 電子發燒友App
電子發燒友App


今天給大家推薦今年FCCM2021上的一篇文章,介紹了一種可以在線Xilinx FPGA內部RAM內容的工作,重點是論文相關的工作還是開源的。
摘要:XBERT是一個API和設計工具集,用于使用設備的配置路徑零成本訪問Xilinx體系結構上的片上SRAM塊。XBERT API是高級別的,允許開發人員根據應用程序源代碼中的邏輯內存指定類似DMA的內存內容數據傳輸,因此基本上適用于任何針對Xilinx設備的設計。應用程序開發人員可以廣泛地訪問XBERT,它隱藏了物理映射和比特流編碼的底層細節。XBERT是高效的,消耗的可重構資源為零,對Fmax沒有影響。XBERT在Xilinx UltraScale+MPSoC Zynq上實現了每秒3–14兆字節(MB/s)的帶寬,并在不到0.5毫秒的時間內完成了36Kb塊RAM中內存的回讀和轉換。
1. 簡介
今天的FPGA結構包括大量的分布式、嵌入式RAM塊。雖然這些嵌入式RAMs最常見的用途是在FPGA結構上提供和存儲計算過程中使用的數據,但從結構外部加載數據或輸入或檢索存儲為計算輸出的數據是必要的。
我們可以使用FPGA結構資源和專用結構輸入/輸出通道(例如AXI通道)來將數據移入和移出這些嵌入式存儲器,但這會消耗FPGA結構資源以及嵌入式RAM原語上有限的讀/寫端口。而且,這種額外的邏輯可能會對滿足應用程序計時要求帶來挑戰[1]。
這些嵌入式RAMs的內容也可以通過現有的專用片上網絡(比特流重新配置路徑)訪問。因此,應該可以使用比特流重新配置路徑來在不消耗任何FPGA結構資源的情況下將數據移入和移出這些嵌入式RAM塊。此外,在具有嵌入式處理器的SoC FPGAs上,處理器可以作為系統計算的一部分來管理重構。
然而,將原始設計源中的邏輯內存映射到FPGA結構上的物理內存是一項具有挑戰性的任務。一旦實現工具將一個較大的邏輯內存映射到多個較小的內存上,那么識別哪個物理BRAM原語保存特定的邏輯數據對于應用程序編程人員來說是不容易發現的,并且每次更改設計源并將其重新映射到FPGA時都可能發生變化。此外,用于比特流編程的數據格式與存儲數據的邏輯格式不同邏輯存儲器的位在BRAM初始化字符串中沒有整齊地按升序排列,并且這些初始化字符串中的位隨后分散在多個配置幀中。
為了滿足這些需求,我們創建了Xilinx Bitstream Embedded RAM Transmission(XBERT)API,以提供一個高級接口來讀取和寫入邏輯內存的內容,正如應用程序開發人員在源代碼級(如RTL、HLS、IP塊)設計中看到的那樣[1]。
透析(Transfusion)操作是讀寫操作的結合,它提取舊的BRAM內容并提供新的BRAM內容。重要的是,這些合并的輸入操作可以比使用單獨的讀寫操作更有效。
我們的自動工具流提取有關邏輯內存如何映射到物理嵌入式RAMs的信息,以允許XBERT API對這些內存進行操作。我們的API能夠在幾分之一毫秒內讀取結果數據并將其轉換為邏輯內存格式,從而提供以MB/s為單位的有效數據傳輸速率。這不如專用高速鏈路(例如,5 GB/s的AXI通道)快,但對于不經常訪問的內存(例如,在啟動時使用唯一數據編程或在程序完成時恢復數據)或中等帶寬(例如,周期性參數調整)足夠,具體可見節II和III-F。值得注意的是,這是在不減少Fmax或FPGA資源消耗的情況下實現的。
我們的貢獻包括:
一個API,用于提供對存儲在FPGA結構的嵌入式RAM中的內存的邏輯訪問(第五節)
UltraScale+MPSoC Zynq的XBERT API的開源實現,包括提取邏輯?單個內存位的物理映射和運行時支持讀取和寫入正在運行的FPGA內存內容(在[2]處在線)
邏輯到物理位映射的定制壓縮技術,將轉換表大小從兆字節減少到千字節(第七節)
基于表格的加速,可減少單個BRAM轉換時間,與DMA傳輸時間(第八節)
API實現性能的表征(第九節)
2. 用場景
XBERT提供的一般功能有許多用例。編程BRAM配置的覆蓋架構是不經常修改嵌入式RAM內容的一個明顯需求,包括更新嵌入式軟處理器中的程序內存內容,如RISC-V處理器核[3]、[4]、自定義VLIW[5]、自定義的VLIW[5]、[6]和向量[7]、[8]處理器。這種需要加載的指令也適用于更專業的覆蓋結構的加載配置,如專用的FSM評估器[9]、[10]和神經網絡[11]或模擬器[12]。
另一個用例是FPGA構建塊的高速單元測試,在這里需要以全速率向被測模塊提供數據并捕獲結果。這可以用一個存儲器將數據源輸入被測模塊,用另一個存儲器記錄結果。類似地,在使用內部邏輯分析器(ILA)或跟蹤緩沖區[13]、[14]進行實時調試以在操作期間捕獲數據時,我們在測試后卸載這些數據的速度通常并不重要。
最后,在極端情況下,XBERT功能可以提供一種廉價的方式來支持當前FPGA上的高級抽象,如CoRAM[15]。CoRAM提議增加專用的基礎設施來管理嵌入式RAMs和中央內存之間的數據移動,并演示了在FPGA上構建覆蓋網絡的原型。使用XBERT,可以使用現有的重配置路徑硬件支持提供相同的功能,而無需增加覆蓋邏輯。
3. XBERT:概述、挑戰和解決方案
本節介紹XBERT,包括XBERT這樣的系統面臨的挑戰和操作要求,以及解決這些問題的方法和由此帶來的好處。
》3.1 基本單BRAM操作
首先,考慮一下將映射到單個36Kb BRAM的簡單邏輯內存的內容進行更改的簡單用例。如果邏輯內存恰好是XPM實例化的內存,那么在主機上運行的Xilinx的UpdateMem程序可以更改完整比特流中的BRAM。運行Update Mem需要4秒來更改比特流以反映新的BRAM內容,而將完整的比特流加載到XCU3EG需要9毫秒。這既慢又需要使用單獨的主機。
使用XBERT中最簡單的write API(bert_write),我們可以在Zynq的嵌入式APU內核上運行代碼時執行更新,并在1.04毫秒(快3900倍)內編寫BRAM。這包括0.71 ms用于轉換位(將邏輯存儲器位描述轉換為部分比特流)和0.25 ms用于通過Zynq PCAP將部分比特流寫入設備;寫入速度達到3.9MB/s帶寬。重要的是,這個XBERT寫操作適用于任何邏輯內存,而不僅僅是那些用XPM實例化的內存。
》3.2 基于表的轉換、壓縮和加速
UpdateMem運行時使用完整的Xilinx設備數據庫(用于部件)和完整的設計檢查點數據集(用于設計),XBERT將此信息替換為一個最小的轉換表,該表描述每個邏輯內存位映射到比特流的位置。XBERT中的原始轉換表最初需要238KB,但是使用壓縮可以將其減少到2.3KB(第七節)。
上述1.04 ms XBERT時間的主要組成部分是翻譯(0.71 ms),主要包括從邏輯存儲器圖像計算各個位的比特流位置。當我們向XBERT(第八節)添加一個加速的、基于表的多位翻譯功能時,我們可以將其減少到0.28毫秒,因此整個寫操作在0.62毫秒內完成,吞吐量為6.59 MB/s—大約是未加速情況下的兩倍。
》3.3 Transfusion-組合操作以提高性能
談到單個BRAM內存的最小DMA傳輸時間,我們注意到它很大(0.25毫秒),部分原因是寫入發生在幀中,需要為UltraScale+體系結構中共享一幀的所有12個內存寫入數據(圖3)。如果我們需要在一個幀中寫入多個BRAM,或者因為一個邏輯內存使用多個BRAM,或者因為我們需要寫入多個恰好共享一個物理幀的邏輯內存,那么我們可以減少每個BRAM的DMA傳輸時間。在極端情況下,我們將每BRAM DMA傳輸成本降低了12倍,約為0.021 ms,因此每BRAM總寫入成本約為0.32 ms(或11.75 MB/s的吞吐量,約為單次加速吞吐量的兩倍)。因此,有一個scatter-gather接口是非常有效的,它允許我們指定要作為單個操作寫入的完整邏輯內存集,這樣API就可以最小化所需的幀寫入次數。我們的transfuse API接口提供了此功能(第五節)。
雖然有寫使能允許我們一次在一個幀中寫入一個36Kb的BRAM,但是沒有寫使能控制在一個36Kb的BRAM中獨立地寫入兩個18Kb的內存。要單獨寫入一個18Kb內存,我們可能需要先讀取整個幀,以便在塊中保留伙伴18Kb內存的值。XBERT transfuse API可以將此回讀與同一物理幀(秒)中其他邏輯內存的讀取結合起來(第五節)。
》3.4 處理較大內存-邏輯到物理內存映射
為了簡單起見,上面的示例使用了只映射到單個BRAM的邏輯內存。在實踐中,邏輯記憶常常映射到多個物理內存。當這種情況發生時,有很多選擇如何將位打包到內存中。例如,在一個32×10000內存,我們已經看到Vivado將內存的底部18b([17:0])映射為5個18×2048RAMB36s,下一個9b([26:18])到三個9×4096RAMB36s,下一個4b([30:27])到兩個4×8192 RAMB36s,最后一位([31])為1×16384RAM36s;這種非均勻映射只使用11個RAMB36,而在其他設計中,我們看到Vivado將一個大小類似的內存映射到一組16個RAMB36內存,每個內存寬2位,深16K個字。
最后,對于小于單個BRAM的內存,Vivado可能會將高階地址位綁定到0以外的值,這意味著內存的邏輯0位置不會從正常預期的位置(物理BRAM的幀集的第一幀)開始。
為了解決這些復雜而繁瑣的物理映射問題,XBERT工具流自動從Vivado Design CheckPoint(DCP)文件或項目中提取這些映射細節,作為其邏輯到物理內存映射功能的一部分。因此,應用程序開發人員不需要處理這些問題,他們能夠專門處理邏輯內存內容,XBERT對他們隱藏了許多映射細節(第五節)。
》3.5 XBERT設計流程摘要
圖1示出了XBERT的主機側準備工具流程。從頂部開始,對用戶的設計(以設計檢查點的形式最少地表示)進行處理,以提取原始設計源中包含的邏輯內存的信息,從而生成一個MDD文件(第4-D節)。然后將其與從Xilinx生成的.ll文件中提取的比特流信息結合起來,為設計創建邏輯到物理內存映射信息的完整表示(mydesign_uncompressed.{c,h})。然后對其進行壓縮和可選的加速,以生成一個mydesign.c文件,其中包含作為c數據結構的該信息的壓縮版本。
在圖的底部,最終的XBERT應用程序由三組源代碼組成:(1)XBERT運行時源代碼(bert.c),(2)mydesign.c文件,以及(3)用戶的應用程序代碼(application.c)。
這與XBERT的擴展xilfpga庫(第六節) 進入最終可執行的應用程序。
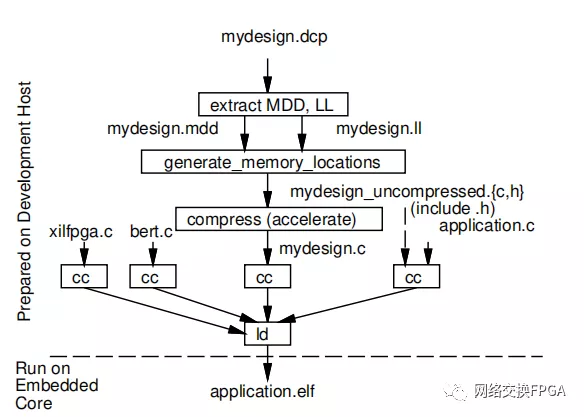
圖1:XBERT工具流程
》3.6 一個充分激勵的例子
考慮開發一個包含四個獨立存儲器的哈夫曼編碼加速器。這個哈夫曼編碼器接收字節流,并通過將每個字節映射到一個可變長度的代碼來壓縮它。而且,為了獲得好的壓縮效果,哈夫曼碼應該調整到被編碼的數據。
我們將編碼器設計為使用編碼表(內存#1)進行任何編碼,并且可以在更改編碼時使用XBERT更新其內容。HDL源代碼中的編碼表是只讀的,但是我們可以使用bert_write來加載它的內容。加載表需要1.1毫秒。如果沒有XBERT,我們將需要使用AXI端口來執行加載,這樣會更快,但會在設計中添加LUT和寄存器(表1)。
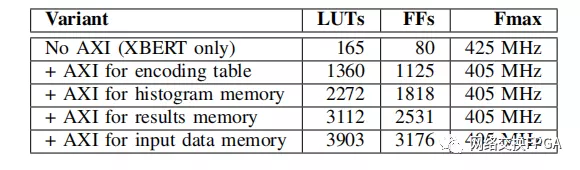
表1:在HUFFMAN示例中添加AXI訪問對內存的影響
當我們第一次設計編碼器時,我們通常希望在將數據源和數據使用者添加到設計中之前測試它的功能和速度。我們可以通過添加一個內存來保存輸入數據(內存2)和一個內存來存儲輸出數據(內存3)。使用XBERT我們不需要其他東西。我們可以使用bert_write將編碼器要壓縮的新數據加載到輸入存儲器中,并使用bert_read恢復壓縮的輸出。
我們還添加了一個直方圖內存,使用256個元素的內存(內存4)捕獲輸入數據的特征。使用bert_read,我們可以在0.45毫秒內讀回這個內存的內容。如果我們每個周期壓縮一個字節,這個直方圖需要在每個周期上執行讀寫操作,這意味著它的兩個端口都被使用。對于提供回讀的非XBERT設計,它需要共享一個端口或復制內存以有效地提供另一個讀端口。對于XBERT,兩者都不是必需的。
使用XBERT我們可以讀取或寫入設計中的四個存儲器中的任何一個。我們可以讀取直方圖內存內容,根據輸入數據流計算新的編碼表,然后將新的編碼表寫回到設計中,所有這些都在1.2ms內完成。
選項卡。我展示了在設計中添加AXI接口的影響(面積,Fmax)。我們在AXI子系統和Huffman解碼器之間使用MMCM,這樣后者就可以以最大時鐘速率運行,而不受最大AXI時鐘速率333MHz的限制。由于這個Huffman示例很小,因此提供對BRAMs的訪問的Fmax影響很小。在更大、高度擁擠的設計中,[1]聲稱消除AXI-BRAM訪問可以實現高達63%的Fmax改進(第4-C節)。
4. 相關工作
》4.1 物理BRAM操作應用程序和工具
許多工具都利用了這樣的情況,即它們可以提供有用的功能來處理原始BRAMs,而不需要映射或轉換回邏輯級別。早在2000年,Xilinx就為嵌入式RAM的部分重新配置回讀和重新加載提供了實驗性的低級別支持[16],[17],主要用于內存回讀和清理[18]。最近,ReconOS使用比特流讀寫進行多任務處理[19](通過比特流加載和卸載BRAM內容)。Metawire使用比特流將數據從BRAM移動到BRAM,以提供片上網絡(NoC)功能;由于它們控制著BRAM映射并從一個BRAM轉移到另一個BRAM,因此它們避免了從物理映射到邏輯映射的轉換[20]。
類似地,有幾部著作將直接BRAM寫入特定的應用程序,包括[21]-[23]。
》4.2 物理比特流API
最近的工作希望為物理層的比特流操作提供一個API。BITMAN pro提供了一個通用的物理層訪問機制,可以訪問BRAM內容通過change_BRAM_content(X,Y,new_config)API[24]。與上述工具一樣,它需要一些更高級別的接口或手動開發操作干預來確定哪些BRAM位置需要更改,并格式化配置數據,包括將邏輯位洗牌到它們在物理配置映射中的位置。
類似地,最近在[25]中的工作提倡使用比特流回讀和編輯來讀寫BRAM內容的方法,并演示了如何在BRAM之間復制數據。但是,它不涉及識別哪些物理內存用于特定的邏輯內存。它也沒有提供完整的描述或高級工具,允許開發人員將其HLS或RTL邏輯內存內容映射到比特流中,或者提取比特流內容并重建HLS或RTL內存的狀態。
》4.3 專用邏輯內存操作
Maxeler探索使用比特流路徑來加載和讀取他們的“映射內存”,而不是單獨的低速總線[1]。他們表明,去掉低速總線及其對結構資源的相關需求,可以將他們設計的性能提高高達63%。他們的比特流接口實現了高達2MB/s的數據傳輸帶寬。
Maxeler的用法可能與XBERT提供的最為相似。然而,Maxeler(a)僅將此BRAM路徑用于編譯器內部生成的內存的特定用途,(b)不提供可供開發人員用于任何內存或任何工具鏈的通用API(c)他們的工具必須控制邏輯內存到BRAMs的映射,因為他們沒有足夠的信息來確定Xilinx工具如何將邏輯內存映射到物理內存。
類似地,Xilinx Vivado提供了對更改比特流中配置存儲器初始值的支持,主要是為了支持微LAZE處理器的指令存儲器[26]。這包括一個BRAM內存映射信息(MMI)文件,該文件記錄用于支持MicroBlaze和Xilinx參數化宏(XPM)內存的物理BRAM,以及一個UpdateMEM工具,該工具可以使用邏輯內存文件中的數據更新比特流[27]。Vivado生成的MMI并沒有覆蓋設計中的所有邏輯內存,UpdateMEM只生成一個完整的比特流。
XBERT通過提供對比特流讀寫路徑的開源邏輯級訪問,填補了上述相關工作中的所有空白。它容納了所有的設計,所有的記憶,以及所有通過DCPs的工具流。
》4.4 現有的比特流操作支持
有許多工具可用于創建比特流操作工具。XBERT系統在一定程度上是基于其中一些。
Xilinx工具長期以來一直為內存生成邏輯位置(LL)文件,作為比特流回讀生成的一部分[28]。LL文件包含物理BRAM中每個數據位的幀和位位置,但不提供有關邏輯內存以及如何將邏輯內存映射到多個物理BRAM塊的映射信息。盡管如此,LL文件對于破譯XBERT內的BRAM的幀和位位置是有用的,如圖1所示。
X-Ray項目[29]和最近的U-Ray項目[30]提供了將Xilinx 7系列和UltraScale+設備中的配置位映射到幀和位位置的數據庫。它們不包含特定設計中邏輯到物理內存映射的信息,但提供了用于比特流編碼的信息和工具(了解比特流中物理內存位的位置)。
在X-Ray項目的基礎上,BYU開發了一個開源工具prjxray-bram-patch[31],它的作用與Vivado的UpdateMEM類似,但適用于設計中的所有邏輯內存和所有設計流。bram-patch工具定義了一個內存描述數據(MDD)文件,該文件的作用與Xilinx MMI文件類似。MDD文件源自使用Tcl的Vivado設計,它為設計中的每個邏輯內存描述了邏輯內存映射到的物理內存集合、邏輯內存位在物理內存之間的分區方式以及位如何打包到物理RAMB原語的INIT字符串中。XBERT系統將此信息用作邏輯到物理映射步驟的一部分(圖1)。
5. XBERT API
XBERT設計用于在Zynq SoC上的嵌入式APU內核上運行。如圖2所示,它提供了邏輯級接口,高于由xilfpga提供的接口或由諸如BITMAN的物理級比特流操作工具提供的接口[24]。它通過擴展xilfpga來實現這一點,并為BRAM寫入提供部分重新配置支持和命令生成(第六節)。
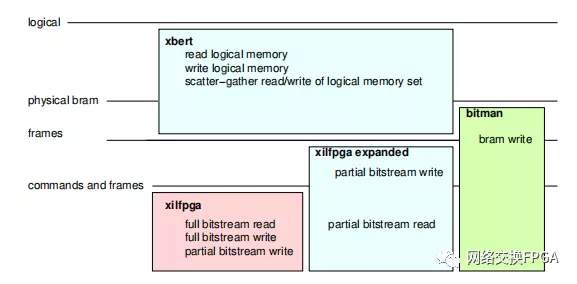
圖2:XBERT的API分層
注:Xilinx提供的淺紅色;本工程提供淺藍色;來自[24]的淺綠色。
入門級XBERT接口是一對簡單的例程,提供一個類似DMA的接口來讀取或寫入整個邏輯內存。

這些例程處理內存的幀格式和邏輯格式之間的位洗牌,以及執行所需的部分重新配置讀寫。
為了支持這些API調用,XBERT預處理工具處理MDD文件(第IV-D節)生成文件mydesign.h和mydesign.c(圖1)。其中包括設計中特定內存的C代碼定義,包括邏輯到物理的轉換表。
上述簡單API的一個限制是,每個讀或寫調用首先執行邏輯到物理內存的轉換,然后對設備執行比特流讀或寫操作。如果應用程序需要讀取或更新映射到同一配置幀的多個不同邏輯內存,則這可能是低效的。
為了實現更高效的傳輸,XBERT還提供了一個API,可以讀寫一組多個內存,就像分散-聚集DMA操作一樣。這是bert_transfuse()調用,允許XBERT執行一組幀讀取、轉換,然后執行一組幀寫入,覆蓋可能共享一組幀的所有邏輯內存:
Bert_transfuse例程使用一個數組來描述邏輯內存集合上的操作。為了描述每個transfusion操作,它使用了一個結構(bert_meminfo)。結構指定了內存、操作(讀或寫)以及我們正在內存中讀或寫的邏輯地址范圍。為了支持比64b更寬的數據,這支持一個數組,每個數組槽有多個數據字。并且,通過指定起始地址和長度,我們允許對邏輯內存中的字子集進行操作。這允許訪問和更新與保存邏輯存儲器的數據的BRAMs相關聯的幀的子集,當僅需要讀取或寫入存儲器的一部分時,這是更有效的。傳輸操作還將寫入數據集與PCAP控制指令一起排列,以便可以使用單個DMA寫入傳輸來執行這些操作,從而最小化DMA設置的開銷。
APIs假定執行讀寫操作是安全的。應用程序負責將計算置于安全狀態,即在讀或寫過程中不寫入內存。例如,使用Vivado/VitisHLS生成的標準Xilinx IP塊級接口協議[32],可以監視要完成的塊(ap_done),執行XBERT操作,然后重新啟動模塊(ap_start)。
6. 部分重構
部分重配置是在不影響剩余資源運行的情況下加載一部分FPGA資源的配置數據。在現代Xilinx設備中,配置的原子單元是沿FPGA列組織的幀。在Xilinx UltraScale+系列中,每幀有93個32b字。由于BRAM數據只占總比特流的一小部分,因此使用部分重新配置僅訪問BRAM幀與完整的比特流讀寫相比減少了比特流讀寫時間。
在現代FPGA設備中,嵌入式ram被放置在列中。UltraScale+系列具有36Kb內存(RAMB36),每個內存可以交替配置為一對18Kb內存(RAMB18)。Xilinx UltraScale+系列設備中的每個幀包含12個RAMB36存儲器[33,第8章,配置幀],每個RAMB36具有144b,兩個RAMB18中的每個具有72b。覆蓋BRAM組需要256幀(參見圖3)。幀中每個BRAM的144b組被分組為240b塊。在大致位于240b塊中間的幀中,每個144b RAMB36組有一個寫使能位。寫入允許一次更新單個BRAM36,但始終需要以幀為單位傳輸數據。BRAM數據幀與保持路由或LUT配置的幀是分開的。
Zynq設備包括一個處理器配置訪問端口(PCAP),允許嵌入式處理器讀寫配置幀。對于高速接入,處理器可以配置DMA數據傳輸到PCAP以執行部分重新配置操作。UltraScale+PCAP的帶寬為4B,峰值工作頻率為200 MHz,最高支持800 MB/s[33,第8章,配置時間]。
Xilinx提供了xilfpga庫[34](圖2),用于在Zynq UltraScale+組件上執行DMA比特流傳輸。它允許對包含到PCAP的控制命令頭的.bit文件進行完全比特流加載、回讀和部分比特流加載。
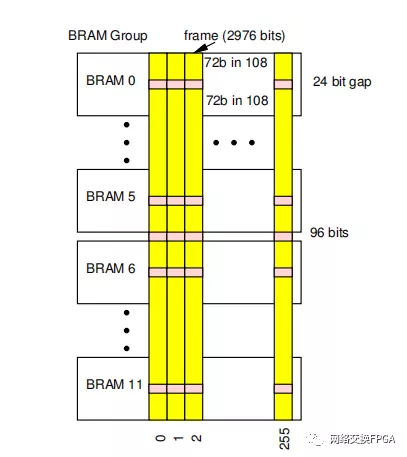
圖3:UltraScale+BRAM內容的框架組織
XBERT提供了xilfpga API中例程的擴展版本(圖2)。xilfpga沒有提供一個基本的比特流回讀操作,因此我們修改了讀操作以同時接收幀地址和幀數。XBERT還提供了write的一個版本,它接受原始幀數據并填充配置命令來設置幀地址和指定寫操作,因為將原始幀數據轉換為適當的部分比特流需要這些命令。這種擴展是支持寫操作所必需的,因為我們正在生成自己的幀集,并且沒有通常由Vivado生成比特流時生成的比特流配置命令頭。
由于缺乏流量控制,FPGA讀回操作只能以低于200 MHz峰值操作(秒)的速率可靠運行(第六節。2019.2 xilfpga版本中的默認配置使用PCAP時鐘發生器配置(PCAP _CTRL(CRL _APB)寄存器)將時鐘設置為23.8 MHz,最高吞吐量為95 MB/s。我們的經驗表明,150MHz可能工作可靠,最高吞吐量為600MB/s。
7. 壓縮轉換表
邏輯到物理轉換表(第三節) 可能很大。如果我們簡單地在一個BRAM中為每個位存儲一個32b幀地址和一個16b位位置,那么轉換表至少是48位× 比我們希望繪制的BRAM數據總量還要大。幸運的是,有一些結構。通常情況下,當多個位在同一幀中時,我們不需要為每個位存儲幀。這樣可以節省3倍。
為了進一步壓縮,我們利用了位位置在幀間重復的方式。為了說明這一點,我們先來考慮一個簡單的BRAM設計案例。單個幀將在其144位中保存一定數量的邏輯字。在72b寬的邏輯存儲器的情況下,這可以是2個邏輯字;對于8b寬的邏輯內存,這可能是16個邏輯字。將Wframe定義為該值(上面的2或16)。對于每個連續的Wframe字組,幀內的偏移位置是相同的,這允許我們通過算法確定幀偏移量(邏輯地址/Wframe),并重用幀內(最多144)位到幀內偏移量的單個位映射。對于這種單BRAM設計,這意味著我們只需要存儲一個幀地址(基址)和(最多)144位偏移地址(對于一幀中的2976位可以使用12b,但是我們舍入到16b)。所以,我們最多需要32+144×16=2336b而不是48×36864=1.7 Mbits,無壓縮。
一般來說,我們必須支持邏輯內存映射到物理內存的各種方法。這可能意味著并行組織多個BRAMs以支持邏輯字寬度(例如,8個BRAMs,每個BRAMs提供32b字的4b),多個BRAMs覆蓋不同的地址范圍以處理深度內存(例如,2個BRAMs覆蓋36x2048內存,其中一個處理地址0到1023,另一個處理地址1024到2047),或其組合。甚至在某些情況下,組件BRAMs具有不均勻的子寬度和子深度(例如第三節) 是的。因此,一般的壓縮情況更需要處理這些額外的不規則性。盡管如此,幀之間還是有規律性的,可以用算法來描述。這使我們能夠概括單個BRAM觀測值,形成一個通用的壓縮策略。利用這些觀察,我們顯著地壓縮了翻譯表(表3)。
8. 加速翻譯
正如我們在表4中看到的,一旦我們加快了讀DMA的速度,翻譯時間就比DMA傳輸時間慢。即使使用預編譯的表,代碼仍然是一次提取和插入一位。我們實現了一種多位加速轉換,其中我們預先計算字(或幀)中的位序列(例如,一個字節)的影響,以創建要應用于幀(或字)的位向量,并將它們存儲在表中。

這減少了處理器周期,但需要更大的轉換表。我們目前的實現支持這些針對單個BRAM存儲器的轉換表。
9. 評價
如第三章和貫穿本文的重點,XBERT傳輸的大小和性能高度依賴于設計,依賴于API的使用,并且受到我們的優化的影響。在本節中,我們將評估API在多個場景中的性能,以具體描述這些不同場景的性能影響。
》9.1 方法論
我們的實驗使用Vivado 2018.3,包括SDK。嵌入式ARM處理器代碼編譯-O3。實驗在Ultra96 v2板上進行,該板包括一個包含216個RAMB36的XCZU3EG。設計是在裸機配置上運行的。我們集成了2019.2版的xilfpga源代碼,原因是2018.3版的xilfpga存在缺陷。
一個主要的性能指標是有效吞吐量。有效吞吐量解釋了這樣一個事實,即有用的數據只是在幀中傳輸的數據的子集。例如,如果我們只想在UltraScale+設備幀中包含一個RAMB36的內容,則每幀可獲得144個相關位,但必須傳輸整個2976位幀。
為了說明典型的應用場景,我們提供了兩個完整的設計。這些給出了幀如何從多個邏輯存儲器共享BRAMs的一些指示。
哈夫曼編碼-我們的Verilog設計來自第三章F節。它有4個邏輯內存,消耗4個18和3903個LUT。每個邏輯內存都可以放在一個內存中。
翻譯-演示用的網表來自于Rosetta HLS基準電路 [35]。它有11個邏輯存儲器,消耗41個ramb36、9個ramb18和11109個LUTs。一些內存是大的,需要很多的BRAMs。有些內存在沒有定義位的地方有間隙。
》9.2 結果
① 原始比特流數據傳輸
表2顯示原始比特流傳輸時間和原始有效吞吐量。這將顯示DMA傳輸性能和含義,而不需要翻譯所需的時間,這將在下一節中分開。注意,訪問一個幀中的所有BRAM(單個BRAM幀集行)可以提供最高的有效吞吐量。由于BRAM幀中的大多數位是BRAM數據位,因此有效帶寬超過原始帶寬的一半。請注意,即使我們關心芯片上所有BRAM中的每一位BRAM,該有效帶寬也高于完整的比特流讀寫,因為部分讀取只是讀取保存BRAM數據的幀。
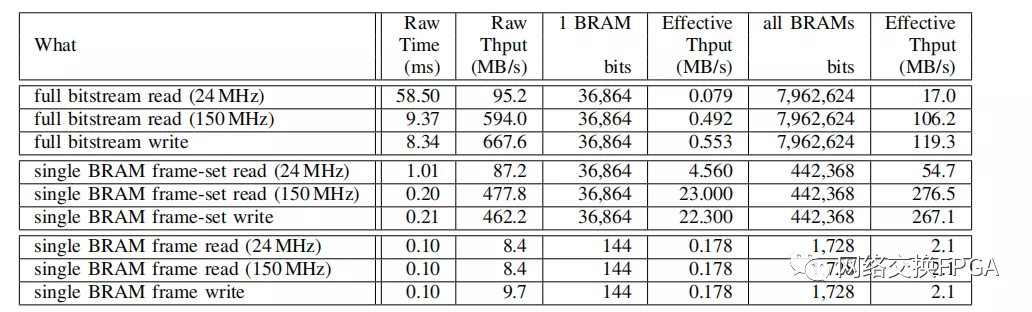
表2:XCZU3EG上的原始比特流讀寫時間
注:“幀集”是包含單個BRAM的內容的256幀的集合(圖3)。
24MHz是xilfpga中的讀取速度;150MHz是我們能夠可靠運行DMA回讀的最高速度。
② 翻譯
表III報告了轉換表的大小和時間,以及在邏輯和框架表示之間進行轉換的有效吞吐量。
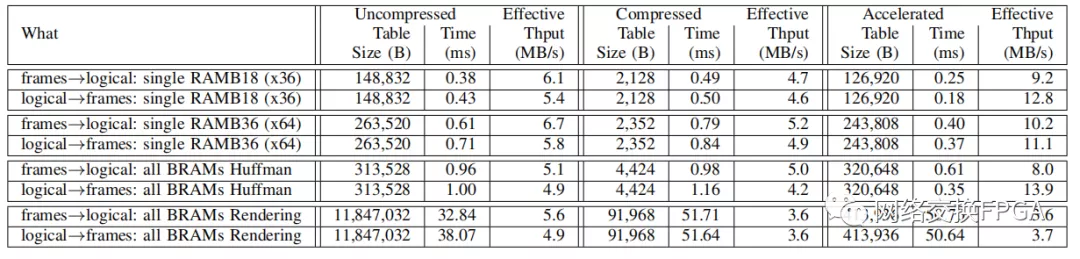
表3:XCZU3EG上的翻譯時間
表III表明我們可以將大約兩個數量級的轉換表縮減到千字節范圍內(第七節)。壓縮會稍微減慢翻譯速度。加速度(第八節) 大約減半翻譯時間,同時添加大約與未壓縮表一樣大的表。在渲染的11個內存中,有7個是單BRAM內存,但是這些內存只占4%的位,所以在轉換所有內存時,加速的影響很小。
③ BERT API操作
單內存:表4總結了讀寫一篇簡單的文章的表現×64個內存,填充一個36塊。第一行顯示默認的讀取速度(第六節) 第二個顯示了將PCAP DMA讀取速度提高到150mhz(600MB/s)的影響。第三行顯示壓縮的影響;在這種情況下,它會稍微減慢翻譯速度。第四行顯示了加速度的影響,這大約是平移時間的一半。
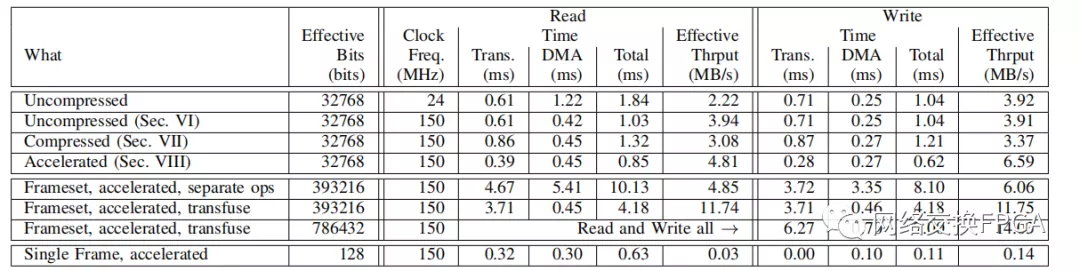
表4:基于XZCU3EG的BERT-API單RAM36性能
注:24MHz是xilfpga中的讀取速度;150MHz是我們能夠可靠運行DMA回讀的最高速度。
接下來的三行(標記為“Frameset”)查看傳輸共享同一幀集的所有12個內存。第一種情況捕獲對每個內存執行分離 bert_read和bert_write操作的總時間;這大約需要12倍于單個BRAM情況的時間,因為它只是單個時間的總和,并且實現了相同的帶寬。中間一行使用bert_transfuse在一次操作中讀取或寫入所有12個存儲器;結果,DMA傳輸時間與每個BRAM讀取中的傳輸時間相當,而轉換時間幾乎是12倍,因為每個存儲器必須單獨轉換。由于DMA傳輸時間與單個RAMB36讀寫中的轉換時間大致相當,因此這將導致大約兩倍的凈吞吐量。幀集的最后一行顯示了執行單個傳輸操作的影響,該操作同時讀取和寫入所有內存。
表中的最后一行顯示從RAMB36中讀寫一幀(兩個64b字)。這比讀或寫整個記憶和翻譯所有的框架要花更少的時間。這里的翻譯時間可以很短。然而,由于在設置DMA操作時有相當多的固定時間,因此凈吞吐量很低。
④ BERT API操作
應用層:單個BRAM和所有BRAM在Tab中的幀集cases中的轉換,在表4中預期典型表現。表5表示當我們讀取或寫入所有存儲器時應用程序的透析性能。哈夫曼展示了一個2-3×透析操作的改進。渲染幾乎沒有什么好處,在轉換的情況下,轉換需要更多的時間,這可能是由于緩存效果對于容納所有內存所需的大幀內存造成的。由于主導時間通常是在翻譯中,所以在讀寫數據時,總輸入時間基本上是線性的。
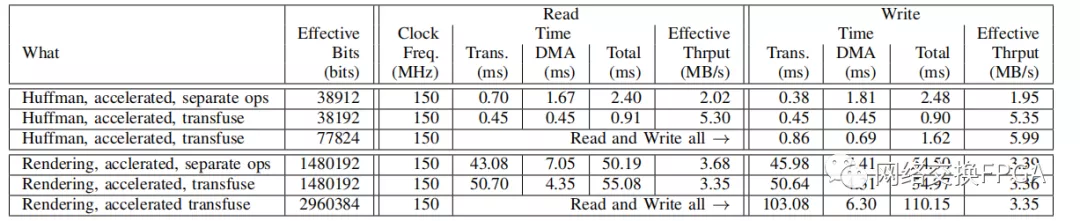
表5:基于XZCU3EG的BERT-API應用性能
注:150MHz是我們能夠可靠運行DMA回讀的最高速度。
10. 結論
現代FPGA上的配置路徑提供了對嵌入式存儲器的訪問。就FPGA資源而言,它是一個輕量級接口,用于從嵌入式存儲器中獲取數據。XBERT提供了一個用戶級API,使應用程序開發人員可以輕量級地使用此功能。使用XBERT訪問邏輯內存就像API調用一樣簡單。這有助于在程序啟動時加載初始內存狀態,在程序完成、調試時恢復最終數據和狀態,以及在FPGA結構和嵌入式內核之間進行不頻繁的數據傳輸。XBERT API負責邏輯到物理的轉換,包括壓縮必要的轉換信息和最小化必須傳入和傳出FPGA的數據的優化。XBERT工具流自動生成API所需的翻譯信息。









 工商網監
工商網監
評論