") 從one-hot、word embedding、rnn、seq2seq、transformer一步步逼近bert
從one-hot、word embedding、rnn、seq2seq、transformer一步步逼近bert
NLP
NLP:自然語言處理(NLP)是信息時(shí)代最重要的技術(shù)之一。理解復(fù)雜的語言也是人工智能的重要組成部分。而自google在2018年10月底公布BERT在11項(xiàng)nlp任務(wù)中的卓越表后,BERT(Bidirectional Encoder Representation from Transformers)就成為NLP一枝獨(dú)秀,本文將為大家層層剖析bert。
NLP常見的任務(wù)主要有: 中文自動(dòng)分詞、句法分析、自動(dòng)摘要、問答系統(tǒng)、文本分類、指代消解、情感分析等。
我們會(huì)從one-hot、word embedding、rnn、seq2seq、transformer一步步逼近bert,這些是我們理解bert的基礎(chǔ)。
Word Embedding
首先我們需要對(duì)文本進(jìn)行編碼,使之成為計(jì)算機(jī)可以讀懂的語言,在編碼時(shí),我們期望句子之間保持詞語間的相似行,詞的向量表示是進(jìn)行機(jī)器學(xué)習(xí)和深度學(xué)習(xí)的基礎(chǔ)。
word embedding的一個(gè)基本思路就是,我們把一個(gè)詞映射到語義空間的一個(gè)點(diǎn),把一個(gè)詞映射到低維的稠密空間,這樣的映射使得語義上比較相似的詞,他在語義空間的距離也比較近,如果兩個(gè)詞的關(guān)系不是很接近,那么在語義空間中向量也會(huì)比較遠(yuǎn)。
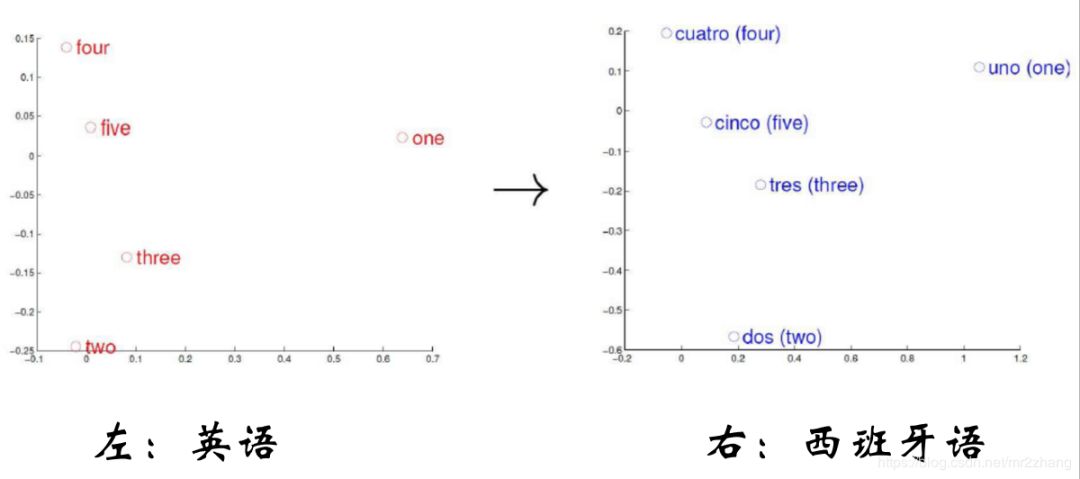
如上圖英語和西班牙語映射到語義空間,語義相同的數(shù)字他們?cè)谡Z義空間分布的位置是相同的
在句子的空間結(jié)構(gòu)上我們期望獲取更底層的之間的關(guān)系比如:
VKing- VQueen= VMan-VWomen
VParis- VFrance= VBerlin-VGerman
king和queen之間的關(guān)系相比與man與woman的關(guān)系大體應(yīng)該相同的,那么他們通過矩陣運(yùn)算,維持住這種關(guān)系;Paris 和France之間的關(guān)系相比與Berlin與German的關(guān)系大體應(yīng)該相同的,那么他們通過矩陣運(yùn)算,維持住這種關(guān)系。
簡(jiǎn)單回顧一下word embedding,對(duì)于nlp來說,我們輸入的是一個(gè)個(gè)離散的符號(hào),對(duì)于神經(jīng)網(wǎng)絡(luò)來說,它處理的都是向量或者矩陣。所以第一步,我們需要把一個(gè)詞編碼成向量。最簡(jiǎn)單的就是one-hot的表示方法。如下圖所示:

one-hot encoding編碼
通常我們有很多的詞,那只在出現(xiàn)的位置顯示會(huì),那么勢(shì)必會(huì)存在一些問題
高維的表示
稀疏性
正交性(任意兩個(gè)詞的距離都是1,除了自己和自己,這樣就帶來一個(gè)問題,貓和狗距離是1,貓和石頭距離也是1,但我們理解上貓和狗距離應(yīng)該更近一些)
兩個(gè)詞語義上無法正確表示,我們更希望低維的相似的比較接近,語義相近的詞距離比較近,語義不想近的詞,距離也比較遠(yuǎn)。解決的辦法就是word enbedding,是一種維位稠密的表示。
Neural Network Language Model(神經(jīng)網(wǎng)絡(luò)語言模型)
我們都知道word2vec,glove。其實(shí)更早之前的神經(jīng)網(wǎng)絡(luò)語言模型里出現(xiàn)。已經(jīng)有比較早的一個(gè)詞向量了。語言模型是nlp的一個(gè)基本任務(wù),是給定一個(gè)句子w,包括k個(gè)詞,我們需要計(jì)算這個(gè)句子的概率。使用分解成條件概率乘積的形式。變成條件概率的計(jì)算。
傳統(tǒng)的方法,統(tǒng)計(jì)的n-gram的,詞頻統(tǒng)計(jì)的形式,出現(xiàn)的多,概率就高,出現(xiàn)少概率就低,。
不能常時(shí)依賴上下文,如:他出生在法國(guó),他可以講一口流利的(__),我們希望法語的概率比英語、漢語的概率要高。n-gram記住只能前面有限幾個(gè)詞,若參數(shù)比較多,它根本學(xué)不到這復(fù)雜關(guān)系,這是傳統(tǒng)語言模型比較大的一個(gè)問題。這個(gè)可以通過后面的rnn、lstm解決,我們這里先不討論。
第二個(gè)問題就是泛化能力的問題,泛化能力,或者說不能共享上下文的信息,我要去(__)玩, 北京、上海應(yīng)該是一樣的,因?yàn)槎际侵袊?guó)的一個(gè)城市,概率應(yīng)該相等或相近的,但是因?yàn)轭A(yù)料中北京很多,所以出現(xiàn)上海的概率很低。那神經(jīng)網(wǎng)絡(luò)語言模型就可以解決這樣的問題。
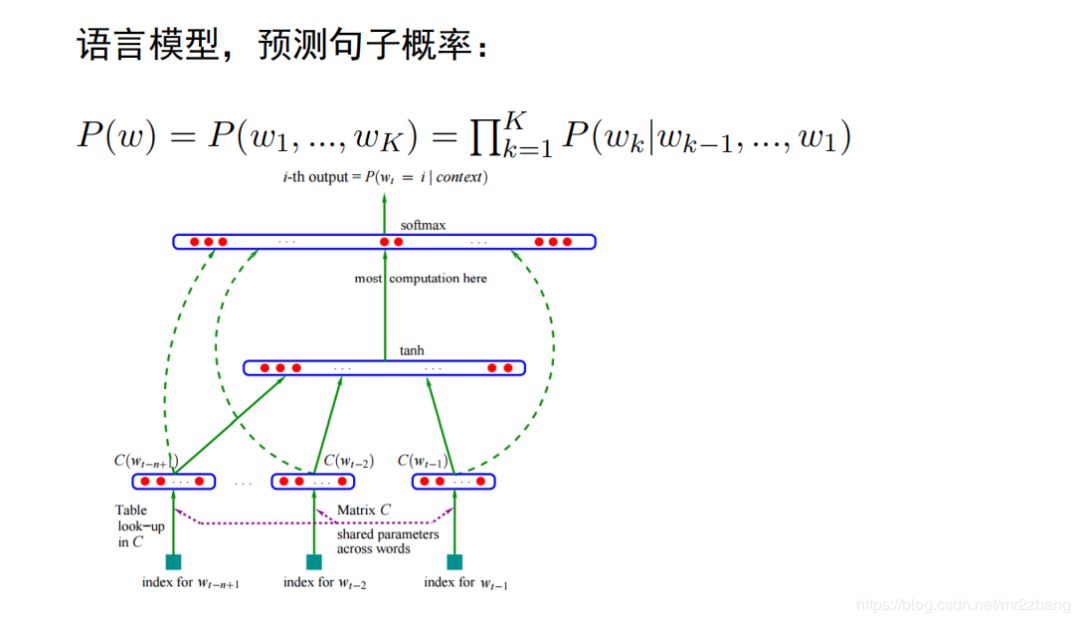
神經(jīng)網(wǎng)絡(luò)語言模型架構(gòu)如上圖:
將每個(gè)詞向量拼接成句子矩陣。每一列都是一個(gè)詞, 如北京、上海、 天津比較近,大致相同一塊區(qū)域,所以當(dāng)預(yù)測(cè)時(shí),可以給出大概相同的概率,不僅僅與預(yù)料中統(tǒng)計(jì)結(jié)果有關(guān)系。矩陣相乘就可以提取出這個(gè)詞,但是為了提取一個(gè)詞,我們要進(jìn)行一次矩陣運(yùn)算,這個(gè)比較低效,所以比較成熟的框架都提供了查表的方法,他的效率更高。
因?yàn)樯舷挛沫h(huán)境很相似,會(huì)共享類似的context,在問我要去 (__)概率會(huì)比較大。這也是神經(jīng)網(wǎng)絡(luò)語言模型的一個(gè)好處。我們通過神經(jīng)網(wǎng)絡(luò)語言模型得到一個(gè)詞向量。當(dāng)然我們也可以用其他的任務(wù)來做,一樣得到詞向量,比如句法分析,但是那些任務(wù)大部分是有監(jiān)督的學(xué)習(xí),需要大量的標(biāo)注信息。語言模型是非監(jiān)督的,資料獲取不需要很大的成本。
word2vec和神經(jīng)網(wǎng)絡(luò)語言模型不同,直接來學(xué)習(xí)這個(gè)詞向量,使用的基本假設(shè)是分布式假設(shè),如果兩個(gè)詞的上下文時(shí)相似的,那么他們語義也是相似的。
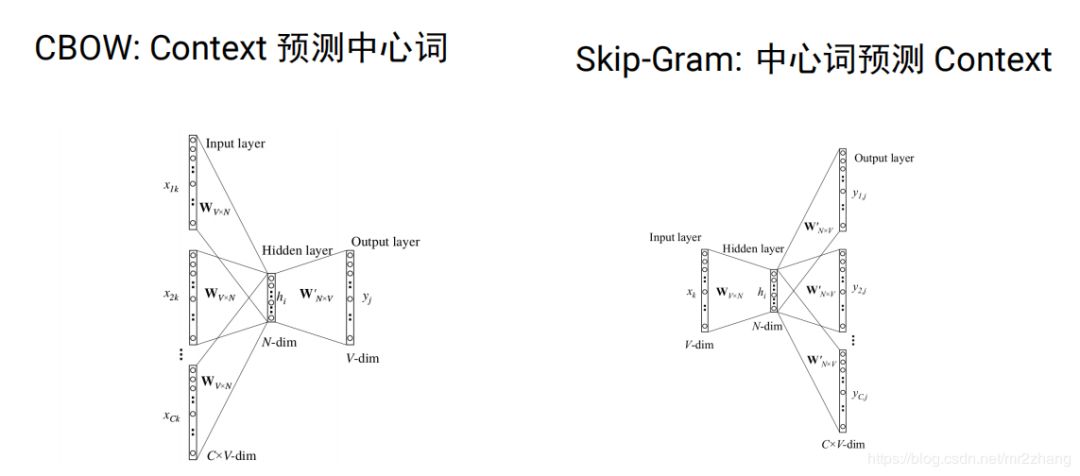
word2vec分為cbow(根據(jù)context預(yù)測(cè)中心詞)和skip-gram(根據(jù)中心詞預(yù)測(cè)context)兩種。
我們可以通過word2vec或者 glove這種模型在大量的未標(biāo)注的語料上學(xué)習(xí),我們可以學(xué)習(xí)到比較好的向量表示,可以學(xué)習(xí)到詞語之間的一些關(guān)系。比如男性和女性的關(guān)系距離,時(shí)態(tài)的關(guān)系,學(xué)到這種關(guān)系之后我們就可以把它作為特征用于后續(xù)的任務(wù),從而提高模型的泛化能力。
但是同時(shí)存在一些問題比如:
He deposited his money in this bank .
His soldiers were arrayed along the river bank .word embeding 有個(gè)問題就是我們的詞通常有很多語義的,比如bank是銀行還是河岸,具體的意思要取決與上下文,如果我們強(qiáng)行用一個(gè)向量來表示語義的話,只能把這兩種語義都編碼在這個(gè)向量里,但實(shí)際一個(gè)句子中,一個(gè)詞只有一個(gè)語義,那么這種編碼是有問題的。
RNN/LSTM/GRU
那么這種上下文的語義可以通過RNN/LSTM/GRU來解決,RNN與普通深度學(xué)習(xí)不同的是,RNN是一種序列的模型,會(huì)有一定的記憶單元,能夠記住之前的歷史信息,從而可以建模這種上下文相關(guān)的一些語義。RNN中的記憶單元可以記住當(dāng)前詞之前的信息。
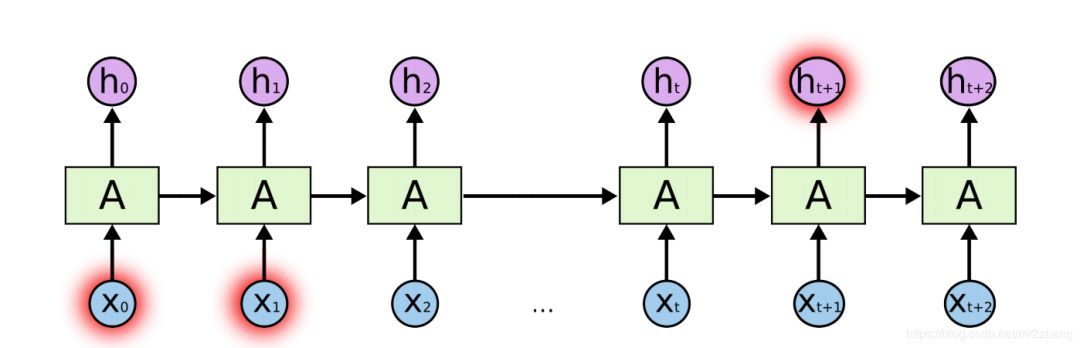
RR可以解決,理論上我們希望學(xué)到很長(zhǎng)的關(guān)系,但是由于梯度消失的問題,所以長(zhǎng)時(shí)依賴不能很好的訓(xùn)練。
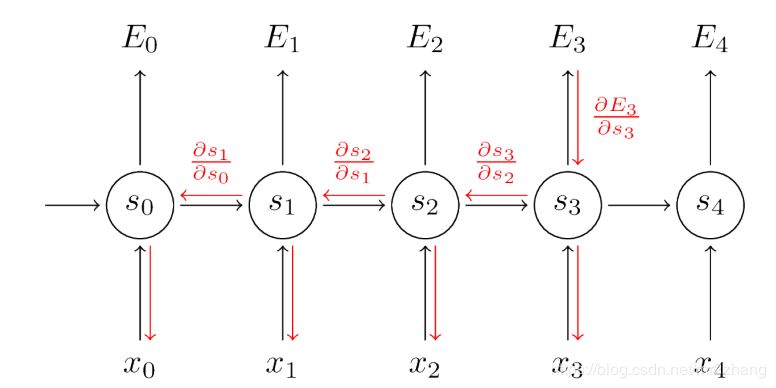
其實(shí)lstm可以解決RNN長(zhǎng)時(shí)依賴梯度消失的問題。
seq2seq
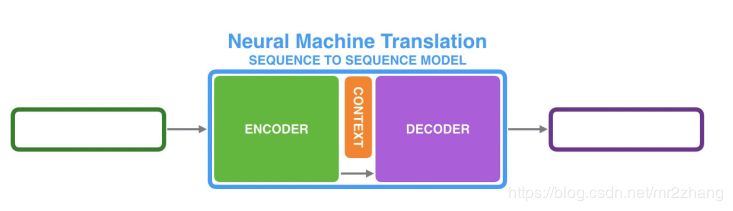
對(duì)于翻譯,我們不可能要求英語第一個(gè)詞一定對(duì)應(yīng)法語的第一個(gè)詞,不能要求長(zhǎng)度一樣,對(duì)于這樣一個(gè)rnn不能解決這一問題。我們使用兩個(gè)rnn拼接成seq2seq來解決。
我們可以用兩段RNN組成seq2seq模型
從而可以來做翻譯,摘要、問答和對(duì)話系統(tǒng)。
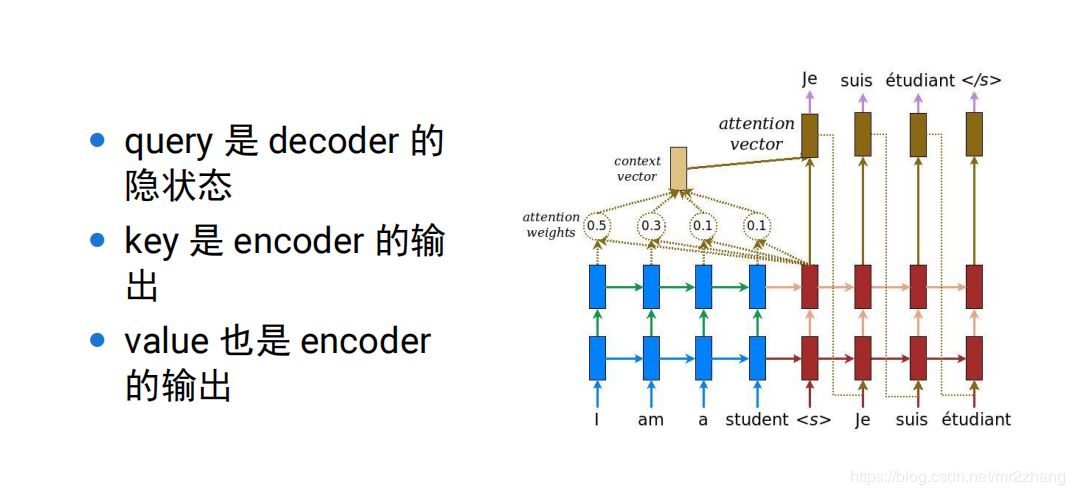
比如經(jīng)典的翻譯例子法語到英語的翻譯,由encoder編碼到語義空間和decoder根據(jù)語義空間解碼翻譯成一個(gè)個(gè)的英語句子。
encoder把要翻譯的句子,映射到了整個(gè)語義空間,decoder根據(jù)語義空間再逐一翻譯出來,但是句子長(zhǎng)度有時(shí)會(huì)截?cái)唷S幸粋€(gè)問題,我們需要一個(gè)固定長(zhǎng)度的context向量來編碼所有語義,這個(gè)是很困難的,要記住每一個(gè)細(xì)節(jié)是不可能的。用一個(gè)向量記住整個(gè)語義是很困難的。
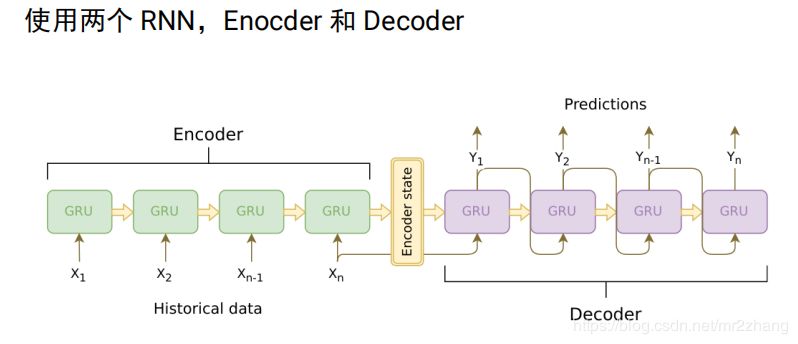
這時(shí)候我們引入了attention機(jī)制。
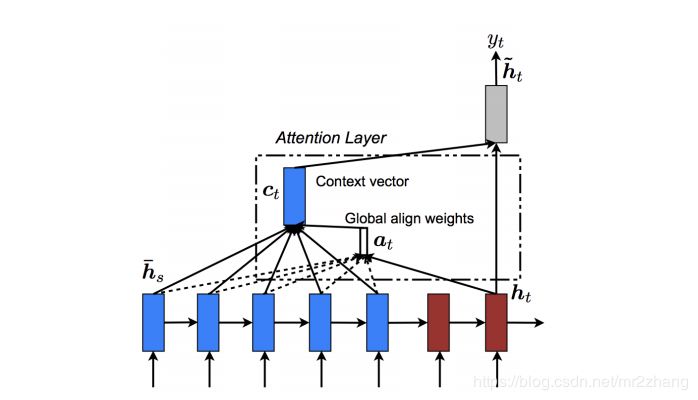
可以理解為context只記住了一個(gè)大概的提取信息,一種方法是做內(nèi)積,內(nèi)積大就關(guān)注大,這里可以理解為一種提取的方式,當(dāng)提取到相關(guān)內(nèi)容,再與具體的ecoder位置計(jì)算,得到更精細(xì)的內(nèi)容。
pay attention 做內(nèi)積。越大越相近 約重要,后續(xù)的attention、transformer都是對(duì)seq2seq的一個(gè)改進(jìn),通過這種可以解決word embbeing沒有上下文的一個(gè)問題。
加上attention機(jī)制,我們就取得了很大的成績(jī),但是仍然存在一個(gè)問題,順序依賴,如下圖:t依賴t-1,t-1依賴t-2,串行的,很難并行的計(jì)算,持續(xù)的依賴的關(guān)系,通常很慢,無法并行:
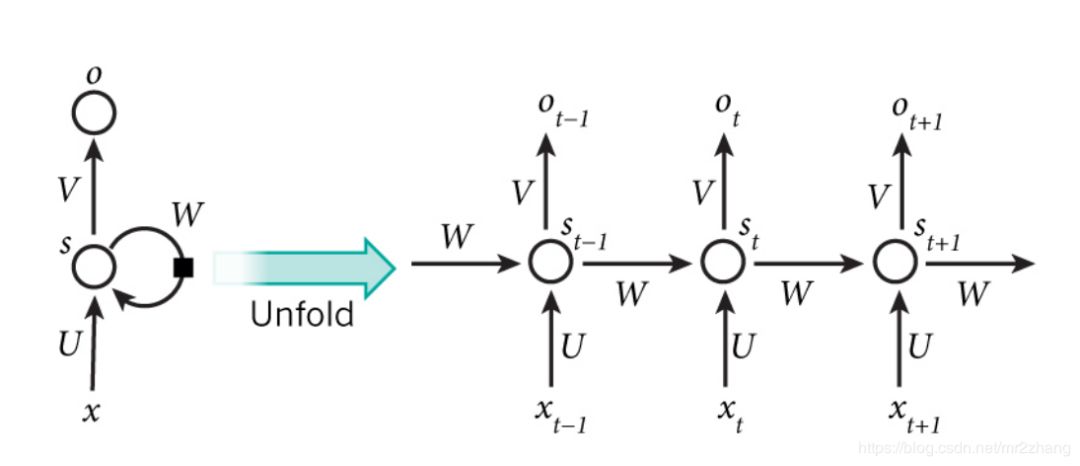
The animal didn’t cross the street because it was too tired.
The animal didn’t cross the street because it was too narrow.
存在單向信息流的問題,只看前文,我們很難猜測(cè)it指代的具體內(nèi)容,編碼的時(shí)候我們要看整個(gè)句子的上下文,只看前面或者只看后面是不行的。
RNN的兩個(gè)問題:
1、順序依賴,t依賴t-1時(shí)刻。
2、單向信息流(如例子中指代信息,不能確定)
3、需要一些比較多的監(jiān)督數(shù)據(jù),對(duì)于數(shù)據(jù)獲取成本很高的任務(wù),就比較困難,在實(shí)際中很難學(xué)到復(fù)雜的上下文關(guān)系
Contextual Word Embedding
要解決RNN的問題,就引入了contextual word embedding。
contextual word embedding:無監(jiān)督的上下文的表示,這種無監(jiān)督的學(xué)習(xí)是考慮上下文的,比如ELMo、OpenAI GPT、BERT都是上下文相關(guān)的詞的表示方法。
attention是需要兩個(gè)句子的,我們很多時(shí)候只有一個(gè)句子,這就需要self-attention。提取信息的時(shí)候、編碼時(shí)self-atenntion是自驅(qū)動(dòng)的,self-attention關(guān)注的詞的前后整個(gè)上下文。
self-attention最早是transformer的一部分。transformer是怎么解決這一問題的?
transformer:
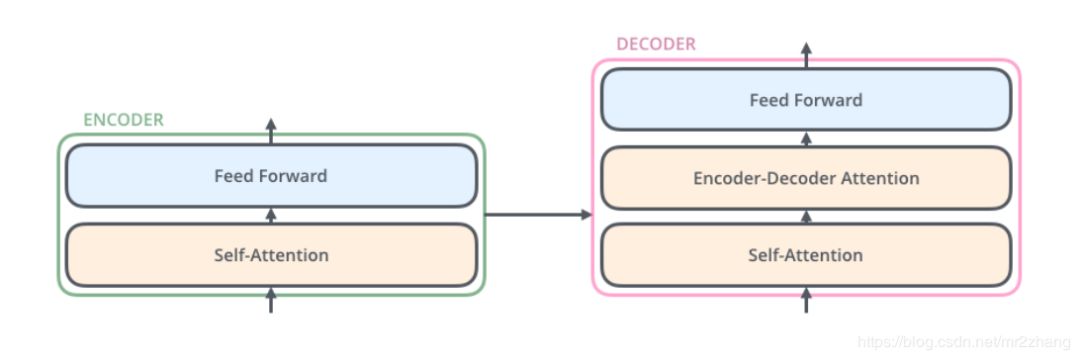
本質(zhì)也是一個(gè)encoder與decoder的過程,最起初時(shí)6個(gè)encoder與6個(gè)decoder堆疊起來,如果是LSTM的話,通常很難訓(xùn)練的很深,不能很好的并行
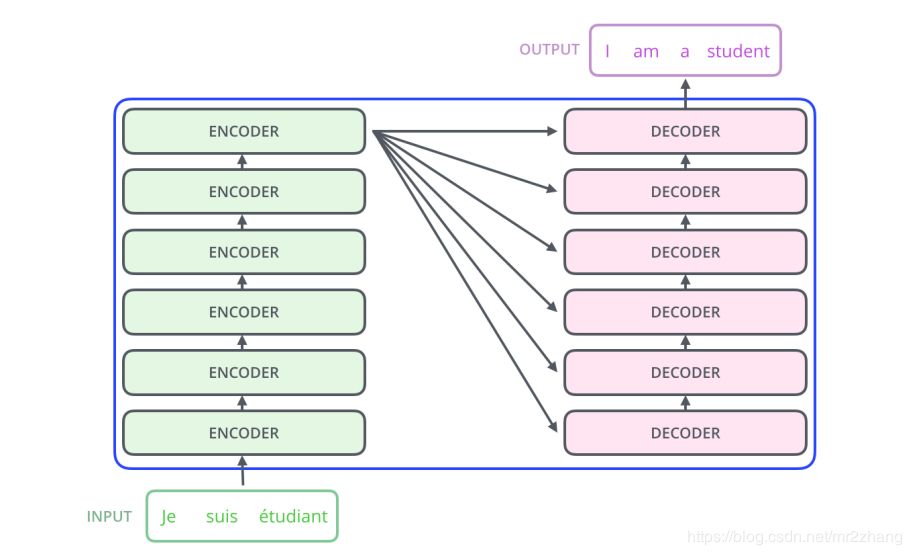
每一層結(jié)構(gòu)都是相同的,我們拿出一層進(jìn)行解析,每一層有self-attention和feed-forward,decoder還有普通的attention輸入來自encoder,和seq-2seq一樣,我在翻譯某一個(gè)詞的時(shí)候會(huì)考慮到encoder的輸出,來做一個(gè)普通的attention
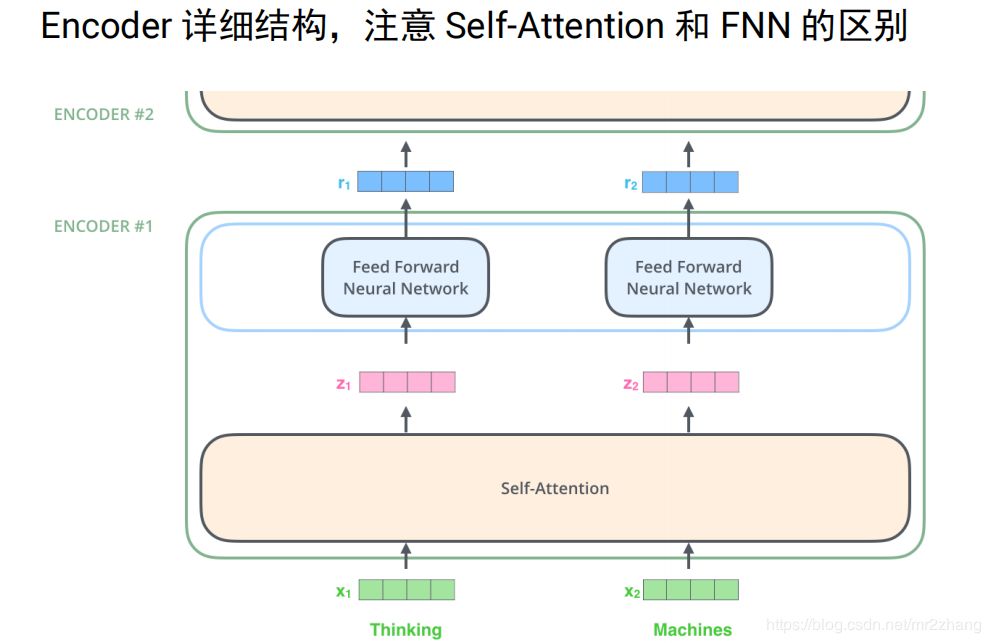
如下圖例子給定兩個(gè)詞 thinking和machies,首先通過word embedding把它變成向量,通過self-attention,把它變成一個(gè)向量,這里的sefl-attention時(shí)考慮上下文的。然后再接全連接層,計(jì)算z1的時(shí)候我要依賴x1、x2、x3整個(gè)序列的,才能算z1,z2也一樣,我算r1的時(shí)候時(shí)不需要z2的,只要有z1我就可以算r1.只要有z2就能算r2,這個(gè)是比較大的一個(gè)區(qū)別,這樣就可以并行計(jì)算。
我們來看看self-attention具體是怎么計(jì)算的
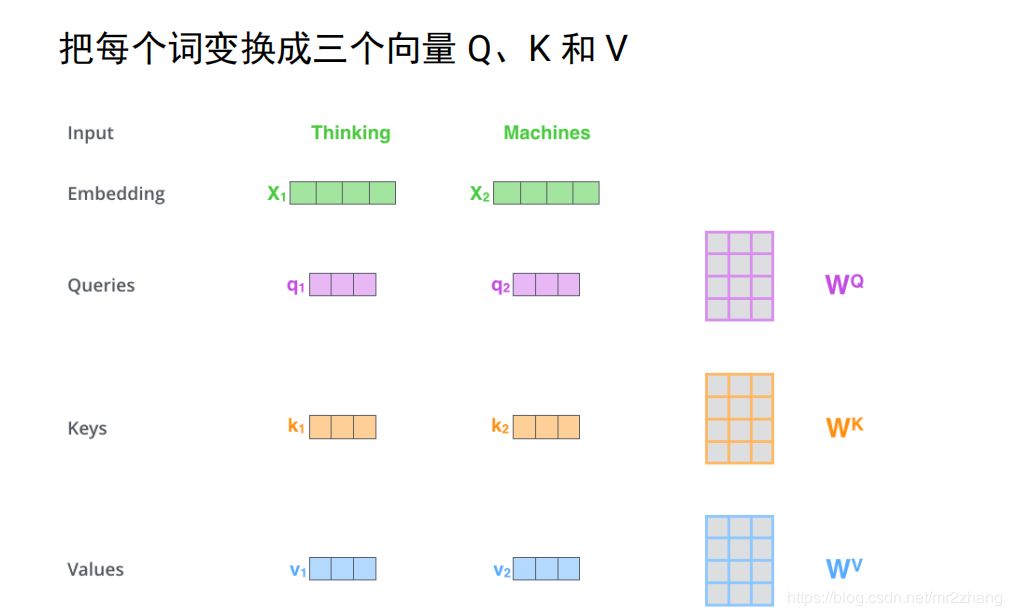
假設(shè)只有兩個(gè)詞,映射成長(zhǎng)度只有四的向量,接下來使用三個(gè)變換矩陣wqwkwv,分別把每個(gè)向量變換成三個(gè)向量 q1k1v1q2k2v2這里是與設(shè)映的向量相乘得到的
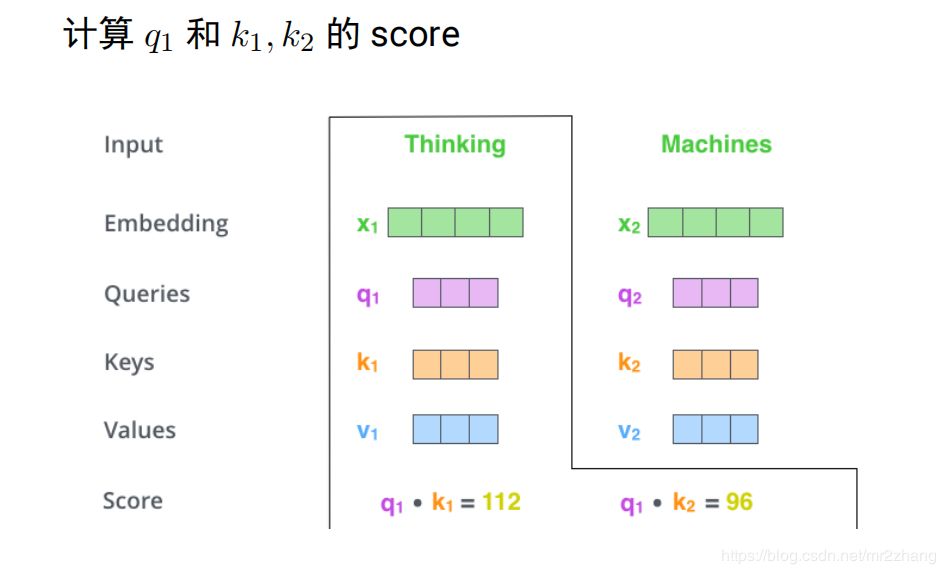
得到向量之后就可以進(jìn)行編碼了,考慮上下文,如上文提到的bank同時(shí)有多個(gè)語義,編碼這個(gè)詞的時(shí)候要考慮到其他的詞,具體的計(jì)算是q1k1做內(nèi)積 q2k2做內(nèi)積得到score,內(nèi)積越大,表示約相似,softmax進(jìn)行變成概率。花0.88的概率注意Thinking,0.12注意macheins這個(gè)詞
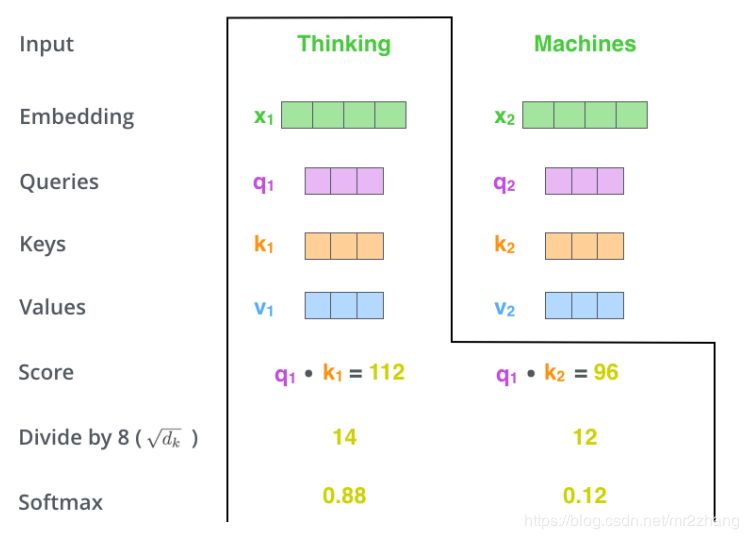
就可以計(jì)算z1了,z1=0.88v1+0.12z2z2的計(jì)算也是類似的。

q表示為了編碼自己去查詢其他的詞,k表示被查詢,v表示這個(gè)詞的真正語義,經(jīng)過變換就變成真正的包含上下文的信息,普通attention可以理解為self-attention的一個(gè)特例。
普通attention的對(duì)比:
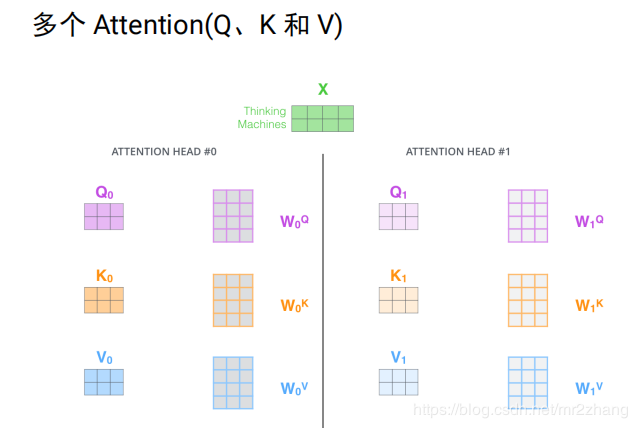
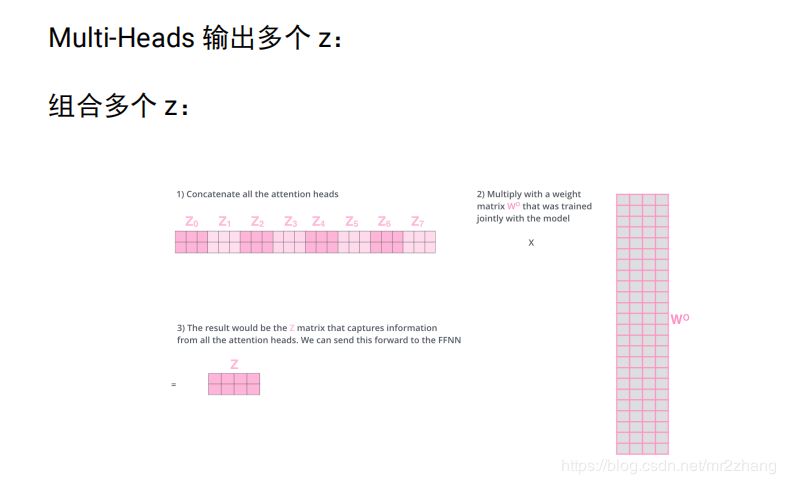
實(shí)際中是多個(gè)head, 即多個(gè)attention(多組qkv),通過訓(xùn)練學(xué)習(xí)出來的。不同attention關(guān)注不同的信息,指代消解 上下位關(guān)系,多個(gè)head,原始論文中有8個(gè),每個(gè)attention得到一個(gè)三維的矩陣
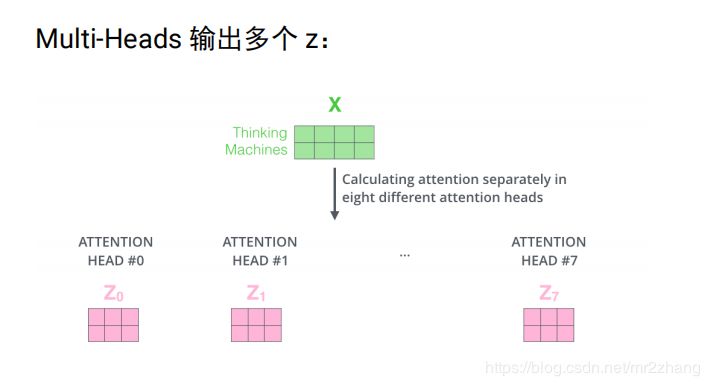
將8個(gè)3維的拼成24維,信息太多 經(jīng)過24 *4進(jìn)行壓縮成4維。
位置編碼:
北京 到 上海 的機(jī)票
上海 到 北京 的機(jī)票
self-attention是不考慮位置關(guān)系的,兩個(gè)句子中北京,初始映射是一樣的,由于上下文一樣,qkv也是一樣的,最終得到的向量也是一樣的。這樣一個(gè)句子中調(diào)換位置,其實(shí)attention的向量是一樣的。實(shí)際是不一樣的,一個(gè)是出發(fā)城市,一個(gè)是到達(dá)城市。
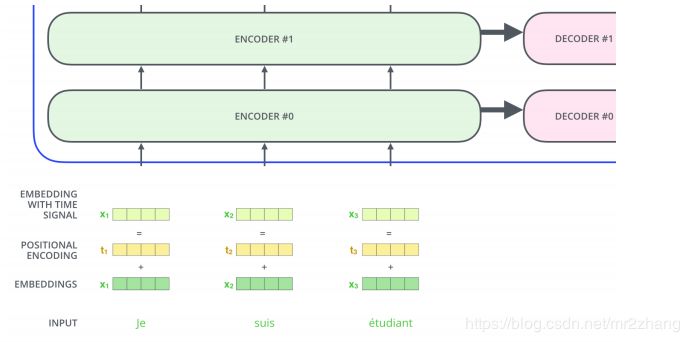
引入位置編碼,絕對(duì)位置編碼,每個(gè)位置一個(gè) Embedding,每個(gè)位置一個(gè)embedding,同樣句子,多了個(gè)詞 就又不一樣了,編碼就又不一樣了
北京到上海的機(jī)票 vs 你好,我要北京到上海的機(jī)票
tranformer原始論文使用相對(duì)位置編碼,后面的bert open gpt使用的是簡(jiǎn)單絕對(duì)位置編碼:
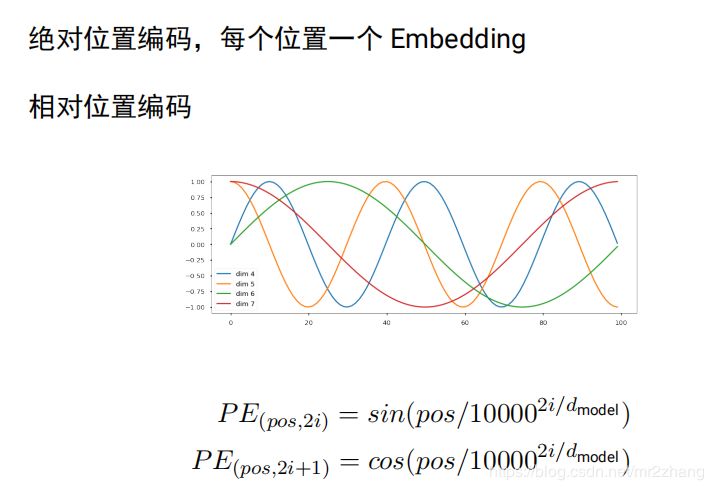
大家可以嘗試bert換一下相對(duì)位置會(huì)不會(huì)更好:
transformer中encoder的完整結(jié)構(gòu),加上了殘差連接和layerNorm
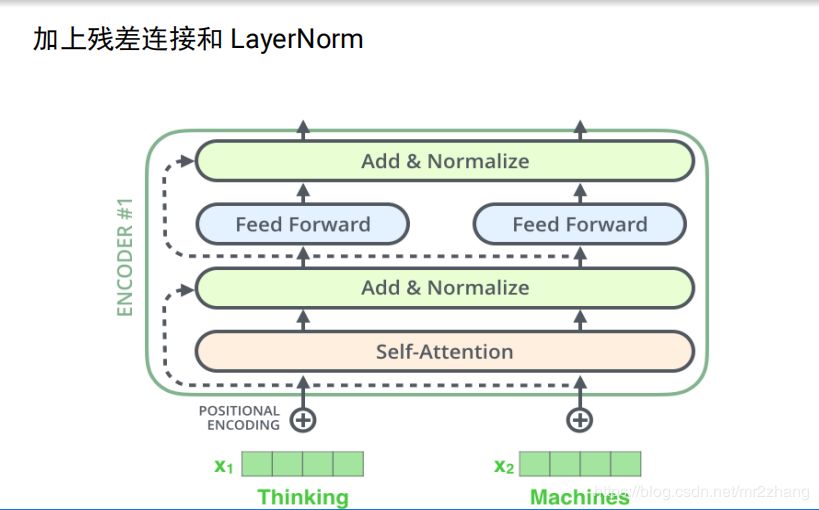
decoder加上了普通的attention,最后一刻的輸出,會(huì)輸入。
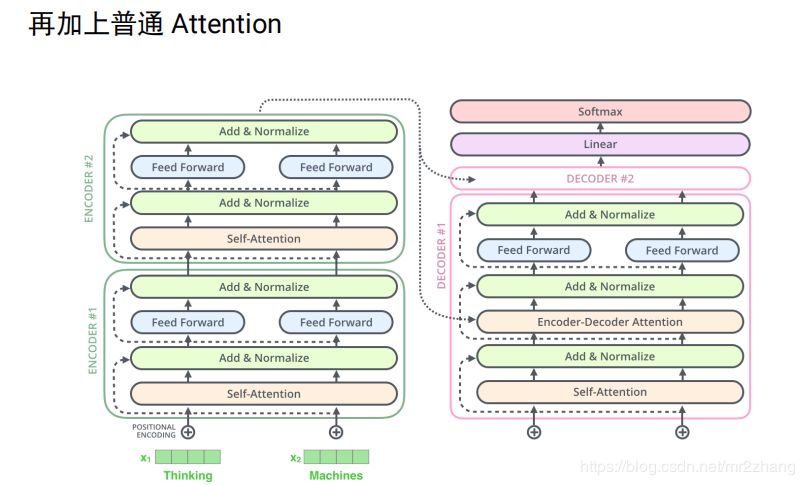
transformer的decoder不能利用未知的信息,即單向信息流問題。
transformer 解決的問題:
可以并行計(jì)算,訓(xùn)練的很深,到后來的open gpt可以到12層 bert的16、24層;單向信息流的問題:至少在encoder的時(shí)候考慮前面和后面的信息,所以可以取得很好的效果;transformer解決了普通word embedding 沒有上下文的問題,但是解決這個(gè)問題,需要大量的標(biāo)注信息樣本。
如何解決transformer的問題,就引入了elmo,elmo:無監(jiān)督的考慮上下文的學(xué)習(xí)。
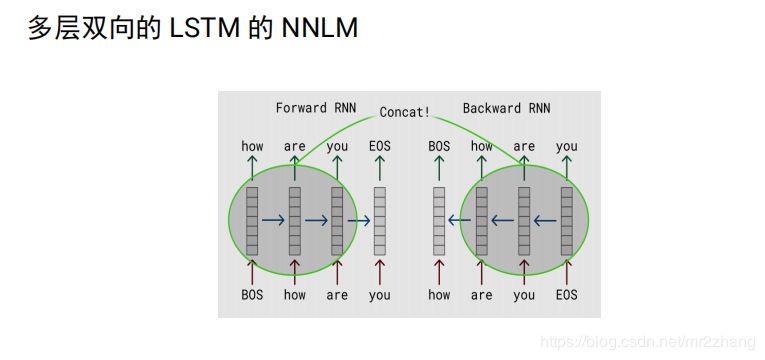
一個(gè)個(gè)的預(yù)測(cè)的語言模型:
雙向的lstm,每個(gè)向量2n,是一種特征提取的方法,考慮的上下文的,編碼完,就定住了,
elmo:將上下文當(dāng)作特征,但是無監(jiān)督的語料和我們真實(shí)的語料還是有區(qū)別的,不一定的符合我們特定的任務(wù),是一種雙向的特征提取。
openai gpt就做了一個(gè)改進(jìn),也是通過transformer學(xué)習(xí)出來一個(gè)語言模型,不是固定的,通過任務(wù) finetuning,用transfomer代替elmo的lstm。openai gpt其實(shí)就是缺少了encoder的transformer。當(dāng)然也沒了encoder與decoder之間的attention。
openAI gpt雖然可以進(jìn)行fine-tuning,但是有些特殊任務(wù)與pretraining輸入有出入,單個(gè)句子與兩個(gè)句子不一致的情況,很難解決,還有就是decoder只能看到前面的信息。
bert
bert從這幾方面做了改進(jìn):
Masked LM
NSP Multi-task Learning
Encoder again
bert為什么更好呢?
單向信息流的問題 ,只能看前面,不能看后面,其實(shí)預(yù)料里有后面的信息,只是訓(xùn)練語言模型任務(wù)特殊要求只能看后面的信息,這是最大的一個(gè)問題;
其次是pretrain 和finetuning 幾個(gè)句子不匹配。
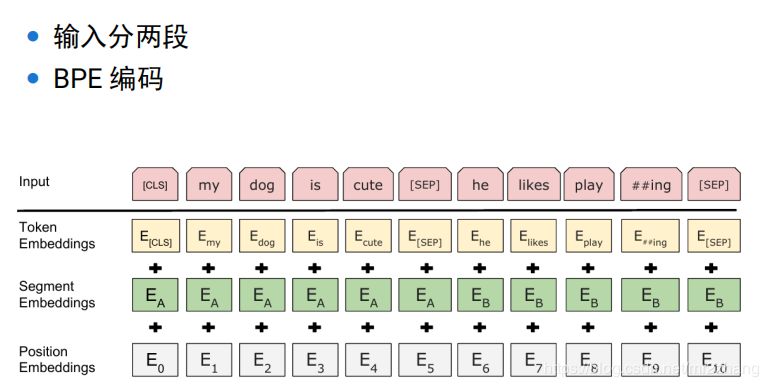
bert的輸入是兩個(gè)句子,分割符sep,cls表示開始,對(duì)輸入的兩個(gè)句子,使用位置編碼, segment embeding 根據(jù)這個(gè)可以知道 該詞屬于哪個(gè)句子,學(xué)習(xí)會(huì)更加簡(jiǎn)單。可以很清楚知道第一句子需要編碼什么信息,第二個(gè)句子可以編碼什么信息。
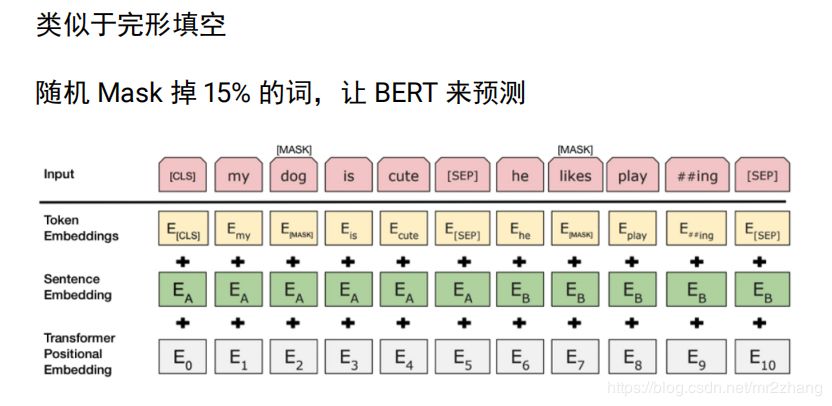
單向信息流的問題,換一個(gè)任務(wù)來處理這個(gè)問題
單向信息流問題:mask ml 有點(diǎn)類似與完形填空,根據(jù)上下文信息猜其中信息,計(jì)算出最大概率,隨機(jī)丟掉15%的詞來bert來進(jìn)行預(yù)測(cè),考慮前后雙向的信息,怎么搞兩個(gè)句子?
-50%概率抽連續(xù)句子 正樣本1
50%概率抽隨機(jī)句子 負(fù)樣本 0
這樣學(xué)習(xí)到兩個(gè)句子的關(guān)系,可以預(yù)測(cè)句子關(guān)系,在一些問答場(chǎng)景下很重要。
finetuning
單個(gè)句子的任務(wù),我們拿第一個(gè)cls向量,上面接一些全連接層,做一個(gè)分類,標(biāo)注的數(shù)據(jù) fine-tuningbert參數(shù)也包括全連接的一個(gè)參數(shù),為什么選擇第一個(gè)?
bert任務(wù)還是預(yù)測(cè)這個(gè)詞,預(yù)測(cè)的時(shí)候會(huì)參考其他的詞,如eat本身還是吃的語義,直接根據(jù)eat去分類,顯然是不可以的,cls沒有太多其他詞的語義,所以它的語義完全來自其他的語義 來自整個(gè)句子,編碼了整個(gè)句子的語義,用它做可以,當(dāng)然也可以得出所有結(jié)果進(jìn)行拼接后,再來進(jìn)行預(yù)測(cè)。
注意:
使用中文模型,不要使用多語言模型
max_seq_length 可以小一點(diǎn),提高效率
內(nèi)存不夠,需要調(diào)整 train_batch_size
有足夠多的領(lǐng)域數(shù)據(jù),可以嘗試 Pretraining
bert的實(shí)際應(yīng)用比較簡(jiǎn)單,不過多贅述內(nèi)容,推薦簡(jiǎn)單的demo樣例:
https://www.jianshu.com/p/3d0bb34c488a
-
人工智能
+關(guān)注
關(guān)注
1804文章
48677瀏覽量
246244 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8490瀏覽量
134030 -
自然語言處理
+關(guān)注
關(guān)注
1文章
628瀏覽量
14000
原文標(biāo)題:從One-hot, Word embedding到Transformer,一步步教你理解Bert
文章出處:【微信號(hào):rgznai100,微信公眾號(hào):rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄

外國(guó)牛人教你一步步快速打造首臺(tái)機(jī)器人(超詳細(xì))
CC2530一步步演示程序燒寫
菜鳥一步步入門SAM4S-XPLAINED--IAR開發(fā)環(huán)境
機(jī)器翻譯不可不知的Seq2Seq模型
一步步進(jìn)行調(diào)試GPRS模塊
stm32是如何一步步實(shí)現(xiàn)設(shè)置地址匹配接收喚醒中斷功能的
一文看懂NLP里的模型框架 Encoder-Decoder和Seq2Seq
基于一步步蒸餾(Distilling step-by-step)機(jī)制
PyTorch教程10.7之用于機(jī)器翻譯的編碼器-解碼器Seq2Seq

PyTorch教程-10.7. 用于機(jī)器翻譯的編碼器-解碼器 Seq2Seq






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論