 電子發燒友App
電子發燒友App


語音識別技術并不是一項新興的技術,并且技術門檻也不算太高。在需求巨大的智能家居市場語音識別能否代替智能手機成為另一大入口?全球范圍內哪些廠商在布局語音識別技術,語音是識別的技術原理和難點又在哪?
物聯網市場潛力巨大應用眾多,在繁多的應用中智能家居或許能優先落地。不過,除了物聯網標準和觀念阻礙智能家居的發展,手機作為目前首要的入口也大大影響了體驗。語音識別并不是一項新興的技術,但在智能家居甚至人工智能領域或許能大展身手。
物聯網與智能家居市場潛力可期
市場研究咨詢公司Gartner預測,2020年全球物聯網終端設備的出貨量將達到66億,而物聯網設備數量總數將達到208億,花費在物聯網上的總支出將達到約2420億美元。
Gartner同時預測,2017年以后智能家居將成為物聯網最大的用戶。有機構預測2016年中國智能家居市場規模增速將達到50.1% ,并保持這一增速,到2018年中國智能家居市場規模將達到1396億元,市場規模約占全球總規模的32%,2020年中國智能家居市場規模將達到3000多億元。全球TOP100電信運營商中已有60%計劃進軍智能家居市場更讓我們有理由相信智能家居將會成為最先落地的物聯網應用。
智能家居入口單一
無論是在正式還是非正式場合,談起智能家居總能聽到手機作為唯一入口的抱怨。舉個簡單的例子,當你安裝了智能燈具,但你想要打開或調整還要先找到手機打開APP。這時候可能很多人會選擇直接用開關解決問題而非使用手機。
智能家居的愿景很好,但目前的體驗確實還有很大的提升空間。關于手機作為智能家居的唯一入口的問題,艾拉物聯的聯合創始人、大中華區總裁Phillip張南雄就表示:“手機可能不是智能家居甚至物聯網的唯一入口,語音識別是一個很大的入口。”美的智慧總經理李強也表示,手機作為智能家居唯一入口的局面將被改變。
語音識別成為爭奪焦點
據悉,全球范圍人工智能公司多專攻深度學習方向,而我國人工智能方向的200家左右的創業公司有超過70%的公司主攻圖像或語音識別這兩個分類。全球都有哪些公司在布局語音識別?他們的發展情況又如何?
其實,早在計算機發明之前,自動語音識別的設想就已經被提上了議事日程,早期的聲碼器可被視作語音識別及合成的雛形。最早的基于電子計算機的語音識別系統是由AT&T貝爾實驗室開發的Audrey語音識別系統,它能夠識別10個英文數字。到1950年代末,倫敦學院(Colledge of London)的Denes已經將語法概率加入語音識別中。
1960年代,人工神經網絡被引入了語音識別。這一時代的兩大突破是線性預測編碼Linear Predictive Coding (LPC),及動態時間規整Dynamic Time Warp技術。語音識別技術最重大的突破是隱含馬爾科夫模型Hidden Markov Model的應用。從Baum提出相關數學推理,經過Rabiner等人的研究,卡內基梅隆大學的李開復最終實現了第一個基于隱馬爾科夫模型的大詞匯量語音識別系統Sphinx。
蘋果Siri
許多人認識語音識別可能還得歸功于蘋果鼎鼎大名的語音助手Siri。2011年蘋果將語音識別技術融入到iPhone 4S中并發布了Siri語音助理,不過Siri并不是蘋果研發的技術,而是收購成立于2007年的Siri Inc.這家公司獲得的技術。在iPhone4s發布以后,Siri的體驗并不理想,遭到了吐槽。因此,2013年蘋果又收購了Novauris Technologies。Novauris是一種可識別整個短語的語音識別技術,這種技術并非簡單識別單個詞句,而是試圖利用超過2.45億個短語的識別輔助理解上下文,這讓Siri的功能進一步完善。
不過Siri并沒有因為收購Novauris變得完美,2016年蘋果又收購了開發的人工智能軟件,能夠幫助計算機與用戶進行更為自然的對話英國語音技術初創公司VocalIQ。隨后,蘋果還收購了美國圣地牙哥 AI 技術公司 Emotient,接收其臉部表情分析與情緒辨別技術。據悉,Emotient開發的情緒引擎可讀取人們的面部表情并且預測其情緒狀態。
谷歌 Google Now
與蘋果Siri類似,谷歌的Google Now知名度也比較高。不過相比蘋果谷歌在語音識別領域的動作稍顯遲緩。2011年谷歌才出手收購語音通信公司SayNow和語音合成公司Phonetic Arts。SayNow可以把語音通信、點對點對話、以及群組通話和Facebook、Twitter、MySpace、Android和 iPhone等等應用等整合在一起,而Phonetic Arts可以把錄制的語音對話轉化成語音庫,然后把這些聲音結合到一起,從而生成聽上去非常逼真的人聲對話。
2012年的Google I/O開發者大會上,Google Now第一次亮相。
2013年谷歌又以超過3000萬美元收購了新聞閱讀應用開發商Wavii。Wavii擅長“自然語言處理”技術,可以通過掃描互聯網發現新聞,并直接給出一句話摘要及鏈接。之后,谷歌又收購了SR Tech Group 的多項語音識別相關的專利,這些技術和專利谷歌也很快應用到市場,比如YouTube已提供標題自動語音轉錄支持,Google Glass使用了語音控制技術,Android也整合了語音識別技術等等,Google Now更是擁有了完整的語音識別引擎。
谷歌可能出于戰略布局方面的考慮,2015年入資了中國的出門問問,這是一款以語音導航為主的公司,最近也發布了智能手表,出門問問也有國內著名聲學器件廠商歌爾聲學的背景。
微軟 Cortana 小冰
微軟語音識別最吸引眼球的就是Cortana和小冰。Cortana是微軟在機器學習和人工智能領域方面的嘗試,Cortana可以記錄用戶的行為和使用習慣,利用云計算、搜索引擎和“非結構化數據”分析,讀取和學習包括手機中的圖片、視頻、電子郵件等數據理解用戶的語義和語境,從而實現人機交互。
微軟小冰是微軟亞洲研究院2014年發布的人工智能機器人,微軟小冰除了智能對話之外,還兼具群提醒、百科、天氣、星座、笑話、交通指南、餐飲點評等實用技能。
除了Cortana和微軟小冰,Skype Translator,可以為英語、西班牙語、漢語、意大利語用戶提供實時翻譯服務。
Amazon的語音技術起步于2011年收購語音識別公司Yap,Yap成立于2006年,主要提供語音轉換文本的服務。2012年Amazon又收購了語音技術公司Evi,繼續加強語音識別在商品搜索方面的應用, Evi也曾經應用過Nuance的語音識別技術。2013年,Amazon繼續收購Ivona Software,Ivona是一家波蘭公司,主要做文本語音轉換,其技術已被應用在Kindle Fire的文本至語音轉換功能、語音命令和Explore by Touch應用之中,Amazon智能音箱Echo也是利用了這項技術。
Facebook在2013年收購了創業型語音識別公司Mobile Technologies,其產品Jibbigo允許用戶在25種語言中進行選擇,使用其中一種語言進行語音片段錄制或文本輸入,然后將翻譯顯示在屏幕上,同時根據選擇的語言大聲朗讀出來。這一技術使得 Jibbigo成為出國旅游的常用工具,很好地代替了常用語手冊。
之后,Facebook繼續收購了語音交互解決方案服務商Wit.ai。Wit.ai的解決方案允許用戶直接通過語音來控制移動應用程序、穿戴設備和機器人,以及幾乎任何智能設備。Facebook的希望將這種技術應用到定向廣告之中,將技術和自己的商業模式緊密結合在一起。
傳統語音識別行業貴族Nuance
除了以上介紹的大家熟知的科技巨頭的語音識別發展情況,傳統語音識別行業貴族Nuance也值得了解。Nuance曾經在語音領域一統江湖,世界上有超過80%的語音識別都用過Nuance識別引擎技術,其語音產品可以支持超過50種語言,在全球擁有超過20億用戶,幾乎壟斷了金融和電信行業。現在, Nuance依舊是全球最大的語音技術公司,掌握著全球最多的語音技術專利。蘋果語音助手Siri、三星語音助手S-Voice、各大航空公司和頂級銀行的自動呼叫中心,剛開始都是采用他們的語音識別引擎技術。
不過由于Nuance有點過于自大,現在的Nuance已經不如當年了。
國外其他語音識別公司
2013年英特爾收購了西班牙的語音識別技術公司Indisys,同年雅虎收購了自然語言處理技術初創公司SkyPhrase。而美國最大的有線電視公司Comcast也開始推出自己的語音識別交互系統。Comcast希望利用語音識別技術讓用戶通過語音就可以更自由控制電視,并完成一些遙控器無法完成的事情。
國內語音識別廠商
科大訊飛
科大訊飛成立于1999年底,依靠中科大的語音處理技術以及國家的大力扶持,很快就走上了正軌。科大訊飛2008年掛牌上市,目前市值接近500億,根據2014年語音產業聯盟的數據調查顯示,科大訊飛占據了超過60%的市場份額,絕對是語音技術的國內龍頭企業。
提到科大訊飛,大家可能想到的都是語音識別,但其實它最大的收益來源是教育,特別是在2013年左右,收購了很多家語音評測公司,包括啟明科技等,對教育市場形成了壟斷,經過一系列的收購后,目前所有省份的口語評測用的都是科大訊飛的引擎,由于其占據了考試的制高點,所有的學校及家長都愿意為其買單。
百度語音
百度語音很早就被確立為戰略方向,2010年與中科院聲學所合作研發語音識別技術,但是市場發展相對緩慢。直到2014年,百度重新梳理了戰略,請來了人工智能領域的泰斗級大師吳恩達,正式組建了語音團隊,專門研究語音相關技術,由于有百度強大的資金支持,到目前為止收獲頗豐,斬獲了近13%的市場份額,其技術實力已經可以和擁有十多年技術與經驗積累的科大訊飛相提并論。
捷通和信利
捷通華聲憑借的是清華技術,成立初期力邀中科院聲學所的呂士楠老先生加入,奠定了語音合成的基礎。中科信利則完全依托于中科院聲學所,其成立初期技術實力極為雄厚,不僅為國內語音識別行業培養了大量人才,而且也在行業領域,特別是軍工領域發揮著至關重要的作用。
中科院聲學所培養的這些人才,對于國內語音識別行業的發展極為重要,姑且稱之為聲學系,但是相對于市場來說,這兩家公司已經落后了科大訊飛一大段距離。中科信利由于還有行業市場背景,目前基本上不再參與市場運作,而捷通華聲最近也因為南大電子“嬌嬌”機器人的造假事件被推上了風口浪尖,著實是一個非常負面的影響。
思必馳
2009年前后,DNN被用于語音識別領域,語音識別率得到大幅提升,識別率突破90%,達到商用標準,這極大的推動了語音識別領域的發展,這幾年內又先后成立許多語音識別相關的創業公司。
思必馳2007年成立,創始人大部分來源于劍橋團隊,其技術有一定的國外基礎,當時公司主要側重于語音評測,也就是教育,但經過多年的發展,雖然占有了一些市場,但在科大訊飛把持著考試制高點的情況下,也很難得到突破。
于是在2014年的時候,思必馳痛下決心將負責教育行業的部門剝離,以9000萬賣給了網龍,自己則把精力收縮專注智能硬件和移動互聯網,最近更是集中精力聚焦車載語音助手,推出了“蘿卜”,可市場反響非常一般。
云知聲
借著2011年蘋果Siri的宣傳勢頭,2012年云知聲成立。云知聲團隊主要來源于盛大研究院,湊巧的是CEO和CTO也是中科大畢業,與科大訊飛可以說是師兄弟。但語音識別技術則更多的源于中科院自動化所,其語音識別技術有一定的獨到之處,有一小段時期內語音識別率甚至超越科大訊飛。因此也受到了資本的熱捧,B輪融資達到3億,主要瞄準智能家居市場。但至今已經成立了3年多,聽到的更多是宣傳,市場發展較為緩慢,B2B市場始終不見起色,B2C市場也很少聽到實際應用,估計目前還處在燒錢階段。
出門問問
出門問問成立于2012年,其CEO曾經在谷歌工作,在拿到紅杉資本和真格基金的天使投資之后,從谷歌辭職創辦了上海羽扇智信息科技有限公司,并立志打造下一代移動語音搜索產品——“出門問問”。
出門問問的成功之處便是蘋果APP的榜單排名,但是筆者不知道有那么多內置地圖的情況下,為啥還要下載這個軟件,顯然有時候比直接查找地圖還要麻煩。出門問問同樣也具有較強的融資能力,2015年拿到了Google的C輪融資,融資額累計已經7500萬美元。出門問問主要瞄準可穿戴市場,最近自己也推出了智能手表等產品,但也是雷聲大,雨點小,沒見得其智能手表的銷量如何。
國內其他的語音識別公司
語音識別的門檻并不高,因此國內各大公司也逐漸加入進來。搜狗開始采用的是云知聲的語音識別引擎,但很快就搭建起自己的語音識別引擎,主要應用于搜狗輸入法,效果也還可以。
騰訊當然不會落后,微信也建立了自己語音識別引擎,用于將語音轉換為文字,但這個做的還是有點差距。
阿里,愛奇藝,360,樂視等等也都在搭建自己的語音識別引擎,但這些大公司更多的是自研自用,基本上技術上泛善可陳,業界也沒有什么影響力。
當然,除了以上介紹的產業界的語音識別公司,學術界Cambridge的HTK工具對學術界研究推動巨大,還有CMU、SRI、MIT、RWTH、ATR等同樣推動語音識別技術的發展。
語音識別技術原理是什么?
對于語音識別技術,相信大家或多或少都已經有了接觸和應用,上面我們也已經介紹了國內外主要的語音識別技術公司的情況。但你仍然可能想知道,語音識別技術的原理是什么?那么接下來就為大家做介紹。
語音識別技術
語音識別技術就是讓機器通過識別和理解過程把語音信號轉變為相應的文本或命令的技術。語音識別的目的就是讓機器賦予人的聽覺特性,聽懂人說什么,并作出相應的動作。目前大多數語音識別技術是基于統計模式的,從語音產生機理來看,語音識別可以分為語音層和語言層兩部分。
語音識別本質上是一種模式識別的過程,未知語音的模式與已知語音的參考模式逐一進行比較,最佳匹配的參考模式被作為識別結果。
當今語音識別技術的主流算法,主要有基于動態時間規整(DTW)算法、基于非參數模型的矢量量化(VQ)方法、基于參數模型的隱馬爾可夫模型(HMM)的方法、基于人工神經網絡(ANN)和支持向量機等語音識別方法。
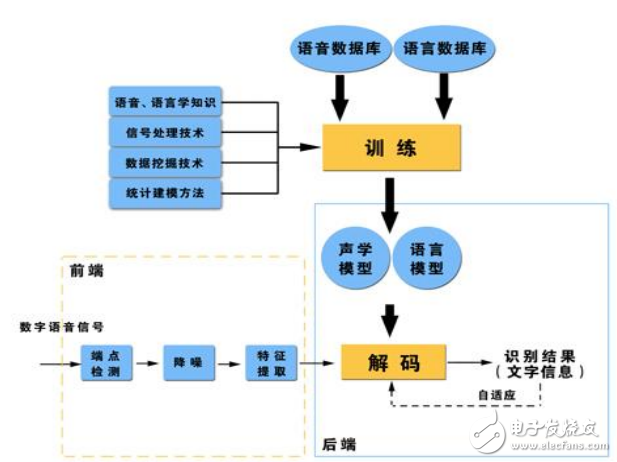
語音識別基本框圖
語音識別分類:
根據對說話人的依賴程度,分為:
(1)特定人語音識別(SD):只能辨認特定使用者的語音,訓練→使用。
(2)非特定人語音識別(SI):可辨認任何人的語音,無須訓練。
根據對說話方式的要求,分為:
(1)孤立詞識別:每次只能識別單個詞匯。
(2)連續語音識別:用者以正常語速說話,即可識別其中的語句。
語音識別系統
語音識別系統的模型通常由聲學模型和語言模型兩部分組成,分別對應于語音到音節概率的計算和音節到字概率的計算。
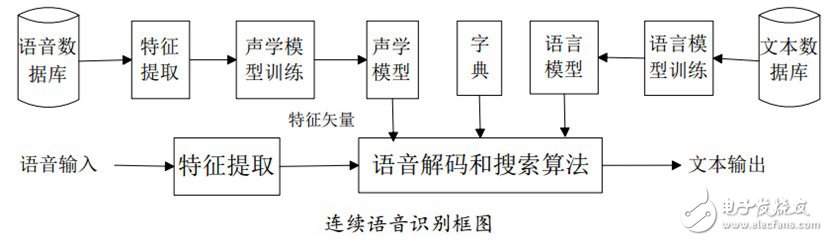
Sphinx是由美國卡內基梅隆大學開發的大詞匯量、非特定人、連續英語語音識別系統。一個連續語音識別系統大致可分為四個部分:特征提取,聲學模型訓練,語言模型訓練和解碼器。
(1)預處理模塊
對輸入的原始語音信號進行處理,濾除掉其中的不重要的信息以及背景噪聲,并進行語音信號的端點檢測(找出語音信號的始末)、語音分幀(近似認為在10-30ms內是語音信號是短時平穩的,將語音信號分割為一段一段進行分析)以及預加重(提升高頻部分)等處理。
(2)特征提取
去除語音信號中對于語音識別無用的冗余信息,保留能夠反映語音本質特征的信息,并用一定的形式表示出來。也就是提取出反映語音信號特征的關鍵特征參數形成特征矢量序列,以便用于后續處理。
目前的較常用的提取特征的方法還是比較多的,不過這些提取方法都是由頻譜衍生出來的。
(3)聲學模型訓練
根據訓練語音庫的特征參數訓練出聲學模型參數。在識別時可以將待識別的語音的特征參數同聲學模型進行匹配,得到識別結果。
目前的主流語音識別系統多采用隱馬爾可夫模型HMM進行聲學模型建模。
(4)語言模型訓練
語言模型是用來計算一個句子出現概率的概率模型。它主要用于決定哪個詞序列的可能性更大,或者在出現了幾個詞的情況下預測下一個即將出現的詞語的內容。換一個說法說,語言模型是用來約束單詞搜索的。它定義了哪些詞能跟在上一個已經識別的詞的后面(匹配是一個順序的處理過程),這樣就可以為匹配過程排除一些不可能的單詞。
語言建模能夠有效的結合漢語語法和語義的知識,描述詞之間的內在關系,從而提高識別率,減少搜索范圍。語言模型分為三個層次:字典知識,語法知識,句法知識。
對訓練文本數據庫進行語法、語義分析,經過基于統計模型訓練得到語言模型。語言建模方法主要有基于規則模型和基于統計模型兩種方法。
(5)語音解碼和搜索算法
解碼器:即指語音技術中的識別過程。針對輸入的語音信號,根據己經訓練好的HMM聲學模型、語言模型及字典建立一個識別網絡,根據搜索算法在該網絡中尋找最佳的一條路徑,這個路徑就是能夠以最大概率輸出該語音信號的詞串,這樣就確定這個語音樣本所包含的文字了。所以解碼操作即指搜索算法:是指在解碼端通過搜索技術尋找最優詞串的方法。
連續語音識別中的搜索,就是尋找一個詞模型序列以描述輸入語音信號,從而得到詞解碼序列。搜索所依據的是對公式中的聲學模型打分和語言模型打分。在實際使用中,往往要依據經驗給語言模型加上一個高權重,并設置一個長詞懲罰分數。當今的主流解碼技術都是基于Viterbi搜索算法的,Sphinx也是。
語音識別技術的難點
說話人的差異
? 不同說話人:發音器官,口音,說話風格
? 同一說話人:不同時間,不同狀態
噪聲影響
? 背景噪聲
? 傳輸信道,麥克風頻響
魯棒性技術
? 區分性訓練
? 特征補償和模型補償
語音識別的具體應用
? 命令詞系統
? 識別語法網絡相對受限,對用戶要求較嚴格
? 菜單導航,語音撥號,車載導航,數字字母識別等等
? 智能交互系統
? 對用戶要求較為寬松,需要識別和其他領域技術的結合
? 呼叫路由,POI語音模糊查詢,關鍵詞檢出
? 大詞匯量連續語音識別系統
? 海量詞條,覆蓋面廣,保證正確率的同時實時性較差
? 音頻轉寫
? 結合互聯網的語音搜索
? 實現語音到文本,語音到語音的搜索









 工商網監
工商網監
評論