 電子發(fā)燒友App
電子發(fā)燒友App


?
語音合成是通過機(jī)械的、電子的方法產(chǎn)生人造語音的技術(shù)。TTS技術(shù)(又稱文語轉(zhuǎn)換技術(shù))隸屬于語音合成,它是將計(jì)算機(jī)自己產(chǎn)生的、或外部輸入的文字信息轉(zhuǎn)變?yōu)榭梢月牭枚摹⒘骼臐h語口語輸出的技術(shù)
語音合成技術(shù)
語音合成和語音識(shí)別技術(shù)是實(shí)現(xiàn)人機(jī)語音通信,建立一個(gè)有聽和講能力的口語系統(tǒng)所必需的兩項(xiàng)關(guān)鍵技術(shù)。使電腦具有類似于人一樣的說話能力,是當(dāng)今時(shí)代信息產(chǎn)業(yè)的重要競(jìng)爭(zhēng)市場(chǎng)。和語音識(shí)別相比,語音合成的技術(shù)相對(duì)說來要成熟一些,并已開始向產(chǎn)業(yè)化方向成功邁進(jìn),大規(guī)模應(yīng)用指日可待。
語音合成,又稱文語轉(zhuǎn)換(Text to Speech)技術(shù),能將任意文字信息實(shí)時(shí)轉(zhuǎn)化為標(biāo)準(zhǔn)流暢的語音朗讀出來,相當(dāng)于給機(jī)器裝上了人工嘴巴。它涉及聲學(xué)、語言學(xué)、數(shù)字信號(hào)處理、計(jì)算機(jī)科學(xué)等多個(gè)學(xué)科技術(shù),是中文信息處理領(lǐng)域的一項(xiàng)前沿技術(shù),解決的主要問題就是如何將文字信息轉(zhuǎn)化為可聽的聲音信息,也即讓機(jī)器像人一樣開口說話。我們所說的“讓機(jī)器像人一樣開口說話”與傳統(tǒng)的聲音回放設(shè)備(系統(tǒng))有著本質(zhì)的區(qū)別。傳統(tǒng)的聲音回放設(shè)備(系統(tǒng)),如磁帶錄音機(jī),是通過預(yù)先錄制聲音然后回放來實(shí)現(xiàn)“讓機(jī)器說話”的。這種方式無論是在內(nèi)容、存儲(chǔ)、傳輸或者方便性、及時(shí)性等方面都存在很大的限制。而通過計(jì)算機(jī)語音合成則可以在任何時(shí)候?qū)⑷我馕谋巨D(zhuǎn)換成具有高自然度的語音,從而真正實(shí)現(xiàn)讓機(jī)器“像人一樣開口說話”。
文語轉(zhuǎn)換系統(tǒng)實(shí)際上可以看作是一個(gè)人工智能系統(tǒng)。為了合成出高質(zhì)量的語言,除了依賴于各種規(guī)則,包括語義學(xué)規(guī)則、詞匯規(guī)則、語音學(xué)規(guī)則外,還必須對(duì)文字的內(nèi)容有很好的理解,這也涉及到自然語言理解的問題。下圖顯示了一個(gè)完整的文語轉(zhuǎn)換系統(tǒng)示意圖。文語轉(zhuǎn)換過程是先將文字序列轉(zhuǎn)換成音韻序列,再由系統(tǒng)根據(jù)音韻序列生成語音波形。其中第一步涉及語言學(xué)處理,例如分詞、字音轉(zhuǎn)換等,以及一整套有效的韻律控制規(guī)則;第二步需要先進(jìn)的語音合成技術(shù),能按要求實(shí)時(shí)合成出高質(zhì)量的語音流。因此一般說來,文語轉(zhuǎn)換系統(tǒng)都需要一套復(fù)雜的文字序列到音素序列的轉(zhuǎn)換程序,也就是說,文語轉(zhuǎn)換系統(tǒng)不僅要應(yīng)用數(shù)字信號(hào)處理技術(shù),而且必須有大量的語言學(xué)知識(shí)的支持。
TTS的基本結(jié)構(gòu)
語言學(xué)處理
在文語轉(zhuǎn)換系統(tǒng)中起著重要的作用,主要模擬人對(duì)自然語言的理解過程——文本規(guī)整、詞的切分、語法分析和語義分析,使計(jì)算機(jī)對(duì)輸入的文本能完全理解,并給出后兩部分所需要的各種發(fā)音提示。
韻律處理
為合成語音規(guī)劃出音段特征,如音高、音長(zhǎng)和音強(qiáng)等,使合成語音能正確表達(dá)語意,聽起來更加自然。
聲學(xué)處理
根據(jù)前兩部分處理結(jié)果的要求輸出語音,即合成語音。
參數(shù)合成
在語音合成技術(shù)的發(fā)展中,早期的研究主要是采用參數(shù)合成方法。值得提及的是Holmes的并聯(lián)共振峰合成器(1973)和Klatt的串/并聯(lián)共振峰合成器(1980),只要精心調(diào)整參數(shù),這兩個(gè)合成器都能合成出非常自然的語音。最具代表性的文語轉(zhuǎn)換系統(tǒng)當(dāng)數(shù)美國(guó)DEC公司的DECtalk(1987)。但是經(jīng)過多年的研究與實(shí)踐表明,由于準(zhǔn)確提取共振峰參數(shù)比較困難,雖然利用共振峰合成器可以得到許多逼真的合成語音,但是整體合成語音的音質(zhì)難以達(dá)到文語轉(zhuǎn)換系統(tǒng)的實(shí)用要求。
波形拼接
自八十年代末期至今,語言合成技術(shù)又有了新的進(jìn)展,特別是基音同步疊加(PSOLA)方法的提出(1990),使基于時(shí)域波形拼接方法合成的語音的音色和自然度大大提高。九十年代初,基于PSOLA技術(shù)的法語、德語、英語、日語等語種的文語轉(zhuǎn)換系統(tǒng)都已經(jīng)研制成功。這些系統(tǒng)的自然度比以前基于LPC方法或共振峰合成器的文語合成系統(tǒng)的自然度要高,并且基于PSOLA方法的合成器結(jié)構(gòu)簡(jiǎn)單易于實(shí)時(shí)實(shí)現(xiàn),有很大的商用前景。
語音合成系統(tǒng)和語音合成方法
一種語音合成系統(tǒng),其包括:分割單元,其被配置成將對(duì)應(yīng)于目標(biāo)語音的音位串分割為多個(gè)節(jié)段,來產(chǎn)生第一節(jié)段序列;
選擇單元,其被配置成基于第一節(jié)段序列通過組合多個(gè)語音單元產(chǎn)生對(duì)應(yīng)于第一節(jié)段序列的多個(gè)第一語音單元串,并從所述多個(gè)第一語音單元串中選擇一個(gè)語音單元串;和連接單元,其被配置成連接包含在所選擇語音單元串中的多個(gè)語音單元,以產(chǎn)生合成語音,選擇單元包括檢索單元,其被配置成反復(fù)實(shí)施第一處理和第二處理,該第一處理基于對(duì)應(yīng)于第二節(jié)段序列的最多W個(gè)(W為預(yù)定值)第二語音單元串產(chǎn)生對(duì)應(yīng)于第三節(jié)段序列的多個(gè)第三語音單元串,所述第二節(jié)段序列作為第一節(jié)段序列中的部分序列,所述第三節(jié)段序列作為通過將節(jié)段添加給第二節(jié)段序列而獲得的部分序列,第二處理從所述多個(gè)第三語音單元串中選擇最多W個(gè)第三語音單元串,第一計(jì)算單元,其被配置成計(jì)算所述多個(gè)第三語音單元串中每個(gè)的總成本,第二計(jì)算單元,其被配置成基于涉及語音單元數(shù)據(jù)獲取速度的限制來為所述多個(gè)第三語音單元串中的每個(gè)計(jì)算對(duì)應(yīng)于總成本的懲罰系數(shù),其中懲罰系數(shù)依賴于接近所述限制的程度,和第三計(jì)算單元,其被配置成通過使用懲罰系數(shù)修正總成本來計(jì)算所述多個(gè)第三語音單元串中每個(gè)的估計(jì)值,其中檢索單元基于所述多個(gè)第三語音單元串中每個(gè)的估計(jì)值從所述多個(gè)第三語音單元串中選擇最多W個(gè)第三語音單元串。

常用語音合成方法的比較
“未來的十年是語音技術(shù)的時(shí)代”。隨著語音技術(shù)研究的突破,其對(duì)計(jì)算機(jī)發(fā)展和社會(huì)生活的重要性日益凸現(xiàn)出來。語音合成技術(shù)是語音技術(shù)中十分實(shí)用的一項(xiàng)重要技術(shù),它能解決人民大眾的實(shí)際需求,能夠深入到社會(huì)的各行各業(yè)中去。
語音合成技術(shù)經(jīng)歷了一個(gè)逐步發(fā)展的過程,從參數(shù)合成到拼接合成,再到兩者的逐步結(jié)合,其不斷發(fā)展的動(dòng)力是人們認(rèn)知水平和需求的提高。目前,常用的語音合成方法主要有:共振峰合成、LPC合成、PSOLA拼接合成和LMA聲道模型技術(shù)。它們各有優(yōu)缺點(diǎn),人們?cè)趹?yīng)用過程中往往將多種技術(shù)有機(jī)地結(jié)合在一起,或?qū)⒁环N技術(shù)的優(yōu)點(diǎn)運(yùn)用到另一種技術(shù)上,以克服另一種技術(shù)的不足。
共振峰合成
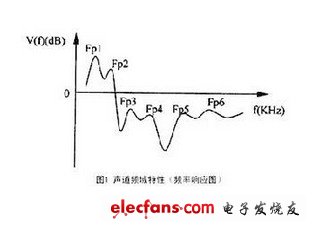
語音合成的理論基礎(chǔ)是語音生成的數(shù)學(xué)模型。該模型語音生成過程是在激勵(lì)信號(hào)的激勵(lì)下,聲波經(jīng)諧振腔(聲道),由嘴或鼻輻射聲波。因此,聲道參數(shù)、聲道諧振特性一直是研究的重點(diǎn)。習(xí)慣上,把聲道傳輸頻率響應(yīng)上的極點(diǎn)稱之為共振峰,而語音的共振峰頻率(極點(diǎn)頻率)的分布特性決定著該語音的音色。
音色各異的語音具有不同的共振峰模式,因此,以每個(gè)共振峰頻率及其帶寬作為參數(shù),可以構(gòu)成共振峰濾波器。再用若干個(gè)這種濾波器的組合來模擬聲道的傳輸特性(頻率響應(yīng)),對(duì)激勵(lì)源發(fā)出的信號(hào)進(jìn)行調(diào)制,再經(jīng)過輻射模型就可以得到合成語音。這就是共振峰合成技術(shù)的基本原理。基于共振峰的理論有以下三種實(shí)用模型。
1)級(jí)聯(lián)型共振峰模型
在該模型中,聲道被認(rèn)為是一組串聯(lián)的二階諧振器。該模型主要用于絕大部分元音的合成。
2)并聯(lián)型共振峰模型
許多研究者認(rèn)為,對(duì)于鼻化元音等非一般元音以及大部分輔音,上述級(jí)聯(lián)型模型不能很好地加以描述和模擬,因此,構(gòu)筑和產(chǎn)生了并聯(lián)型共振峰模型。
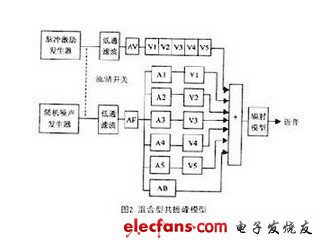
3)混合型共振峰模型
在級(jí)聯(lián)型共振峰合成模型中,共振峰濾波器首尾相接;而在并聯(lián)型模型中,輸入信號(hào)先分別通過幅度調(diào)節(jié)再加到每一個(gè)共振峰濾波器上,然后將各路的輸出疊加起來。將兩者比較,對(duì)于合成聲源位于聲道末端的語音(大多數(shù)的元音),級(jí)聯(lián)型合乎語音產(chǎn)生的聲學(xué)理論,并且無需為每一個(gè)濾波器分設(shè)幅度調(diào)節(jié);而對(duì)于合成聲源位于聲道中間的語音(大多數(shù)清擦音和塞音),并聯(lián)型則比較合適,但是其幅度調(diào)節(jié)很復(fù)雜。基于此種考慮,人們將兩者結(jié)合在一起,提出了混和型共振峰模型。
共振峰模型是基于對(duì)聲道的一種比較準(zhǔn)確的模擬,因而可以合成出自然度比較高的語音,另外由于共振峰參數(shù)有著明確的物理意義,直接對(duì)應(yīng)于聲道參數(shù),因此,可以容易利用共振峰描述自然語流中的各種現(xiàn)象,并且總結(jié)聲學(xué)規(guī)則,最終用于共振峰合成系統(tǒng)。
但是,人們同時(shí)也發(fā)現(xiàn)該技術(shù)有明顯的弱點(diǎn)。首先由于它是建立在對(duì)聲道的模擬上,因此,對(duì)于聲道模型的不精確勢(shì)必會(huì)影響其合成質(zhì)量。另外,實(shí)際工作表明,共振峰模型雖然描述了語音中最基本最主要的部分,但并不能表征影響語音自然度的其他許多細(xì)微的語音成分,從而影響了合成語音的自然度。另外,共振峰合成器控制十分復(fù)雜,對(duì)于一個(gè)好的合成器來說,其控制參數(shù)往往達(dá)到幾十個(gè),實(shí)現(xiàn)起來十分困難。
基于這些原因,研究者繼續(xù)尋求和發(fā)現(xiàn)其他新的合成技術(shù)。人們從波形的直接錄制和播放得到啟發(fā),提出了基于波形拼接的合成技術(shù),LPC合成技術(shù)和PSOLA合成技術(shù)是其中的代表。與共振峰合成技術(shù)不同,波形拼接合成是基于對(duì)錄制的合成基元的波形進(jìn)行拼接,而不是基于對(duì)發(fā)聲過程的模擬。
LPC參數(shù)合成
波形拼接技術(shù)的發(fā)展與語音的編、解碼技術(shù)的發(fā)展密不可分,其中LPC技術(shù)(線性預(yù)測(cè)編碼技術(shù))的發(fā)展對(duì)波形拼接技術(shù)產(chǎn)生了巨大的影響。LPC合成技術(shù)本質(zhì)上是一種時(shí)間波形的編碼技術(shù),目的是為了降低時(shí)間域信號(hào)的傳輸速率。
LPC合成技術(shù)的優(yōu)點(diǎn)是簡(jiǎn)單直觀。其合成過程實(shí)質(zhì)上只是一種簡(jiǎn)單的解碼和拼接過程。另外,由于波形拼接技術(shù)的合成基元是語音的波形數(shù)據(jù),保存了語音的全部信息,因而對(duì)于單個(gè)合成基元來說能夠獲得很高的自然度。
但是,由于自然語流中的語音和孤立狀況下的語音有著極大的區(qū)別,如果只是簡(jiǎn)單地把各個(gè)孤立的語音生硬地拼接在一起,其整個(gè)語流的質(zhì)量勢(shì)必是不太理想的。而LPC技術(shù)從本質(zhì)上來說只是一種錄音+重放,對(duì)于合成整個(gè)連續(xù)語流LPC合成技術(shù)的效果是不理想的。因此,LPC合成技術(shù)必須和其他技術(shù)相結(jié)合,才能明顯改善LPC合成的質(zhì)量。
PSOLA合成技術(shù)
20世紀(jì)80年代末提出的PSOLA合成技術(shù)(基音同步疊加技術(shù))給波形拼接合成技術(shù)注入了新的活力。PSOLA技術(shù)著眼于對(duì)語音信號(hào)超時(shí)段特征的控制,如基頻、時(shí)長(zhǎng)、音強(qiáng)等的控制。而這些參數(shù)對(duì)于語音的韻律控制以及修改是至關(guān)重要的,因此,PSOLA技術(shù)比LPC技術(shù)具有可修改性更強(qiáng)的優(yōu)點(diǎn),可以合成出高自然度的語音。
PSOLA技術(shù)的主要特點(diǎn)是:在拼接語音波形片斷之前,首先根據(jù)上下文的要求,用PSOLA算法對(duì)拼接單元的韻律特征進(jìn)行調(diào)整,使合成波形既保持了原始發(fā)音的主要音段特征,又能使拼接單元的韻律特征符合上下文的要求,從而獲得很高的清晰度和自然度。
PSOLA技術(shù)保持了傳統(tǒng)波形拼接技術(shù)的優(yōu)點(diǎn),簡(jiǎn)單直觀,運(yùn)算量小,而且還能方便地控制語音信號(hào)的韻律參數(shù),具有合成自然連續(xù)語流的條件,得到了廣泛的應(yīng)用。
但是,PSOLA技術(shù)也有其缺點(diǎn)。首先,PSOLA技術(shù)是一種基音同步的語音分析/合成技術(shù),首先需要準(zhǔn)確的基因周期以及對(duì)其起始點(diǎn)的判定。基音周期或其起始點(diǎn)的判定誤差將會(huì)影響PSOLA技術(shù)的效果。其次,PSOLA技術(shù)是一種簡(jiǎn)單的波形映射拼接合成,這種拼接是否能夠保持平穩(wěn)過渡以及它對(duì)頻域參數(shù)有什么影響等并沒有得到解決,因此,在合成時(shí)會(huì)產(chǎn)生不理想的結(jié)果。
LMA聲道模型
隨著人們對(duì)語音合成的自然度和音質(zhì)的要求越來越高,PSOLA算法表現(xiàn)出對(duì)韻律參數(shù)調(diào)整能力較弱和難以處理協(xié)同發(fā)音的缺陷,因此,人們又提出了一種基于LMA聲道模型的語音合成方法。這種方法具有傳統(tǒng)的參數(shù)合成可以靈活調(diào)節(jié)韻律參數(shù)的優(yōu)點(diǎn),同時(shí)又具有比PSOLA算法更高的合成音質(zhì)。
目前,主要的語音合成技術(shù)是共振峰合成技術(shù)和基于PSOLA算法的波形拼接合成技術(shù)。這兩種技術(shù)各有所長(zhǎng),共振峰技術(shù)比較成熟,有大量的研究成果可以利用,而PSOLA技術(shù)則是比較新的技術(shù),具有良好的發(fā)展前景。過去這兩種技術(shù)基本上是互相獨(dú)立發(fā)展的,現(xiàn)在許多學(xué)者開始研究它們兩者之間的關(guān)系,試圖將兩者有效地結(jié)合起來,從而合成出更加自然的語流。
漢語
作為一種有調(diào)語言,漢語韻律特征非常復(fù)雜。古漢語的平仄以及現(xiàn)代漢語拼音,對(duì)于同樣一個(gè)音節(jié),出現(xiàn)在不同的環(huán)境下,其韻律參數(shù)都是各不相同的。用有限的存儲(chǔ)單元存儲(chǔ)基本漢語基本語音單元,進(jìn)而從有限的存儲(chǔ)單元中合成出無限詞匯,組成連續(xù)漢語語句。必須在一定的韻律規(guī)則下對(duì)音庫單元的韻律參數(shù)進(jìn)行調(diào)整,以得到符合當(dāng)前語言環(huán)境的語音庫單元。語音合成器用來完成這種功能。
中文語音合成系統(tǒng)在DSP下實(shí)現(xiàn)時(shí),除清晰度,能懂度和自然度外,還要求合成算法具有較底的運(yùn)算復(fù)雜度,盡量小的語音庫以減少對(duì)有限存儲(chǔ)空間的占用程度。










 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論