 電子發(fā)燒友App
電子發(fā)燒友App


Transformer是一類基于自注意力機制的深度神經(jīng)網(wǎng)絡(luò),最初用于處理自然語言理解任務(wù)。相較于卷積網(wǎng)絡(luò)和循環(huán)網(wǎng)絡(luò)等傳統(tǒng)深度神經(jīng)網(wǎng)絡(luò),Transformer的表示學(xué)習(xí)能力更加強大,并已經(jīng)被應(yīng)用到視覺任務(wù)中。當(dāng)前,基于Transformer的視覺表征學(xué)習(xí)網(wǎng)絡(luò)已經(jīng)在圖像分類、視頻理解等低高級視覺任務(wù)中已經(jīng)取得了優(yōu)異表現(xiàn)。本文將對視覺Transformer基本原理和用于執(zhí)行目標(biāo)檢測任務(wù)的Transformer結(jié)構(gòu)進行簡要介紹,可供研究者參考。
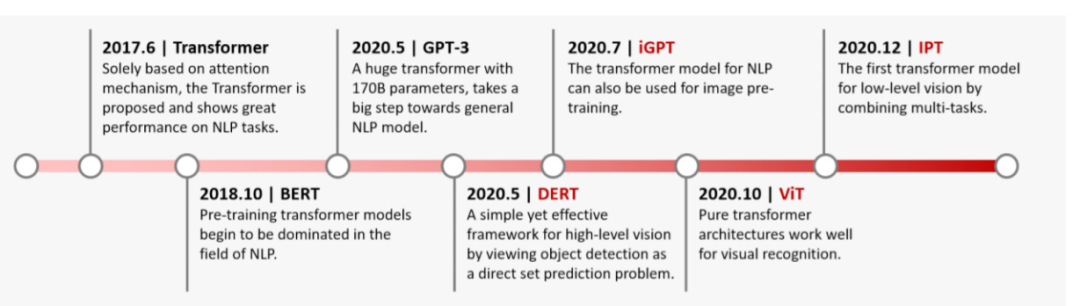
圖1丨Transformer發(fā)展歷程
●?視覺Transformer基本結(jié)構(gòu)
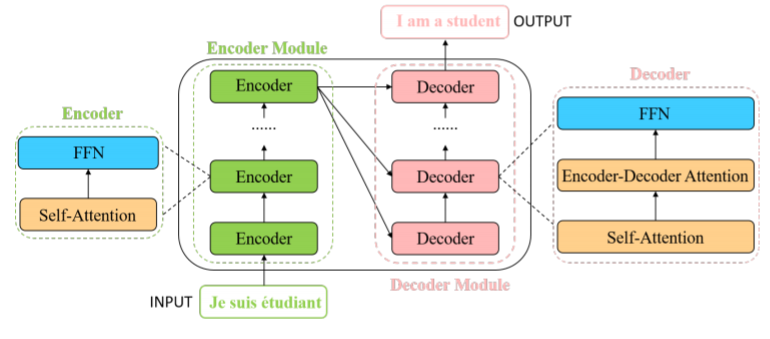
圖2丨視覺Transformer結(jié)構(gòu)
視覺Transformer的一般結(jié)構(gòu)如圖2所示,包括編碼器和解碼器兩部分,其中編碼器每一層包括一個多頭自注意力模塊(self-attention)和一個位置前饋神經(jīng)網(wǎng)絡(luò)(FFN),而解碼器每一層包括三部分:多頭自注意力模塊、編碼解碼自注意力模塊和位置前饋神經(jīng)網(wǎng)絡(luò)。 ?
●?Transformer在目標(biāo)檢測任務(wù)中的應(yīng)用?
Transformer已經(jīng)被廣泛用于處理目標(biāo)檢測問題,按照網(wǎng)絡(luò)結(jié)構(gòu)可以分為基于多尺度融合(neck-based)、基于頭(head-based)和基于框架(framework-based)三大類。 1)?基于多尺度融合
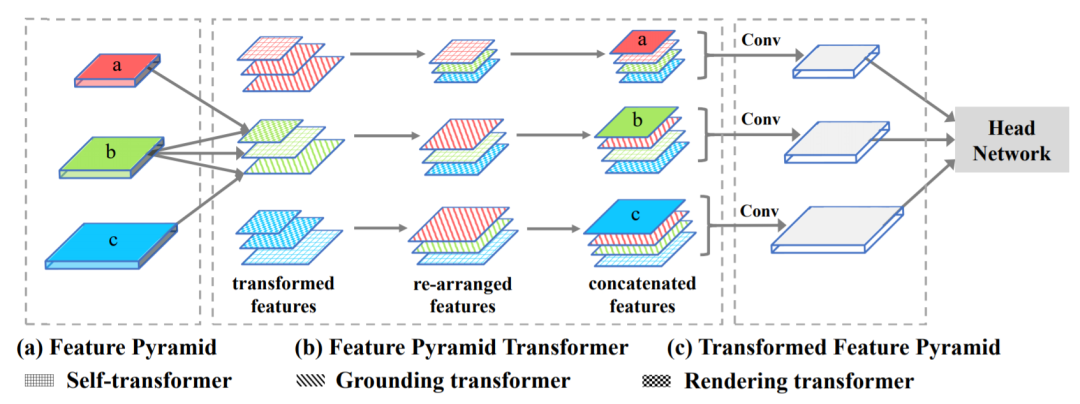
圖3丨FPT網(wǎng)絡(luò)結(jié)構(gòu)
受特征金字塔網(wǎng)絡(luò)等基于卷積網(wǎng)絡(luò)的多尺度特征融合網(wǎng)絡(luò)在目標(biāo)檢測任務(wù)中取得的良好性能啟發(fā),研究者提出了特征金字塔Transformer(FPT)來充分利用跨空間和尺度的特征相互作用,解決卷積網(wǎng)絡(luò)無法學(xué)習(xí)交互跨尺度特征的問題。FPT網(wǎng)絡(luò)結(jié)構(gòu)如圖3所示,由三種不同類型的Transformer構(gòu)成,稱之為Self-Transformer,Grounding-Transformer和Rendering-Transformer,分別用于對特征金字塔的Self-level、top-down和bottom-up路徑的信息進行編碼,利用Transformer中的自注意力模塊來增強特征金字塔的特征融合。 2)?基于頭
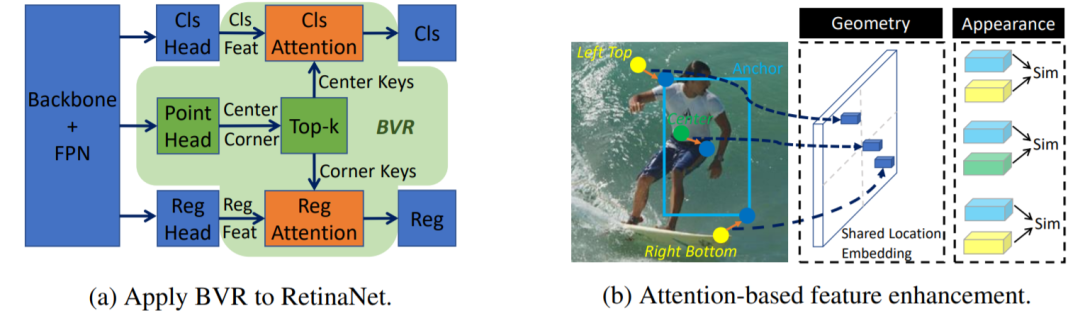
圖4丨橋接視覺表示
對于物體檢測算法而言,預(yù)測頭的設(shè)計至關(guān)重要。傳統(tǒng)檢測方法一般利用邊界框、角點等單個視覺表示來預(yù)測最終結(jié)果。研究者將Transformer結(jié)構(gòu)引入物體檢測問題中,提出了橋接視覺表示(Bridging Visual Representations,BVR),通過多頭關(guān)注模塊將不同的異構(gòu)表示組合成一個單一的表示。具體來說,將主表示作為query輸入,將輔助表示作為key輸入。通過類似于Transformer中的注意模塊,可以獲得用于主表示的增強功能,該功能將來自輔助表示的信息橋接起來并有利于最終檢測性能。 3)?基于框架
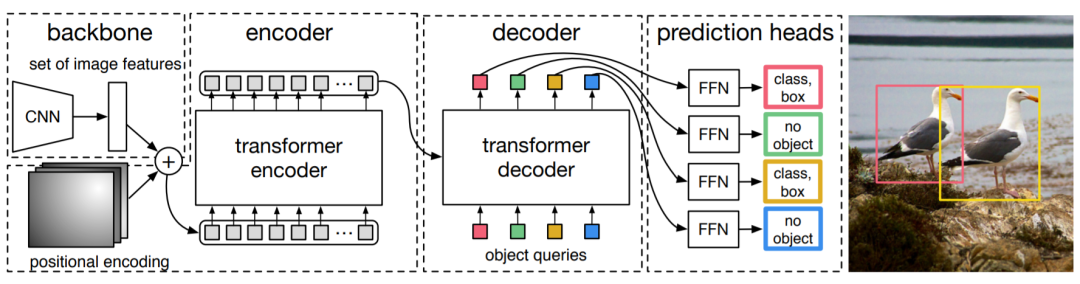
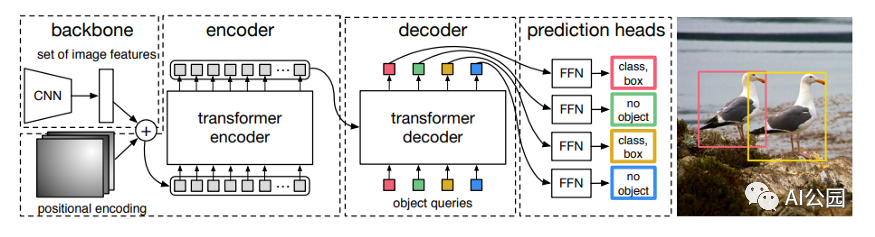
圖5丨DETR網(wǎng)絡(luò)結(jié)構(gòu)
區(qū)別于前兩類方法使用Transformer結(jié)構(gòu)增強傳統(tǒng)檢測算法中特定模塊的性能,DETR網(wǎng)絡(luò)將目標(biāo)檢測任務(wù)視為集合預(yù)測問題,采用端到端的Transformer結(jié)構(gòu)構(gòu)建目標(biāo)檢測器,如圖5所示。DETR從CNN主干開始以從輸入圖像中提取特征。為了用位置信息補充圖像特征,將固定的位置編碼添加到平坦的十個特征中,然后再輸入編碼解碼器轉(zhuǎn)換器。與原始Transformer順序生成預(yù)測的原始Transformer不同,DETR同時解碼多個對象。DETR作為針對目標(biāo)檢測任務(wù)提出的全新Transformer結(jié)構(gòu)設(shè)計,為后續(xù)研究提供了重要啟發(fā),但存在訓(xùn)練時間長、難以準(zhǔn)確檢測小目標(biāo)等問題。
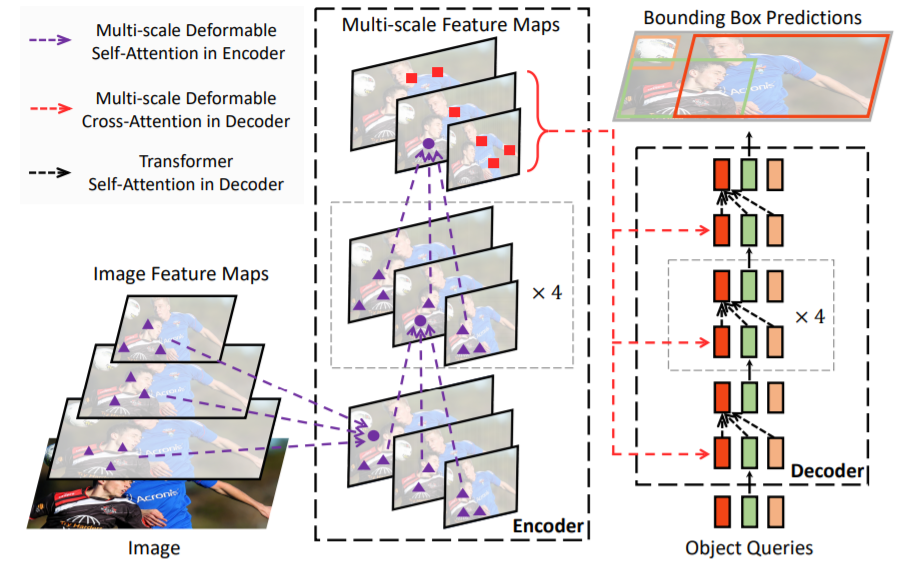
圖6丨Deformable DETR網(wǎng)絡(luò)
針對DETR存在的問題,Deformable DETR使用圖6所示的可變形注意模塊來關(guān)注參考點周圍的一小組關(guān)鍵位置,顯著降低了原多頭注意力的計算復(fù)雜度,也有利于快速收斂。可變形注意模塊可輕松完成多尺度特征融合操作,使得Deformable DETR相較于原始DETR訓(xùn)練成本降低10倍,推理速度提升1.6倍。
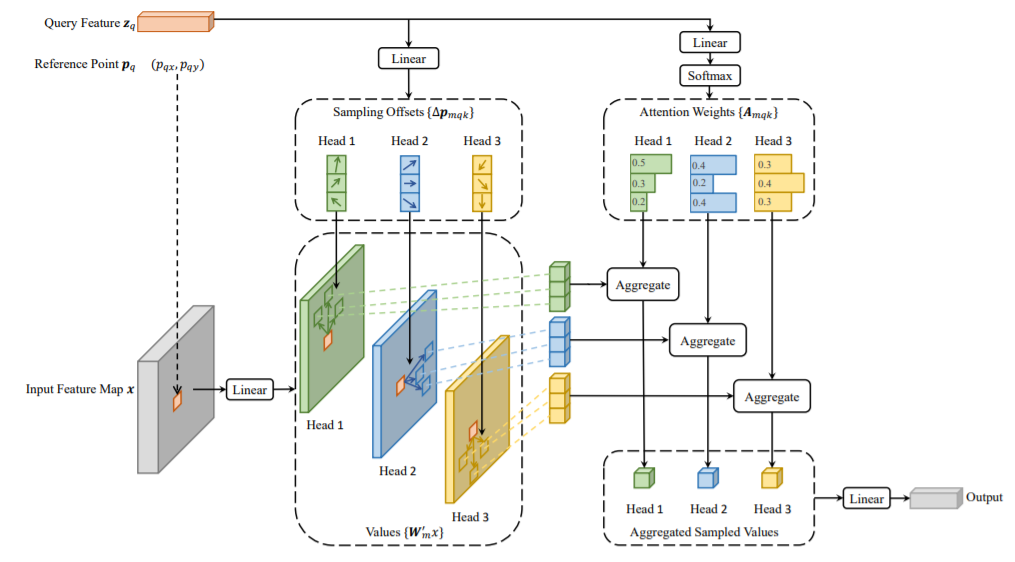
圖7丨可變形注意模塊
● 總結(jié)
與卷積網(wǎng)絡(luò)相比,Transformer在抽取時空表征關(guān)系上具有巨大優(yōu)勢,已經(jīng)成為計算機視覺研究領(lǐng)域的熱門話題,并已經(jīng)在多種視覺任務(wù)中取得優(yōu)良表現(xiàn)。但是,當(dāng)前視覺Transformer研究仍主要關(guān)注單一任務(wù),而在自然語言處理領(lǐng)域Transformer已經(jīng)表現(xiàn)出在統(tǒng)一模型里執(zhí)行多個任務(wù)的能力,多任務(wù)視覺Transformer模型有待進一步研究。此外,當(dāng)前模型普遍復(fù)雜,模型訓(xùn)練和存儲成本較高,開發(fā)適合部署在資源受限設(shè)備上的視覺Transformer模型將是未來研究重點之一。
審核編輯:黃飛
?












 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論