 電子發燒友App
電子發燒友App


本書節選自圖書,Python本身帶有許多機器學習的第三方庫,但本書在絕大多數情況下只會用到Numpy這個基礎的科學計算庫來進行算法代碼的實現。這樣做的目的是希望讀者能夠從實現的過程中更好地理解機器學習算法的細節,以及了解Numpy的各種應用。不過作為補充,本書會在適當的時候應用scikit-learn這個成熟的第三方庫中的模型。
“機器學習”在最近雖可能不至于到人盡皆知的程度,卻也是非常火熱的詞匯。機器學習是英文單詞“Machine Learning”(簡稱ML)的直譯,從字面上便說明了這門技術是讓機器進行“學習”的技術。然而我們知道機器終究是死的,所謂的“學習”歸根結底亦只是人類“賦予”機器的一系列運算。這個“賦予”的過程可以有很多種實現,而Python正是其中相對容易上手、同時性能又相當不錯的一門語言。本文打算先談談機器學習相關的一些比較寬泛的知識,再介紹并說明為何要使用Python來作為機器學習的工具。最后,我們會提供一個簡短易懂的、具有實際意義的例子來給大家提供一個直觀的感受。
具體而言,本章主要涉及的知識點有:
機器學習的定義及重要性;
Python在機器學習領域的優異性;
如何在電腦上配置Python機器學習的環境;
機器學習一般性的步驟。
機器學習緒論
正如前言所說,由于近期的各種最新成果,使得“機器學習”成為了非常熱門的詞匯。機器學習在各種領域的優異表現(圍棋界的Master是其中最具代表性的存在),使得各行各業的人們都或多或少地對機器學習產生了興趣與敬畏。然而與此同時,對機器學習有所誤解的群體也日益壯大;他們或將機器學習想得過于神秘,或將它想得過于萬能。本節擬對機器學習進行一般性的介紹,同時會說明機器學習中一些常見的術語以方便之后章節的敘述。
什么是機器學習
清晨的一句“今天天氣真好”、朋友之間的寒暄“你剛剛是去吃飯了吧”、考試過后的感嘆“復習了那么久終有收獲”……這些日常生活中隨處可見的話語,其背后卻已蘊含了“學習”的思想—它們都是利用以往的經驗、對未知的新情況作出的有效的決策。而把這個決策的過程交給計算機來做,可以說就是“機器學習”的一個最淺白的定義。
我們或許可以先說說機器學習與以往的計算機工作樣式有什么不同。傳統的計算機如果想要得到某個結果,需要人類賦予它一串實打實的指令,然后計算機就根據這串指令一步步地執行下去。這個過程中的因果關系非常明確,只要人類的理解不出偏差,運行結果是可以準確預測的。但是在機器學習中,這一傳統樣式被打破了:計算機確實仍然需要人類賦予它一串指令,但這串指令往往不能直接得到結果;相反,它是一串賦予了機器“學習能力”的指令。在此基礎上,計算機需要進一步地接受“數據”,并根據之前人類賦予它的“學習能力”,從中“學習”出最終的結果。這個結果往往是無法僅僅通過直接編程得出的。因此這里就導出了稍微深一點的機器學習的定義:它是一種讓計算機利用數據而非指令來進行各種工作的方法。在這背后,最關鍵的就是“統計”的思想,它所推崇的“相關而非因果”的概念是機器學習的理論根基。在此基礎上,機器學習可以說是計算機使用輸入給它的數據,利用人類賦予它的算法得到某種模型的過程,其最終的目的則是使用該模型,預測未來未知數據的信息。
既然提到了統計,那么一定的數學理論就不可或缺。相關的、比較簡短的定義會在第4章給出(PAC框架),這里我們就先只敘述機器學習在統計理論下的、比較深刻的本質:它追求的是合理的假設空間(Hypothesis Space)的選取和模型的泛化(Generalization)能力。該句中出現了一些專用術語,詳細的定義會在介紹術語時提及,這里我們提供一個直觀的理解:
所謂的假設空間,就是我們的模型在數學上的“適用場合”。
所謂的泛化能力,就是我們的模型在未知數據上的表現。
注意:上述本質上嚴格來說,應該是PAC Learning的本質;在其余的理論框架下,機器學習是可以具有不同的內核的。
從上面的討論可以看出,機器學習和人類思考的過程有或多或少的類似。事實上,我們在第6、第7章講的神經網絡(Neural Network,NN)和卷積神經網絡(Convolutional Neural Network,CNN)背后確實有著相應的神經科學的理論背景。然而與此同時需要知道的是,機器學習并非是一個“會學習的機器人”和“具有學習能力的人造人”之類的,這一點從上面諸多討論也可以明晰(慚愧的是,筆者在第一次聽到“機器學習”四個字時,腦海中浮現的正是一個“聰明的機器人”的圖像,甚至還幻想過它和人類一起生活的場景)。相反的,它是被人類利用的、用于發掘數據背后信息的工具。
當然,現在也不乏“危險的人工智能”的說法,霍金大概是其中的“標桿”,這位偉大的英國理論物理學家甚至警告說“人工智能的發展可能意味著人類的滅亡”。孰好孰壞果然還是見仁見智,但可以肯定的是:本書所介紹的內容絕不至于導致世界的毀滅,大家大可輕松愉快地進行接下來的閱讀!
機器學習常用術語
機器學習領域有著許多非常基本的術語,這些術語在外人聽來可能相當高深莫測。它們事實上也可能擁有非常復雜的數學背景,但需要知道:它們往往也擁有著相對淺顯平凡的直觀理解(上一小節的假設空間和泛化能力就是兩個例子)。本小節會對這些常用的基本術語進行說明與解釋,它們背后的數學理論會有所闡述,但不會涉及過于本質的東西。
正如前文反復強調的,數據在機器學習中發揮著不可或缺的作用;而用于描述數據的術語有好幾個,需要被牢牢記住的如下。
“數據集”(Data Set),就是數據的集合的意思。其中,每一條單獨的數據被稱為“樣本”(Sample)。若沒有進行特殊說明,本書都會假設數據集中樣本之間在各種意義下相互獨立。事實上,除了某些特殊的模型(如隱馬爾可夫模型和條件隨機場),該假設在大多數場景下都是相當合理的。
對于每個樣本,它通常具有一些“屬性”(Attribute)或者說“特征”(Feature),特征所具體取的值就被稱為“特征值”(Feature Value)。
特征和樣本所張成的空間被稱為“特征空間”(Feature Space)和“樣本空間”(Sample Space),可以把它們簡單地理解為特征和樣本“可能存在的空間”。
相對應的,我們有“標簽空間”(Label Space),它描述了模型的輸出“可能存在的空間”;當模型是分類器時,我們通常會稱之為“類別空間”。
其中、數據集又可以分為以下三類:
訓練集(Training Set);顧名思義,它是總的數據集中用來訓練我們模型的部分。雖說將所有數據集都拿來當作訓練集也無不可,不過為了提高及合理評估模型的泛化能力,我們通常只會取數據集中的一部分來當訓練集。
測試集(Test Set);顧名思義,它是用來測試、評估模型泛化能力的部分。測試集不會用在模型的訓練部分,換句話說,測試集相對于模型而言是“未知”的,所以拿它來評估模型的泛化能力是相當合理的。
交叉驗證集(Cross-Validation Set,CV Set);這是比較特殊的一部分數據,它是用來調整模型具體參數的。
注意:需要指出的是,獲取數據集這個過程是不平凡的;尤其是當今“大數據”如日中天的情景下,諸如“得數據者得天下”的說法也不算誑語。在此筆者推薦一個非常著名的含有大量真實數據集的網站: ,本書常常會用到其中一些合適的數據集來評估我們自己實現的模型。
可以通過具體的例子來理解上述概念。比如,我們假設小明是一個在北京讀了一年書的學生,某天他想通過宿舍窗外的風景(能見度、溫度、濕度、路人戴口罩的情況等)來判斷當天的霧霾情況并據此決定是否戴口罩。此時,他過去一年的經驗就是他擁有的數據集,過去一年中每一天的情況就是一個樣本。“能見度”、“溫度”、“濕度”、“路人戴口罩的情況”就是四個特征,而(能見度)“低”、(溫度)“低”、(濕度)“高”、(路人戴口罩的)“多”就是相對應的特征值。現在小明想了想,決定在腦中建立一個模型來幫自己做決策,該模型將利用過去一年的數據集來對如今的情況做出“是否戴口罩”的決策。此時小明可以用過去一年中8個月的數據量來做訓練集、2個月的量來做測試集、2個月的量來做交叉驗證集,那么小明就需要不斷地思考(訓練模型)下列問題:
用訓練集訓練出的模型是怎樣的?
該模型在交叉驗證集上的表現怎么樣?
. 如果足夠好了,那么思考結束(得到最終模型)。
. 如果不夠好,那么根據模型在交叉驗證集上的表現,重新思考(調整模型參數)
最后,小明可能會在測試集上評估自己剛剛思考后得到的模型的性能,然后根據這個性能和模型做出的“是否戴口罩”的決策來綜合考慮自己到底戴不戴口罩。
接下來說明上一小節中提到過的重要概念:假設空間與泛化能力。泛化能力的含義在上文也有說明,為強調起見,這里再敘述一遍:
泛化能力針對的其實是學習方法,它用于衡量該學習方法學習到的模型在整個樣本空間上的表現。
這一點當然是十分重要的,因為我們拿來訓練模型的數據終究只是樣本空間的一個很小的采樣,如果只是過分專注于它們,就會出現所謂的“過擬合”(Over Fitting)的情況。當然,如果過分罔顧訓練數據,又會出現“欠擬合”(Under Fitting)。可以用一張圖來直觀地感受過擬合和欠擬合(如圖1所示,左為欠擬合,右為過擬合)。
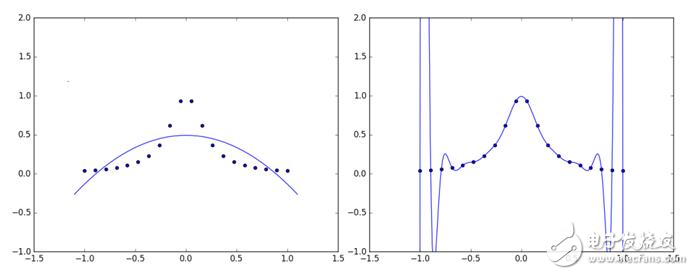
圖1 欠擬合與過擬合
所以需要“張弛有度”,找到最好的那個平衡點。統計學習中的結構風險最小化(Structural Risk Minimization,SRM)就是研究這個的,它和傳統的經驗風險最小化(Empirical Risk Minimization,ERM)相比,注重于對風險上界的最小化,而不是單純地使經驗風險最小化。它有一個原則:在使風險上界最小的函數子集中挑選出使經驗風險最小的函數。而這個函數子集,正是我們之前提到過的假設空間。
注意:所謂經驗風險,可以理解為訓練數據集上的風險。相對應的,ERM則可以理解為只注重訓練數據集的學習方法,它的理論基礎是經驗風險在某種足夠合理的數學意義上一致收斂于期望風險,亦即所謂的“真正的”風險。
關于SRM和ERM的詳細討論會涉及諸如VC維和正則化的概念,這里不進行詳細展開,但需要有這么一個直觀的認識:為了使我們學習方法訓練出的模型泛化能力足夠好,需要對模型做出一定的“限制”,而這個“限制”就表現在假設空間的選取上。一個非常普遍的做法是對模型的復雜度做出一定的懲罰,從而使模型趨于精簡。這與所謂的“奧卡姆剃刀原理”不謀而合:“如無必要,勿增實體”“切勿浪費較多的東西去做,用較少的東西、同樣可以做好事情”。
相比起通過選取合適的假設空間來規避過擬合,進行交叉驗證(Cross Validation)則可以讓我們知道過擬合的程度,從而幫助我們選擇合適的模型。常見的交叉驗證有以下三種。
S-fold Cross Validation:中文可翻譯成S折交叉驗證,它是應用最多的一種方法,其方法大致如下。
. 將數據分成S份:D={D_1,D_2,…,D_S},一共做S次試驗。
. 在第i次試驗中,使用D-D_i作為訓練集,D_i作為測試集對模型進行訓練和評測。
. 最終選擇平均測試誤差最小的模型。
留一交叉驗證(Leave-one-out Cross Validation):這是S折交叉驗證的特殊情況,此時S=N。
簡易交叉驗證:這種實現起來最簡單,也是本書(在進行交叉驗證時)所采用的方法。它簡單地將數據進行隨機分組,最后達到訓練集約占原數據70%的程度(這個比例可以視情況改變),選擇模型時使用測試誤差作為標準。
機器學習的重要性
道理說了不少,但到底為什么要學機器學習,機器學習的重要性又在哪里呢?事實上,回顧歷史可以發現,人類的發展通常伴隨著簡單體力勞動向復雜腦力勞動的過渡。過去的工作基本上都有著明確的定義,告訴你這一步怎么做、下一步再怎么做。而如今這一類的工作已經越來越少,取而代之的是更為寬泛模糊的、概念性的東西,比如說“將本季度的產品推向最合適的市場,在最大化期望利潤的同時,盡量做到風險最小化”這種需求。想要完成好這樣的任務,需要獲取相應的數據;雖說網絡的存在讓我們能夠得到數之不盡的數據,然而從這些數據中獲得信息與知識卻不是一項簡單的工作。我們當然可以人工地、仔細地逐項甄選,但這樣顯然就又回到了最初的原點。機器學習這門技術,可以說正因此應運而生。
單單抽象地說一大堆空話可能會讓人頭昏腦漲,我們就舉一舉機器學習具體的應用范圍,從中大概能夠比較直觀地看出機器學習的強大與重要。
發展到如今,機器學習的“爪牙”可謂已經伸展到了各個角落、包括但不限于:
語音識別,也就是微軟Cortana背后的核心技術;
數據挖掘,也就是耳熟能詳的大數據相關的領域;
統計學習,也就是本書講解的主要范圍之一,有許許多多著名的算法(比如支持向量機SVM)都源于統計學習(但是統計學習還是和機器學習有區別的;簡單地說,統計學習偏數學而機器學習偏實踐)。
機器學習還能夠進行模式識別、自然語言處理,等等,之前提到過的圍棋界的Master和最新人工智能在德州撲克上的表現亦無不呈現著機器學習強大的潛力。一言以蔽之,機器學習是當今的熱點,雖說不能保證它的熱度能100%地一直延續下去,至少筆者認為、它能在相當長的一段時間內保持強大的生命力。
人生苦短,我用Python
上一節大概地介紹了機器學習的各種概念,這一節我們主要講講腳本語言Python相關的一些東西。題目是在Python界流傳甚廣的“諺語”,它講述了Python強大的功能與易于上手的特性。
為何選擇Python
援引開源運動的領袖人物Eric Raymond的說法:“Python語言非常干凈,設計優雅,具有出色的模塊化特性。其最出色的地方在于,鼓勵清晰易讀的代碼,特別適合以漸進開發的方式構造項目”。Python的可讀性使得即使是剛學不久的人也能看懂大部分的代碼,Python龐大的社區和大量的開發文檔更是使得初學者能夠快速地實現許許多多令人驚嘆的功能。對于Python的程序,人們甚至有時會戲稱其為“可執行的偽代碼(executable pseudo-code)”,以突顯它的清晰性和可讀性。
Python的強大是毋庸置疑的,上文提到的Eric Raymond甚至稱其“過于強大了”。與之相對應的,就是Python的速度比較慢。然而比起Python開發環境提供的海量高級數據結構(如列表、元組、字典、集合等)和數之不盡的第三方庫,再加上高速的CPU和近代發展起來的GPU編程,速度的問題就顯得沒那么尖銳了。況且Python還能通過各種途徑使用C / C++代碼來編寫核心代碼,其強大的“膠水”功能使其速度(在程序員能力允許的情況下)和純粹的C / C++相比已經相去不遠。一個典型的例子,也是我們會在本書常常運用到的Python中Numpy這個第三方庫。編寫它的語言正是底層語言(C和Fortran),其支持向量、矩陣操作的特性和優異的速度,使得Python在科學計算這一領域大放異彩。
注意:Python及本書用到的兩個非常優異的第三方庫—Numpy和TensorFlow的簡要教程我們會作為附錄章節放在本書的最后,建議有需要的讀者先閱讀相應部分。
Python 在機器學習領域的優勢
雖然在上一小節敘述了Python的種種好處,但不可否認的是,確實存在諸如MATLAB和Mathematica這樣的高級程序語言。它們對機器學習的支持也不錯,MATLAB甚至還自帶許多機器學習的應用。但是作為一個問心無愧的程序員,我們還是需要提倡支持正版,而MATLAB的正版軟件需要花費數千美元。與之相對,由于Python是開源項目,幾乎所有必要的組件都是完全免費的。
之前也提到過Python的速度問題,但是更快更底層的語言,比如C和C++,若使用它們來學習機器學習,會不可避免地引發這么一個問題:即使是實現一個非常簡單的功能,也需要進行大量的編寫和調試的過程;在這期間,程序員很有可能忘掉學習機器學習的初衷而迷失在代碼的海洋中。筆者曾經嘗試過將Python上的神經網絡框架移植到C++上,這之間的折騰至今難忘。
此外,筆者認為、使用Python來學習機器學習是和“不要過早優化”這句編程界的金句有著異曲同工之妙的。Python(幾乎)唯一的缺陷—速度,在初期進行快速檢驗算法、思想正誤及開發工作時,其實基本上不是重要問題。其中的道理是顯而易見的:如果解決問題的思想存在問題,那么即使拼命去提高程序的運行效率,也只能使問題越來越大而已。這種時候,先使用Python進行快速實現,有必要時再用底層代碼重寫核心代碼,從各方面來說都是一個更好的選擇。
關于Anaconda
Python的強大有相當大一部分體現在它那浩如煙海的第三方庫。在使用Python實現一個復雜功能時,如果沒有特殊的需求,我們通常會先搜索Google有沒有現成的第三方庫,然后會搜索是否有相關聯的第三方庫,最后才會考慮自己重頭實現。
第三方庫是如此之多,從中挑選出心儀而合適的并非易事。幸運的是,就連這一點也有第三方軟件進行了支持,那就是在Python科學計算領域非常出名的Anaconda。這是一個完全免費的軟件,經常會進行各種更新;最重要的是,它把幾乎所有常用且優異的科學計算庫都集成在了一起。換句話說,只要你安裝了Anaconda,就意味著擁有了一個完善精致的機器學習環境,基本上無須自己把要用到的庫一個一個通過命令行來安裝。
第一個機器學習樣例
作為本章的總結,我們來運用Python解決一個實際問題,以便對機器學習有一個具體的感受。由于該樣例只是為了提供直觀感受,我們就拿比較有名的一個小問題來進行闡述。俗話說:“麻雀雖小,五臟俱全”,我們完全可以通過這個樣例來對機器學習的一般性步驟進行一個大致的認知。
該問題來自Coursera上的斯坦福大學機器學習課程,其敘述如下:現有47個房子的面積和價格,需要建立一個模型對新的房價進行預測。稍微翻譯問題,可以得知:
輸入數據只有一維,亦即房子的面積。
目標數據也只有一維,亦即房子的價格。
需要做的,就是根據已知的房子的面積和價格的關系進行機器學習。
下面我們就來一步步地進行操作。
獲取與處理數據
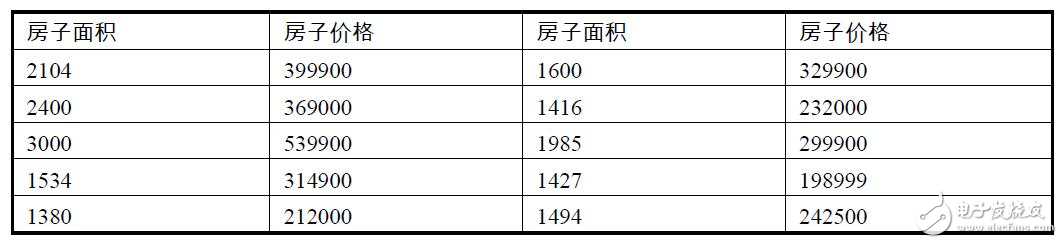
原始數據集的前10個樣本如表1.1所示,這里房子面積和房子價格的單位可以隨意定奪,因為它們不會對結果造成影響。
表1.1 房價數據集
完整的數據集可以參見 https://github.com/carefree0910/MachineLearning/blob/master/ _Data/prices.txt 。雖然該數據集比較簡單,但可以看到其中的數字都相當大。保留它原始形式確實有可能是有必要的,但一般而言,我們應該對它做簡單的處理以期望降低問題的復雜度。在這個例子里,采取常用的將輸入數據標準化的做法,其數學公式為:
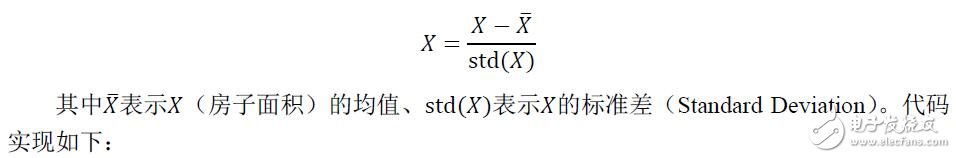
代碼1-1 第一個機器學習樣例:a_FirstExample\Regression.py
01 # 導入需要用到的庫
02 import numpy as np
03 import matplotlib.pyplot as plt
04
05 # 定義存儲輸入數據(x)和目標數據(y)的數組
06 x, y = [], []
07 # 遍歷數據集,變量sample對應的正是一個個樣本
08 for sample in open("../_Data/prices.txt", "r"):
09 # 由于數據是用逗號隔開的,所以調用Python中的split方法并將逗號作為參數傳入
10 _x, _y = sample.split(",")
11 # 將字符串數據轉化為浮點數
12 x.append(float(_x))
13 y.append(float(_y))
14 # 讀取完數據后,將它們轉化為Numpy數組以方便進一步的處理
15 x, y = np.array(x), np.array(y)
16 # 標準化
17 x = (x - x.mean()) / x.std()
18 # 將原始數據以散點圖的形式畫出
19 plt.figure()
20 plt.scatter(x, y, c="g", s=6)
21 plt.show()
上面這段代碼的運行結果如圖2所示。
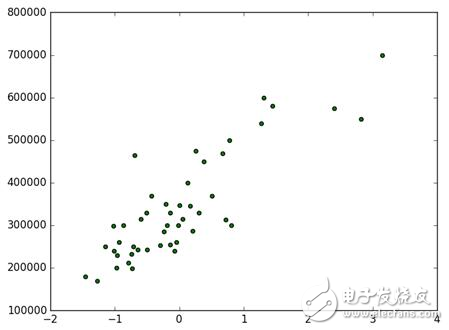
圖2 預處理后的數據散點圖
這里橫軸是標準化后的房子面積,縱軸是房子價格。以上我們已經比較好地完成了機器學習任務的第一步:數據預處理。
選擇與訓練模型
在弄好數據之后,下一步就要開始選擇相應的學習方法和模型了。幸運的是,通過可視化原始數據,可以非常直觀地感受到:很有可能通過線性回歸(Linear Regression)中的多項式擬合來得到一個不錯的結果。其模型的數學表達式如下。
注意:用多項式擬合散點只是線性回歸的很小的一部分,但是它的直觀意義比較明顯。考慮到問題比較簡單,我們才選用了多項式擬合。線性回歸的詳細討論超出了本書的范圍,這里不再贅述。
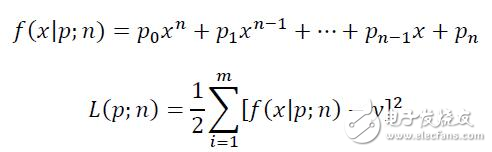
其中f(x|p;n)就是我們的模型,p、n都是模型的參數,其中p是多項式f的各個系數,n是多項式的次數。L(p;n)則是模型的損失函數,這里我們采用了常見的平方損失函數,也就是所謂的歐氏距離(或說向量的二范數)。x、y則分別是輸入向量和目標向量;在我們這個樣例中,x、y這兩個向量都是47維的向量,分別由47個不同的房子面積、房子價格所構成。
在確定好模型后,就可以開始編寫代碼來進行訓練了。對于大多數機器學習算法,所謂的訓練正是最小化某個損失函數的過程,這個多項式擬合的模型也不例外:我們的目的就是讓上面定義的L(p;n)最小。在數理統計領域里有專門的理論研究這種回歸問題,其中比較有名的正規方程更是直接給出了一個簡單的解的通式。不過由于有Numpy的存在,這個訓練過程甚至變得還要更加簡單一些。
22 # 在(-2,4)這個區間上取100個點作為畫圖的基礎
23 x0 = np.linspace(-2, 4, 100)
24 # 利用Numpy的函數定義訓練并返回多項式回歸模型的函數
25 # deg參數代表著模型參數中的n,亦即模型中多項式的次數
26 # 返回的模型能夠根據輸入的x(默認是x0),返回相對應的預測的y
27 def get_model(deg):
28 return lambda input_x=x0: np.polyval(np.polyfit(x, y, deg), input_x)
這里需要解釋Numpy里面帶的兩個函數:polyfit和polyval的用法。
polyfit(x, y, deg):該函數會返回使得上述
(注:該公式中的x和y就是輸入的x和y)最小的參數p,亦即多項式的各項系數。換句話說,該函數就是模型的訓練函數。
polyval(p, x):根據多項式的各項系數p和多項式中x的值,返回多項式的值y。
29 # 根據參數n、輸入的x、y返回相對應的損失
30 def get_cost(deg, input_x, input_y):
31 return 0.5 * ((get_model(deg)(input_x) - input_y) ** 2).sum()
32 # 定義測試參數集并根據它進行各種實驗
33 test_set = (1, 4, 10)
34 for d in test_set:
35 # 輸出相應的損失
36 print(get_cost(d, x, y))
所得的結果是:當n=1,4,10時,損失的頭兩位數字分別為96、94和75。這么看來似乎是n=10優于n=4,而n=1最差,但從圖3可以看出,似乎直接選擇n=1作為模型的參數才是最好的選擇。這里矛盾的來源正是前文所提到過的過擬合情況。

圖3 線性回歸的可視化
那么,怎么最直觀地了解是否出現過擬合了呢?當然還是畫圖了。
37 # 畫出相應的圖像
38 plt.scatter(x, y, c="g", s=20)
39 for d in test_set:
40 plt.plot(x0, get_model(d)(), label="degree = {}".format(d))
41 # 將橫軸、縱軸的范圍分別限制在(-2,4)、(〖10〗^5,8×〖10〗^5)
42 plt.xlim(-2, 4)
43 plt.ylim(1e5, 8e5)
44 # 調用legend方法使曲線對應的label正確顯示
45 plt.legend()
46 plt.show()
上面這段代碼的運行結果如圖3所示。
其中,三條線分別代表n=1、n=4、n=10的情況(圖1.10的右上角亦有說明)。可以看出,從n=4開始模型就已經開始出現過擬合現象了,到n=10時模型已經變得非常不合理。
至此,可以說這個問題就已經基本上解決了。在這個樣例里面,除了交叉驗證,我們涵蓋了機器學習中的大部分主要步驟(之所以沒有進行交叉驗證是因為數據太少了……)。代碼部分加起來總共40~50行,應該算是一個比較合適的長度。希望大家能夠通過這個樣例對機器學習有個大概的了解,也希望它能引起大家對機器學習的興趣。
本章小結
與傳統的計算機程序不同,機器學習是面向數據的算法,能夠從數據中獲得信息。它符合新時代腦力勞動代替體力勞動的趨勢,是富有生命力的領域。
Python是一門優異的語言,代碼清晰可讀、功能廣泛強大。其最大弱點—速度問題也可以通過很多不太困難的方法彌補。
Anaconda是Python的一個很好的集成環境,它能讓我們免于人工地安裝大量科學計算所需要的第三方庫。
雖說機器學習算法很多,但通常而言,進行機器學習的過程會包含以下三步:
. 獲取與處理數據;
. 選擇與訓練模型;
. 評估與可視化結果。














 工商網監
工商網監
評論