 電子發燒友App
電子發燒友App


人工智能的浪潮正在席卷全球,研究領域也在不斷擴大,深度學習和機器學習等名詞圍繞在我們周圍。又許多的創業者想要從事AI行業,深度學習是一個重要的學習領域。
近日,軟件工程師 James Le 在 Medium 上發表了一篇題為《The 10 Deep Learning Methods AI Practitioners Need to Apply》的文章,從反向傳播到最大池化最后到遷移學習,他在文中分享了主要適用于卷積神經網絡、循環神經網絡和遞歸神經網絡的10大深度學習方法。機器之心對本文進行了編譯,原文鏈接請見文末。
過去十年來,人們對機器學習興趣不減。你幾乎每天都會在計算機科學程序、行業會議和華爾街日報上看到機器學習。對于所有關于機器學習的討論,很多人把機器學習能做什么與希望其做什么混為一談。從根本上說,機器學習就是使用算法從原始數據中提取信息,并通過模型進行實現。我們使用這個模型來推斷我們尚未建模的其他數據。
神經網絡屬于機器學習模型的一種,已出現 50 多年,其基本單元即受到哺乳動物大腦中生物神經元啟發的非線性變換節點。神經元之間的連接也是仿效生物大腦,并在時間中通過訓練推移發展。
1980 年代中期和 1990 年代早期,神經網絡的很多重要架構取得重大進展。然而,獲得良好結果所需的時間和數據量卻阻礙了其應用,因此人們一時興趣大減。2000 年早期,計算能力呈指數級增長,業界見證了之前不可能實現的計算技術的「寒武紀爆炸」。深度學習作為該領域的一個重要競爭者是在這個十年的爆炸性計算增長中脫穎而出,它贏得了許多重要的機器學習競賽。深度學習的熱度在 2017 年達到峰值,你在機器學習的所有領域都可以看到深度學習。
下面是一個作業的結果,一個通過相似性聚類的詞向量的 t-SNE 投影。
最近,我已經開始閱讀相關學術論文。根據我的研究,下面是一些對該領域發展產生重大影響的著作:
紐約大學的《Gradient-Based Learning Applied to Document Recognition》(1998),介紹了機器學習領域的卷積神經網絡:http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
多倫多大學的《Deep Boltzmann Machines》(2009),它展現了一個用于玻爾茲曼機的、包含多個隱藏變量層的新學習算法:http://proceedings.mlr.press/v5/salakhutdinov09a/salakhutdinov09a.pdf
斯坦福大學和谷歌的《Building High-Level Features Using Large-Scale Unsupervised Learning》(2012),它解決了只從無標注數據中構建高階、特定類別的特征探測器的問題:http://icml.cc/2012/papers/73.pdf
伯克利大學的《DeCAF—A Deep Convolutional Activation Feature for Generic Visual Recognition》(2013),它推出了 DeCAF,一個深度卷積激活功能和所有相關網絡參數的開源實現,能夠幫助視覺研究者在一系列視覺概念學習范例中開展深度表征實驗:http://proceedings.mlr.press/v32/donahue14.pdf
DeepMind 的《Playing Atari with Deep Reinforcement Learning》(2016),它展示了借助強化學習直接從高維感知輸入中成功學習控制策略的首個深度學習模型:https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf
在研究和學習了大量知識之后,我想分享 10 個強大的深度學習方法,工程師可用其解決自己的機器學習問題。開始之前,讓我們定義一下什么是深度學習。深度學習是很多人面臨的一個挑戰,因為過去十年來它在緩慢改變著形式。為了形象化地界定深度學習,下圖給出了人工智能、機器學習和深度學習三者之間的關系。
?
人工智能領域最為廣泛,已存在 60+ 年。深度學習是機器學習的一個子領域,機器學習是人工智能的一個子領域。深度學習區分于傳統的前饋多層網絡的原因通常有以下幾點:
更多的神經元
層之間更復雜的連接方式
訓練算力的「寒武紀爆炸」
自動特征提取
當我說「更多的神經元」,我的意思是神經元數目逐年增長以表達更復雜的模型。層也從多層網絡中完全連接的每層發展到卷積神經網絡中層之間的局部連接的神經元補丁,以及與循環神經網絡中的同一神經元(除了與前一層的連接之外)的周期性連接。
接著深度學習可被定義為下面四個基本網絡架構之一中的帶有大量參數和層的神經網絡:
無監督預訓練網絡
卷積神經網絡
循環神經網絡
遞歸神經網絡
本文將主要介紹后面 3 個架構。卷積神經網絡基本是一個標準的神經網絡,通過共享權重在整個空間擴展。卷積神經網絡被設計為通過在內部卷積來識別圖像,可看到已識別圖像上物體的邊緣。循環神經網絡通過將邊緣饋送到下一個時間步而不是在同一時間步中進入下一層,從而實現整個時間上的擴展。循環神經網絡被設計用來識別序列,比如語音信號或文本序列,其內部循環可存儲網絡中的短時記憶。遞歸神經網絡更像是一個分層網絡,其中輸入序列沒有真正的時間維度,但輸入必須以樹狀方式進行分層處理。以下 10 種方法可被用于上述所有架構。
1. 反向傳播
反向傳播簡單地說就是一種計算函數(在神經網絡中為復合函數形式)的偏導數(或梯度)的方法。當使用基于梯度的方法(梯度下降只是其中一種)求解優化問題的時候,需要在每一次迭代中計算函數的梯度。

在神經網絡中,目標函數通常是復合函數的形式。這時如何計算梯度?有兩種方式:(i)解析微分(Analytic differentiation),函數的形式是已知的,直接使用鏈式法則計算導數就可以。(ii)利用有限差分的近似微分(Approximate differentiation using finite difference),這種方法的運算量很大,因為函數計算量(number of function evaluation)等于 O(N),其中 N 是參數數量。相比于解析微分,運算量大得多。有限差分通常在調試的時候用于驗證反向傳播的實現。
2. 隨機梯度下降
理解梯度下降的一種直觀的方法是想象一條河流從山頂順流而下的路徑。梯度下降的目標正好就是河流力爭實現的目標—即,到達最低點(山腳)。
假設山的地形使得河流在到達最低點之前不需要做任何停留(最理想的情況,在機器學習中意味著從初始點到達了全局最小/最優解)。然而,也存在有很多凹點的地形,使得河流在其路徑中途停滯下來。在機器學習的術語中,這些凹點被稱為局部極小解,是需要避免的情況。有很多種方法能解決這種問題(本文未涉及)。
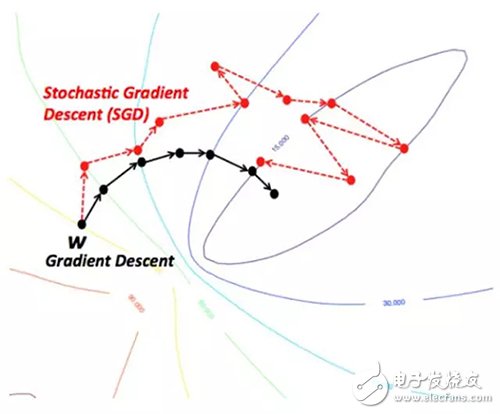
因此,梯度下降傾向于停滯在局部極小解,這取決于地形((或機器學習中的函數))的性質。但是,當山地的地形是一種特殊類型的時候,即碗形地貌,在機器學習中稱為凸函數,算法能保證找到最優解。凸函數是機器學習優化中最想遇到的函數。而且,從不同的山頂(初始點)出發,到達最低點之前的路徑也是不同的。類似地,河流的流速(梯度下降算法中的學習率或步長)的不同也會影響路徑的形態。這些變量會影響梯度下降是困在局域最優解還是避開它們。
3. 學習率衰減
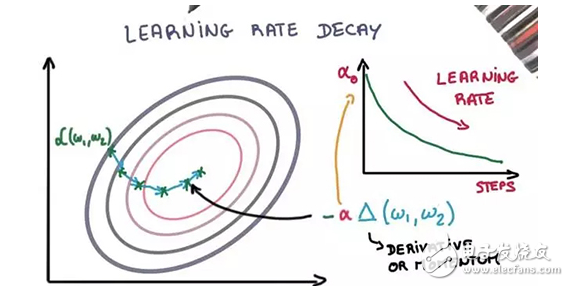
調整隨機梯度下降優化過程的學習率可以提升性能并減少訓練時間,稱為學習率退火(annealing)或適應性學習率。最簡單的也可能是最常用的訓練中的學習率調整技術是隨時間降低學習率。這有益于在訓練剛開始的時候使用更大的學習率獲得更大的變化,并在后期用更小的學習率對權重進行更精細的調整。
兩種簡單常用的學習率衰減方法如下:
隨 epoch 的增加而降低學習率;
在特定的 epoch 間斷地降低學習率。
4. dropout
擁有大量參數的深度神經網絡是很強大的機器學習系統。然而,這樣的網絡有很嚴重的過擬合問題。而且大型網絡的運行速度很慢,使得在測試階段通過結合多個不同大型神經網絡的預測解決過擬合的過程也變得很慢。dropout 正是針對這個問題應用的技術。
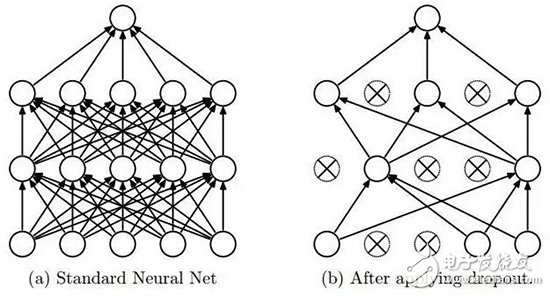
其關鍵的思想是在訓練過程中隨機刪除神經網絡的單元和相應的連接,從而防止過擬合。在訓練過程中,dropout 將從指數級數量的不同的稀疏網絡中采樣。在測試階段,很容易通過用單 untwined 網絡(有更小的權重)將這些稀疏網絡的預測取平均而逼近結果。這能顯著地降低過擬合,相比其它的正則化方法能得到更大的性能提升。dropout 被證明在監督學習任務比如計算機視覺、語音識別、文本分類和計算生物學中能提升神經網絡的性能,并在多個基準測試數據集中達到頂尖結果。
5. 最大池化
最大池化是一種基于樣本的離散化方法,目標是對輸入表征(圖像、隱藏層的輸出矩陣,等)進行下采樣,降低維度,并允許假設包含在子區域中的被丟棄的特征。
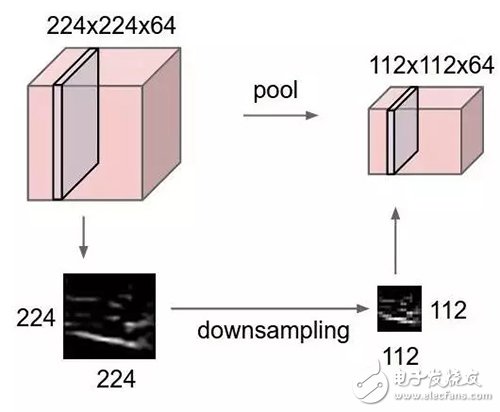
通過提供表征的抽象形式,這種方法在某種程度上有助于解決過擬合。同樣,它也通過減少學習參數的數量和提供基本的內部表征的轉換不變性減少了計算量。最大池化通過在初始表征的子區域(通常是非重疊的)取最大值而抽取特征與防止過擬合。
6. 批量歸一化
神經網絡(包括深度網絡)通常需要仔細調整權重初始化和學習參數。批量歸一化能使這個過程更簡單。
權重問題:
無論哪種權重初始化比如隨機或按經驗選擇,這些權重值都和學習權重差別很大。考慮在初始 epoch 中的一個小批量,在所需要的特征激活中可能會有很多異常值。
深度神經網絡本身就具有病態性,即初始層的微小變動就會導致下一層的巨大變化。
在反向傳播過程中,這些現象會導致梯度的偏離,意味著梯度在學習權重以生成所需要的輸出之前,需要對異常值進行補償,從而需要額外的 epoch 進行收斂。

批量歸一化會系統化梯度,避免因異常值出現偏離,從而在幾個小批量內直接導向共同的目標(通過歸一化)。
學習率問題:
學習率通常保持小值,從而使梯度對權重的修正很小,因為異常值激活的梯度不應該影響學習激活。通過批量歸一化,這些異常值激活會被降低,從而可以使用更大的學習率加速學習過程。
7. 長短期記憶
長短期記憶(LSTM)網絡的神經元和其它 RNN 中的常用神經元不同,有如下三種特征:
它對神經元的輸入有決定權;
它對上一個時間步中計算內容的存儲有決定權;
它對將輸出傳遞到下一個時間步的時間有決定權。
LSTM 的強大在于它能只基于當前的輸入就決定以上所有的值。看看下方的圖表:
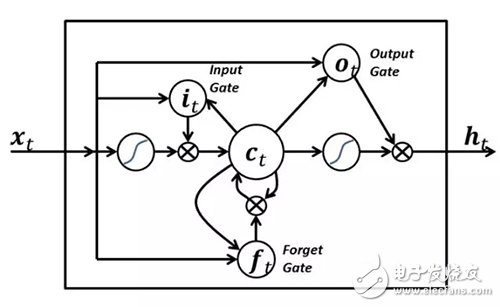
當前時間步的輸入信號 x(t) 決定了以上 3 個值。輸入門決定了第一個值,忘記門決定了第二個值,輸出門決定了第三個值。這是由我們的大腦工作方式所啟發的,可以處理輸入中的突然的情景變化。
8. Skip-gram
詞嵌入模型的目標是為每一個詞匯項學習一個高維密集表征,其中嵌入向量的相似表示相關詞的語義或句法的相似。skip-gram 是一種學習詞嵌入算法的模型。
skip-gram 模型(和很多其它詞嵌入模型)背后的主要思想是:如果兩個詞匯項有相似的上下文,則它們是相似的。
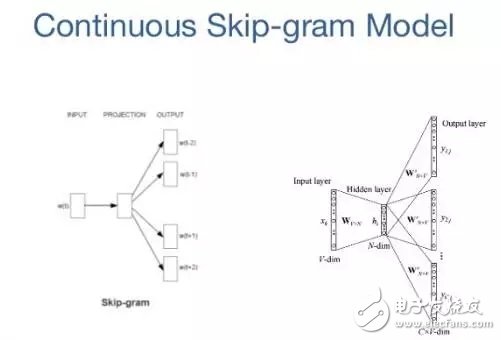
換種說法,假設你有一個句子,比如「cats are mammals」,如果用「dogs」替換「cats」,該句子仍然是有意義的。因此在這個例子中,「dogs」和「cats」有相似的上下文(即,「are mammals」)。
居于上述的假設,我們可以考慮一個上下文窗口,即一個包含 k 個連續項的窗口。然后我們應該跳過一些單詞以學習能得到除跳過項外其它所有的項的神經網絡,并用該神經網絡嘗試預測跳過的項。如果兩個詞在大型語料庫中共享相似的上下文,那么這些嵌入向量將有非常相近的向量。
9. 連續詞袋模型
在自然語言處理中,我們希望學習將文檔中每一個單詞表示為一個數值向量,并使得出現在相似上下文中的單詞有非常相似或相近的向量。在連續詞袋模型(CBOW)中,我們的目標是能利用特定詞的上下文而預測該特定詞出現的概率。

我們可以通過在大型語料庫中抽取大量語句而做到這一點。每當模型看到一個單詞時,我們就會抽取該特定單詞周圍出現的上下文單詞。然后將這些抽取的上下文單詞輸入到一個神經網絡以在上下文出現的條件下預測中心詞的概率。
當我們有成千上萬個上下文單詞與中心詞,我們就有了訓練神經網絡的數據集樣本。在訓練神經網絡中,最后經過編碼的隱藏層輸出特定單詞的嵌入表達。這種表達就正是相似的上下文擁有相似的詞向量,也正好可以用這樣一個向量表征一個單詞的意思。
10. 遷移學習
現在讓我們考慮圖像到底如何如何流經卷積神經網絡的,這有助于我們將一般 CNN 學習到的知識遷移到其它圖像識別任務。假設我們有一張圖像,我們將其投入到第一個卷積層會得到一個像素組合的輸出,它們可能是一些識別的邊緣。如果我們再次使用卷積,就能得到這些邊和線的組合而得到一個簡單的圖形輪廓。這樣反復地卷積最后就能層級地尋找特定的模式或圖像。因此,最后一層就會組合前面抽象的特征尋找一個非常特定的模式,如果我們的卷積網絡是在 ImageNet 上訓練的,那么最后一層將組合前面抽象特征識別特定的 1000 個類別。如果我們將最后一層替換為我們希望識別的類別,那么它就能很高效地訓練與識別。
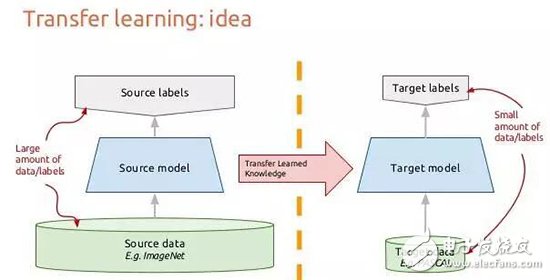
深度卷積網絡每一個層會構建出越來越高級的特征表征方式,最后幾層往往是專門針對我們饋送到網絡中的數據,因此早期層所獲得的特征更為通用。
遷移學習就是在我們已訓練過的 CNN 模型進行修正而得到的。我們一般會切除最后一層,然后再使用新的數據重新訓練新建的最后一個分類層。這一過程也可以解釋為使用高級特征重新組合為我們需要識別的新目標。這樣,訓練時間和數據都會大大減小,我們只需要重新訓練最后一層就完成了整個模型的訓練。
深度學習非常注重技術,且很多技術都沒有太多具體的解釋或理論推導,但大多數實驗結果都證明它們是有效的。因此也許從基礎上理解這些技術是我們后面需要完成的事情。

















 工商網監
工商網監
評論