 電子發燒友App
電子發燒友App


在本文中,我將討論專為機器學習/人工智能應用開發的硬件,以及該領域的機遇。并簡要介紹英偉達是如何在機器學習硬件領域實現近乎壟斷的地位,以及為什么幾乎沒有人能成功挑戰它。
在過去的10年中,專用于機器學習應用的硬件研究迅猛發展,硬件與機器學習棧的每個部分都有關系。這種硬件可加速訓練和推理,減少延遲時間,降低功耗,并降低這些設備的零售成本。當前通用的機器學習硬件解決方案是英偉達GPU,這使得英偉達在市場上占據主導地位,并使其估值超越英特爾。
隨著前景廣闊的研究不斷涌現,英偉達繼續通過出售GPU和它的專有CUDA工具箱來主導這個領域。不過,我認為有四個因素將挑戰英偉達的統治地位,并且最快今年,也肯定會在2~3年內改變機器學習硬件的格局。
這個領域的學術研究正在成為主流。摩爾定律已死。隨著它的消亡,“技術和市場力量正在將計算推向相反的方向,使得計算機處理器不再是通用的,而是更加專業化的。”(出處)投資人和創始人都認識到,人工智能不僅能開辟新的領域,而且能增加他們的預算。人工智能產生的碳排放量過高,而且越來越高。我們需要讓計算更加節能。
背景
下面是典型的機器學習管道的樣子:
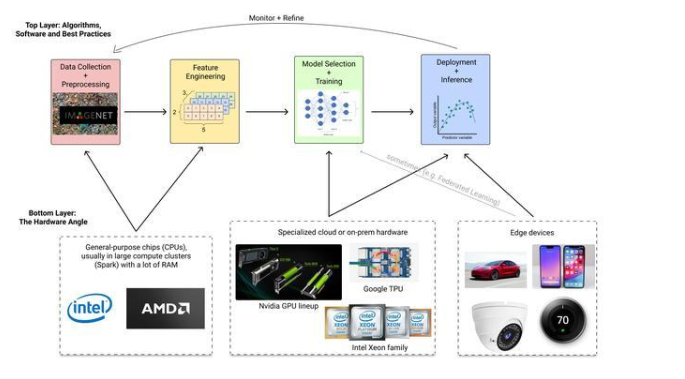
對于大多數數據科學工作流而言,在訓練和部署大型模型之前,通用芯片,如CPU,就已經足夠了。GPU在“深度學習”(涉及視覺和自然語言處理等任務的神經網絡體系結構)中幾乎總是必不可少的。為深度學習提供GPU工作站的LambdaLabs公司估計,包括英偉達的頂級GPU集群在內,訓練GPT-3的費用大約為460萬美元。
使用GPU的主要優點是,與傳統CPU相比,GPU可以并行地執行計算,數據吞吐量更高。計算過程中,機器學習的核心計算部分是矩陣乘法,并行運行時能大大提高運算速度。專有的英偉達CUDA提供了API和工具,以便開發者可以利用這種并行化。像TensorFlow和PyTorch這樣的流行庫將其抽象出來,其中一行代碼會自動檢測GPU,然后利用CUDA后端。若要設計一種新的算法或庫,需要利用并行計算的優勢,CUDA提供的工具會使這一工作更加簡單。
上世紀90年代初,英偉達作為一家視頻游戲公司起家,希望能提供能快速繪制3D圖像的圖像芯片。它在這一業務上取得了成功,在與另一家顯卡制造商AMD的不斷交鋒中,始終如一地制造出一些最強大的GPU。巧合的是,同樣的圖形硬件竟然成了深度學習騰飛不可或缺的因素。CUDA讓英偉達比其他GPU更有優勢。
2006年,英偉達發布了第一個CUDA工具包,它提供了一個API,可以讓使用GPU變得非常簡單。3年后,2009年,斯坦福大學人工智能教授吳恩達及其合作者發表了一篇題為《使用圖形處理器的大規模無監督式深度學習》(Large-scaleDeepUnsupervisedLearningusingGraphicsProcessors)的論文,指出如果GPU用于訓練,大規模的深度學習就有可能實現。
一年后,吳恩達和斯坦福大學的另一位教授,GoogleX的共同創始人,SebastianThrun,向拉里·佩奇提出了在谷歌成立深度學習研究團隊的想法,該團隊后來成為GoogleBrain。伴隨著GoogleBrain的崛起和“Imagenet時刻”的到來,英偉達的GPU已經成為人工智能/機器學習行業事實上的計算標準。如需更多信息,請參閱這篇文章《新的英特爾:英偉達如何從驅動視頻游戲到革新人工智能》(TheNewIntel:HowNvidiaWentFromPoweringVideoGamesToRevolutionizingArtificialIntelligence)。
概述:現狀
英偉達憑借其GPU在深度學習硬件領域占據主導地位,這在很大程度上要歸功于CUDA。據福布斯報道,“2019年5月,前四大云計算供應商在97.4%的基礎設施即服務(IaaS)計算實例類型中部署了英偉達GPU,并配備了專用加速器”。面對競爭,它也沒有坐以待斃。
谷歌早在2015年就開發了專門為神經網絡開發的人工智能加速器芯片TPU。在其作為特定領域加速器的狹義用例中,TPU比GPU更快,也更便宜,但在谷歌的GCP生態系統中,TPU被隔離起來,僅有TensorFlow和PyTorch支持(其他庫需要自己編寫TPU編譯器)。
AWS正在對自己的芯片下賭注,尤其是機器學習。到目前為止,AWSInferentia芯片似乎是最成功的。這在很大程度上取決于開發者從CUDA切換到亞馬遜Inferentia和其他芯片的工具包的難易程度。
2019年12月,英特爾以20億美元的價格收購了HabanaLabs,這是一家以色列公司,為訓練和推理工作負載制造芯片和硬件加速器。英特爾的投資似乎得到了回報,上個月,AWS宣布將提供運行Habana芯片的新EC2實例,“與當前基于GPU的EC2實例相比,為機器學習工作負載提供高達40%的價格性能”。英特爾還推出了新的XeonCPU系列,它認為可與英偉達的GPU競爭。
Xilinx是一家發明FPGA的上市公司,最近又涉足人工智能加速器芯片領域,2020年10月被AMD收購。
對人工智能計算能力的需求正在加速。
變化與機遇
正如我在上面提到的,我的設想是,到2021年及以后,英偉達的主導地位將會受到越來越多的挑戰和侵蝕。造成這種情況的原因有四個:
1.學術研究變成真正的產品
學術界和工業界研究人員創立的一些初創公司已經開始研究機器學習專用硬件,而且還有更多的開發空間。在這個領域發表的論文并不只是提出理論上的保證,它還展示了真正的硬件原型,這些原型實現了比商業可用選項更好的指標。(實例1、實例2和實例3)
芯片和硬件加速器的種類很多,每一種都有其蓬勃發展的研究社區。簡單地列舉一些:
專用集成電路(ASIC)。谷歌TPU和AWSInferentia都是ASIC的例子。ASIC產品的研發和生產成本可能高達5000萬美元,但是復制產品的邊際成本通常很低。ASIC可以被設計成低功耗的,而且不會對性能有太大的影響。
現場可編程邏輯門陣列(FPGA)。FPGA對于高頻交易者來說已稀松平常,但在機器學習方面的例子包括微軟的Brainwave和英特爾的Arria。單個FPGA的生產成本較低,但多個FPGA的生產邊際成本要高于ASIC。
神經形態計算。該領域試圖對人腦的生物結構進行建模,并將其轉換成硬件。盡管神經形態學的思想可以追溯到20世紀80年代,但該領域仍處于起步階段。在《自然》上有一篇很好的綜述性論文。
更多內容請參閱此項調查報告《機器學習加速芯片綜述》(SurveyofMachineLearningAccelerators),并關注ISCAS。
使用上述研究結果的一些有前途的初創公司:
Blaize于2019年宣稱已經開發出一種完全可編程的低功耗處理器,可實現10倍的低延遲,并且“系統效率最高可提高60%”。
SambaNovaSystems是由斯坦福大學教授和甲骨文前高管創立的初創公司,由谷歌風投和英特爾資本出資組建。它剛剛宣布了一項新產品,該產品是一個“完整、集成的軟件和硬件系統平臺,可以對從算法到芯片的數據流進行優化”。
Graphcore是一家英國初創公司,由紅杉、微軟、寶馬和DeepMinds創始人領投。
2.摩爾定律已死,但無論如何,專用硬件都是未來趨勢
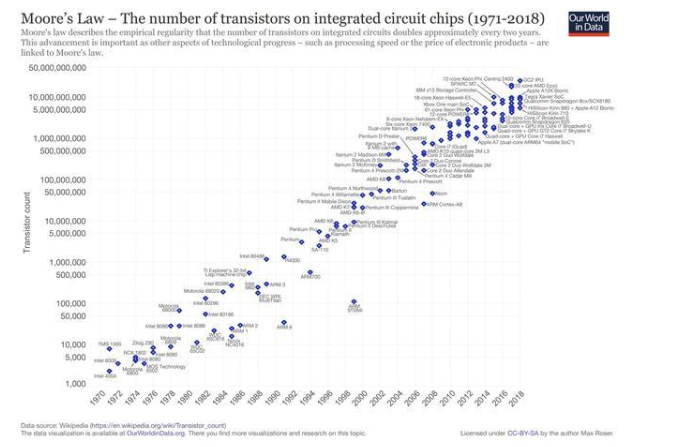
摩爾定律預測,集成電路上的晶體管數量每兩年就會增加一倍。自20世紀70年代以來,這在經驗上一直是正確的,并且是我們從那時起所看到的技術進步的代名詞:個人計算革命、傳感器和攝像頭的改進、移動設備的興起,以及為人工智能提供充足資源的崛起,凡是你能想到的一切。唯一的問題是,摩爾定律即將結束,如果它還沒有結束的話。“縮小芯片的難度越來越大,這已經不是什么秘密了,而且這樣做的好處也今非昔比了。去年,英偉達的創始人黃仁勛直言不諱地認為,‘摩爾定律已不再可能了’。”《經濟學人》(TheEconomist)寫道。
麻省理工學院經濟學家NeilThompson在《麻省理工科技評論》(MITTechnologyReview)上解釋說:“軟件和專業架構方面的進步現在將開始有選擇地針對特定的問題和商業機會,對那些有充足資金和資源的人有利,而不是像摩爾定律那樣‘水漲船高’,通過提供速度更快、成本更低的芯片來普及。”一些人,包括Thomspon在內的,都認為,“這是一個消極的發展,因為計算硬件將開始分裂為“‘快車道’應用和‘慢車道’應用程序,前者使用功能強大的定制芯片,而后者則被卡在使用通用芯片上,而且其進展緩慢。”
對于這個問題,分布式計算常常是一種解決方案:讓我們使用功能更少、成本更低的資源,但要使用大量的資源。但是,就連這種方案也越來越昂貴(更別提分布式梯度下降算法的復雜性了)。
那么,接下來會發生什么呢?2018年,CMU的研究人員在《自然》上發表了一篇論文,題為《摩爾定律末期的科學研究政策》(ScienceandresearchpolicyattheendofMoore’slaw),該論文指出,私營部門將重點放在短期盈利上,這使得摩爾定律很難找到通用的繼承者。他們呼吁公私合作,共同創造計算硬件的未來。
雖然我并不反對公私合作(給予他們更多的權利),但我認為未來的計算硬件將是專用芯片的集合,當它們協同工作時,它們比現在的CPU更能勝任通用任務。我相信蘋果向自己的芯片過渡是朝著這個方向邁出的一步,這證明了軟硬件集成系統將優于傳統芯片。特斯拉也在自動駕駛中采用了自己的硬件。我們需要的是大量的新玩家涌入硬件生態系統,這樣專業芯片的好處就可以實現大眾化,并分布在昂貴的筆記本電腦、云服務器和汽車之外。(我敢說……是時候打造了嗎?)
3.創始人和投資者擔心成本上漲
AndreessenHorowitz的MartinCasado和MattBornstein在去年年初發表了一篇題為《人工智能的新業務(及其與傳統軟件的區別》(TheNewBusinessofAI(andHowIt’sDifferentFromTraditionalSoftware))的文章,他們認為人工智能的業務與傳統軟件是不同的。說到底,一切都與利潤有關。“云計算基礎設施對人工智能公司來說是一個巨大的成本,有時甚至是隱性成本”。正如我所提到的那樣,訓練人工智能模型可能需要花費數千美元(如果你是OpenAI,你就得花數百萬美元),但成本并不止于這些。人工智能系統必須得到持續監控和改進。如果你的模型是“離線”訓練的,那么它很容易出現概念漂移,即現實世界中的數據分布隨著時間的推移與你訓練的數據發生變化。這種情況可能是自然發生的,也可能是對抗性的,比如當用戶試圖欺騙信用風險算法時。出現這種情況時,就必須對模型進行再訓練。
對于降低概念漂移和創建與現有模型具有相同性能保證的更小的模型有一些積極的研究,但這是另一篇文章的主題。同時,該行業也正在推進更大的模型和更大的計算支出。更便宜、更專業的人工智能芯片無疑會降低這些成本。
4.訓練大型模型有助于氣候變化
由馬薩諸塞大學阿默斯特分校進行的一項研究發現,訓練一個現成的自然語言處理模型所產生的碳排放量相當于從舊金山飛往紐約的一次航班。在三大云計算供應商中,只有谷歌的數據中心超過50%的能源來自可再生能源。
但我認為,我不必列出我們為什么要減少人工智能的碳排放。我想說的是,現有的芯片耗電量過大,而且研究表明,其他類型的硬件加速器,如FPGA和超低能耗芯片(如谷歌TPUEdge),對于機器學習和其他任務來說,可以更加節能。
即使是地理也會影響到人工智能的碳排放。斯坦福大學的研究人員估計,“在主要依賴頁巖油的愛沙尼亞舉行一次會議,其產生的碳排放量是在魁北克舉行的會議的30倍,而魁北克主要依靠水力發電。”
已露端倪
我已經提到了人工智能的硬件,但是人工智能的硬件怎么樣?谷歌最近申請了一項專利,該專利是關于一種利用強化學習來確定跨多個硬件設備的機器學習模型操作的位置的方法。這項專利背后的研究人員之一是AzaleaMirhoseini,她在GoogleBrain負責機器學習硬件/系統的登月計劃。
責任編輯人:CC









 工商網監
工商網監
評論