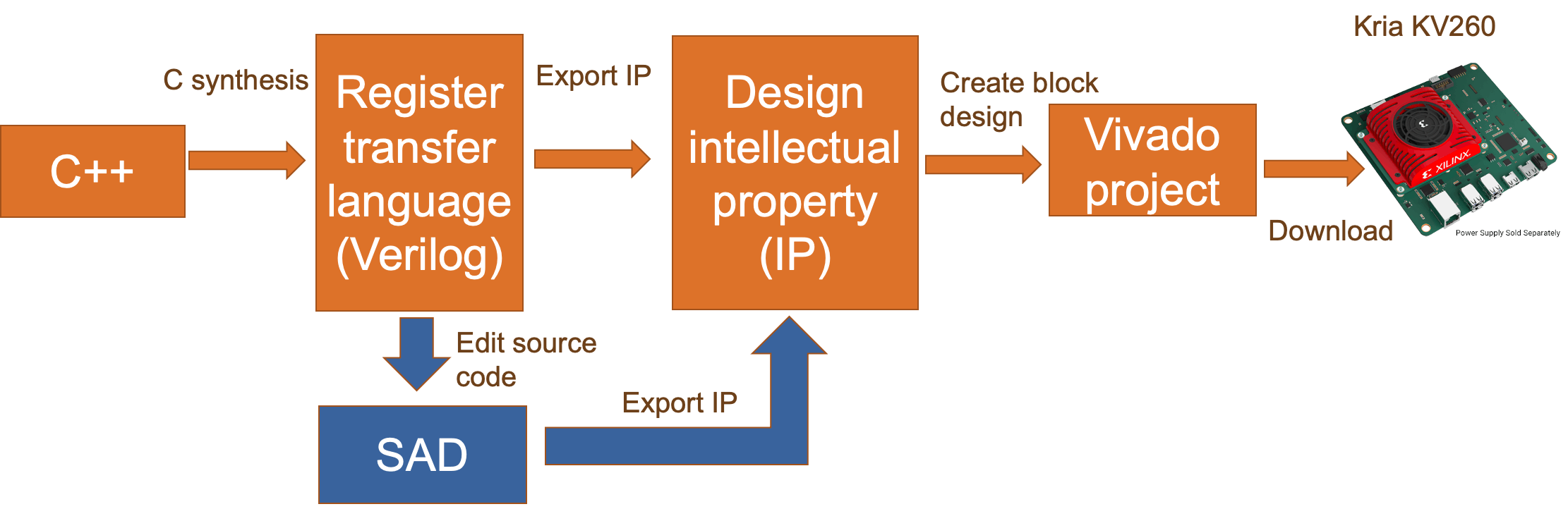
自動 HLS 和手動轉換
Xilinx Vitis HLS 上的自動綜合:
Xilinx Vitis HLS 可以從 C++ 代碼自動生成 FPGA 項目。
對于 CNN-ResNet-20,綜合報告顯示該項目的硬件符合我們的目的。
對于 ADD-ResNet-20,合成報告并沒有遵循我們之前的目的,因為 Vitis HLS 中的 C 合成不支持將 DSP48 配置為 SIMD 模式。
我們的解決方案:
將 SAD 操作設計為 C++ 中的獨立函數。
替換 Xilinx Vitis HLS 生成的 Verilog 源文件中的 SAD 代碼。
在 Xilinx Vivado 中重新綜合該項目。
此外,通過編輯 SAD 代碼,我們可以為 DSP48E2 配置更多選項。
?
Batch Normalization 融合可以減少計算量,并為模型量化提供更簡潔的結構。
如 Function.3 和 4 所示,將細化權重應用于卷積層作為原始推理。但是考慮左邊顯示的加法器層的功能,作為卷積添加到函數中的細化權重不能用作卷積層。
由于乘法和加法的開銷,這個函數不能提供 AdderNet 的硬件優勢。
為了避免這種開銷,我們使用額外的 for 循環來處理乘法和加法的開銷,這將花費更多的時鐘周期和硬件。
?
?

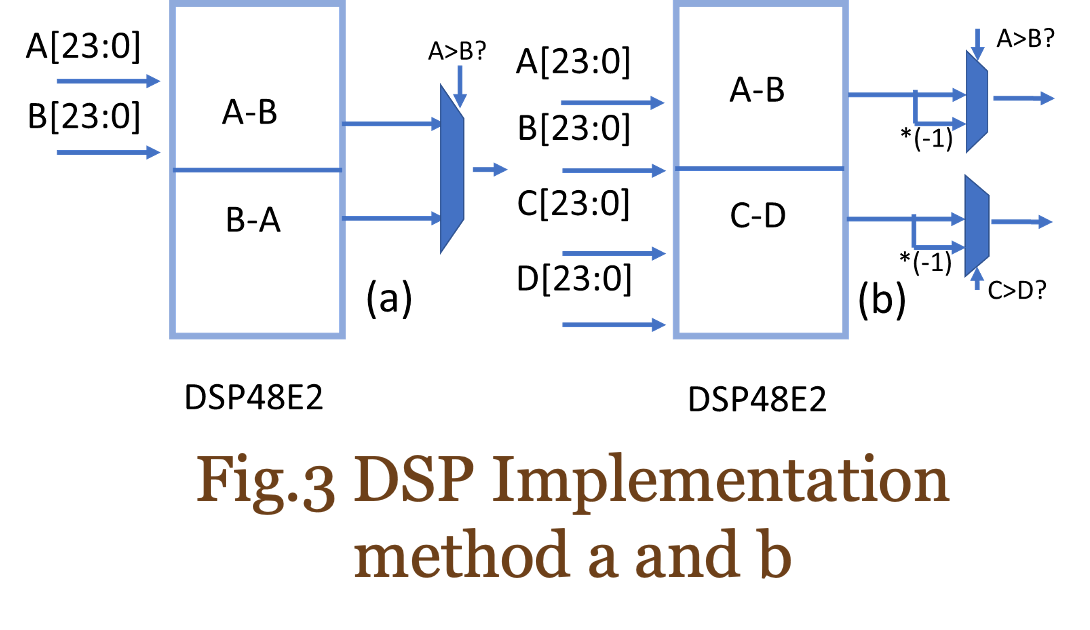
DSP配置方法
在本節中,將介紹兩種 DSP48E2 配置方法:
方法 a:利用與 CONV 相同數量的 DSP,但與方法 b 相比,LUT 更少。
方法 b:利用一半的 DSP 作為 CONV,但與方法 a 相比,LUT 更多。
?
?
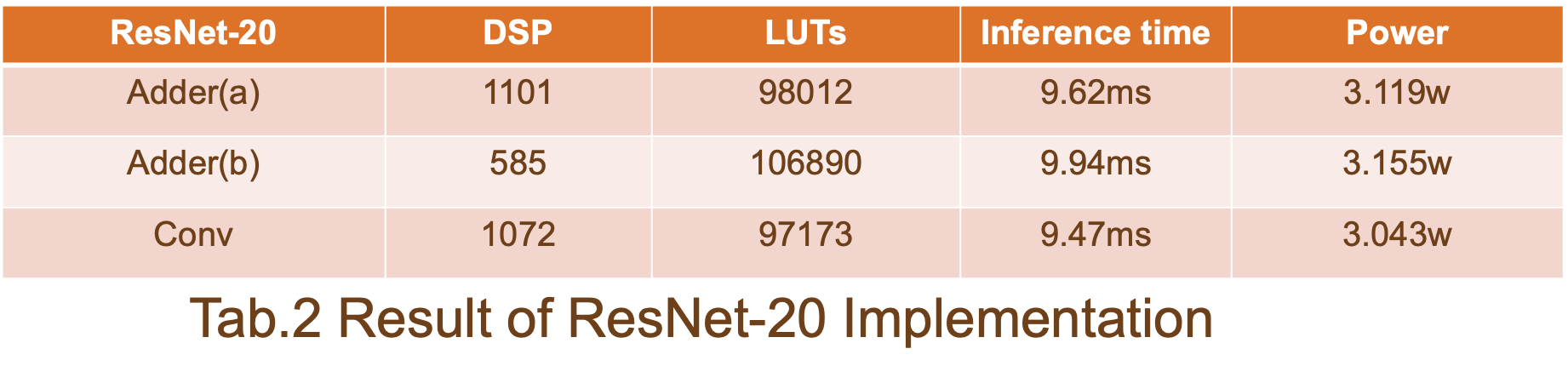
該報告顯示,通過比較解決方案 a、解決方案 b 和 ResNet-20 基線的結果,我們的方法可以以增加 10% 的 LUT 和 5% 的推理時間開銷為代價,減少大約 45% 的 DSP 利用率。
?
?
- Rapanda流加速器-實時流式FPGA加速器解決方案
- 《醫用電子直線加速器》pdf 0次下載
- 基于FPGA的SIMD卷積神經網絡加速器 24次下載
- 神經網絡加速器簡述 13次下載
- 基于深度學習的矩陣乘法加速器設計方案 3次下載
- 3小時學習神經網絡與深度學習課件下載 0次下載
- 深度模型中的優化與學習課件下載 3次下載
- 一種基于機器學習的流簇大小推理模型 34次下載
- 深度學習是什么?了解深度學習難嗎?讓你快速了解深度學習的視頻講解 16次下載
- 工具包和Eval板幫助加速加速器應用 13次下載
- Green網絡加速器 24次下載
- 加速器控制技術
- 蘭州重離子加速器冷卻儲存環高頻加速系統
- 實時頻譜分析儀(RSA)在加速器中的應用
- 基于Profibus和Ethernet的加速器高頻控制系統設
- FPGA和ASIC在大模型推理加速中的應用 605次閱讀
- Pytorch深度學習訓練的方法 238次閱讀
- 什么是神經網絡加速器?它有哪些特點? 545次閱讀
- 如何處理cache miss問題以提高加速器效率呢? 1534次閱讀
- 一個微型的粒子加速器 836次閱讀
- 硬件加速器提升下一代SHARC處理器的性能 1336次閱讀
- OpenCV+CUDA編譯實現YOLOv5能加速 2626次閱讀
- 充分利用數字信號處理器上的片內FIR和IIR硬件加速器 1806次閱讀
- 多智體深度強化學習研究中首次將概率遞歸推理引入AI的學習過程 4925次閱讀
- FPGA的深度學習加速器有怎樣的挑戰和機遇 6377次閱讀
- 有多快?華為云刷新深度學習加速紀錄 5241次閱讀
- 一種基于FPGA的高性能DNN加速器自動生成方案 5569次閱讀
- 斯坦福機器學習硬件加速器的課程學芯片技術機會來了 6163次閱讀
- Veloce仿真環境下的SoC端到端硬件加速器功能驗證 3691次閱讀
- 優化基于FPGA的深度卷積神經網絡的加速器設計 8093次閱讀

 上傳資料賺積分
上傳資料賺積分下載排行
本周
- 1山景DSP芯片AP8248A2數據手冊
- 1.06 MB | 532次下載 | 免費
- 2RK3399完整板原理圖(支持平板,盒子VR)
- 3.28 MB | 339次下載 | 免費
- 3TC358743XBG評估板參考手冊
- 1.36 MB | 330次下載 | 免費
- 4DFM軟件使用教程
- 0.84 MB | 295次下載 | 免費
- 5元宇宙深度解析—未來的未來-風口還是泡沫
- 6.40 MB | 227次下載 | 免費
- 6迪文DGUS開發指南
- 31.67 MB | 194次下載 | 免費
- 7元宇宙底層硬件系列報告
- 13.42 MB | 182次下載 | 免費
- 8FP5207XR-G1中文應用手冊
- 1.09 MB | 178次下載 | 免費
本月
- 1OrCAD10.5下載OrCAD10.5中文版軟件
- 0.00 MB | 234315次下載 | 免費
- 2555集成電路應用800例(新編版)
- 0.00 MB | 33566次下載 | 免費
- 3接口電路圖大全
- 未知 | 30323次下載 | 免費
- 4開關電源設計實例指南
- 未知 | 21549次下載 | 免費
- 5電氣工程師手冊免費下載(新編第二版pdf電子書)
- 0.00 MB | 15349次下載 | 免費
- 6數字電路基礎pdf(下載)
- 未知 | 13750次下載 | 免費
- 7電子制作實例集錦 下載
- 未知 | 8113次下載 | 免費
- 8《LED驅動電路設計》 溫德爾著
- 0.00 MB | 6656次下載 | 免費
總榜
- 1matlab軟件下載入口
- 未知 | 935054次下載 | 免費
- 2protel99se軟件下載(可英文版轉中文版)
- 78.1 MB | 537798次下載 | 免費
- 3MATLAB 7.1 下載 (含軟件介紹)
- 未知 | 420027次下載 | 免費
- 4OrCAD10.5下載OrCAD10.5中文版軟件
- 0.00 MB | 234315次下載 | 免費
- 5Altium DXP2002下載入口
- 未知 | 233046次下載 | 免費
- 6電路仿真軟件multisim 10.0免費下載
- 340992 | 191187次下載 | 免費
- 7十天學會AVR單片機與C語言視頻教程 下載
- 158M | 183279次下載 | 免費
- 8proe5.0野火版下載(中文版免費下載)
- 未知 | 138040次下載 | 免費





 工商網監
工商網監
評論