") 生成對(duì)抗網(wǎng)絡(luò) vs 圖像水印,去除效果理想
生成對(duì)抗網(wǎng)絡(luò) vs 圖像水印,去除效果理想
當(dāng)前互聯(lián)網(wǎng)飛速發(fā)展,越來越多的公司、組織和個(gè)人都選擇在網(wǎng)上展示和分享圖像。為了保護(hù)圖像版權(quán),大家都會(huì)選擇在圖像上打上透明或者半透明的水印。隨著水印被廣泛地使用,針對(duì)水印的各種處理技術(shù)也在不斷發(fā)展,如何有效去除圖像上的水印引發(fā)了越來越多人的研究興趣。
今天的文章中,我們會(huì)介紹一種更為強(qiáng)大的水印去除器。這次我們借助生成對(duì)抗網(wǎng)絡(luò)來實(shí)現(xiàn),進(jìn)一步提升水印去除器的性能,從而達(dá)到更為理想的去除效果。
生成對(duì)抗網(wǎng)絡(luò)的前世今生
生成對(duì)抗網(wǎng)絡(luò)(Generative Adversarial Networks,GAN),是由Ian Goodfellow等人在2014年首次提出。一般來說,生成對(duì)抗網(wǎng)絡(luò)由兩部分組成:生成器(Generator)和判別器(Discriminator)。生成器通過接收輸入數(shù)據(jù),學(xué)習(xí)訓(xùn)練數(shù)據(jù)的分布來生成目標(biāo)數(shù)據(jù)。判別器通常是一個(gè)二分類模型,用來判別生成器生成數(shù)據(jù)的真假性。
我們可以將生成器和判別器看作互相對(duì)抗的雙方,生成器的目的是令生成的數(shù)據(jù)盡可能的真實(shí),讓判別器無法區(qū)分真假;而判別器的目的是盡可能地識(shí)別出生成器生成的數(shù)據(jù)。在生成對(duì)抗網(wǎng)絡(luò)的訓(xùn)練過程中,上面的對(duì)抗場(chǎng)景會(huì)持續(xù)進(jìn)行,生成器和判別器的能力都得到了不斷提升。訓(xùn)練的過程可以用如下公式表示:
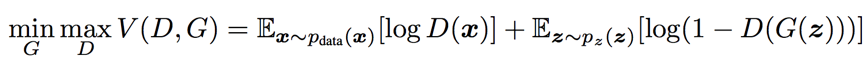
其中G和D分別表示生成器和判別器,x為真實(shí)數(shù)據(jù),z是生成器的輸入數(shù)據(jù)。最后訓(xùn)練結(jié)束我們就可以使用生成器來生成以假亂真的數(shù)據(jù)。一個(gè)直觀的生成對(duì)抗網(wǎng)絡(luò)結(jié)構(gòu)如下圖所示。
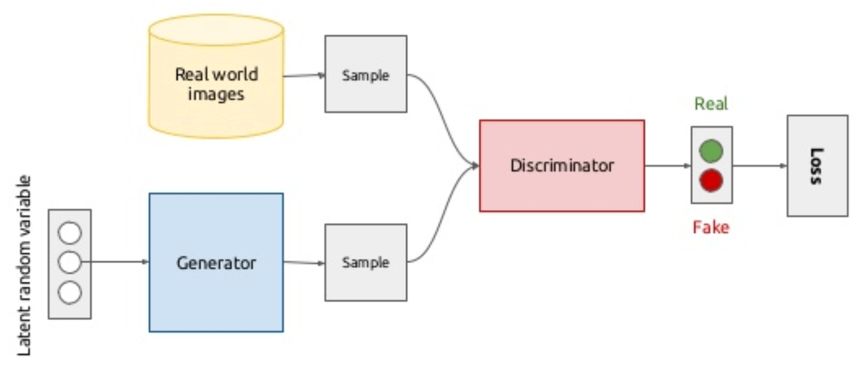
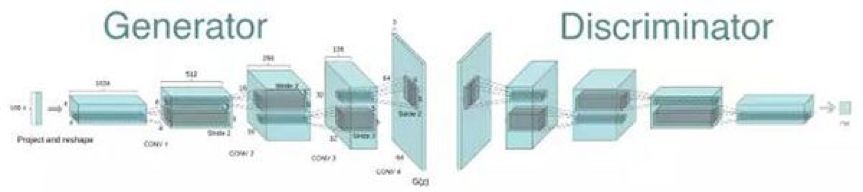
生成對(duì)抗網(wǎng)絡(luò)近些年被大量應(yīng)用于計(jì)算機(jī)視覺領(lǐng)域,根據(jù)具體應(yīng)用不同可以分為圖像生成和圖像轉(zhuǎn)換兩種類型的任務(wù)。圖像生成可以看成是一種學(xué)后聯(lián)想任務(wù),其中的代表是圖像自動(dòng)生成模型(DCGAN),網(wǎng)絡(luò)結(jié)構(gòu)如下圖所示。這類任務(wù)只給出我們希望生成的目標(biāo)圖像,此時(shí)生成器的輸入是服從某一分布的噪聲,通過和判別器的對(duì)抗訓(xùn)練,將其轉(zhuǎn)換成目標(biāo)圖像的數(shù)據(jù)分布。
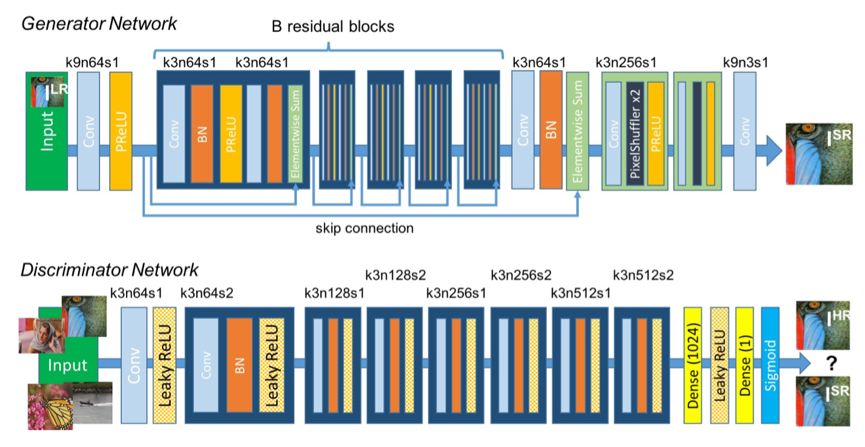
圖像轉(zhuǎn)換可以看成是一種目標(biāo)引導(dǎo)任務(wù),其中的代表是圖像超分辨率模型(SRGAN),SRGAN的網(wǎng)絡(luò)結(jié)構(gòu)如下圖所示。這類任務(wù)除了給出我們希望生成的目標(biāo)圖像外,還會(huì)給出轉(zhuǎn)換前的原始圖像,此時(shí)生成器的輸入變?yōu)樵紙D像,生成器在和判別器的對(duì)抗訓(xùn)練過程中還要同時(shí)保證生成的圖像和目標(biāo)圖像盡可能的相近。
生成對(duì)抗網(wǎng)絡(luò)的發(fā)展非常迅速,近些年出現(xiàn)了各式各樣GAN的變種,例如在訓(xùn)練上優(yōu)化的WGAN和LSGAN,通過對(duì)輸入添加條件限制來引導(dǎo)學(xué)習(xí)過程的Conditional GAN,圖像生成任務(wù)中的BigGAN和StyleGAN,圖像轉(zhuǎn)換任務(wù)中的Pixel2Pixel和CycleGAN等等。期待未來生成對(duì)抗網(wǎng)絡(luò)在計(jì)算機(jī)視覺領(lǐng)域給我們帶來更多的驚喜。
生成對(duì)抗網(wǎng)絡(luò)vs圖像水印
上一節(jié)中我們介紹了生成對(duì)抗網(wǎng)絡(luò)的核心思想和一些應(yīng)用,現(xiàn)在我們嘗試將生成對(duì)抗網(wǎng)絡(luò)用于圖像的水印去除。去水印的目的是將帶水印的圖像轉(zhuǎn)變?yōu)闊o水印的圖像,這本質(zhì)上也是一種圖像轉(zhuǎn)換任務(wù)。
因此生成器的輸入為帶水印的圖像,輸出為無水印的圖像;而判別器用于識(shí)別結(jié)果到底是原始真實(shí)的無水印圖像,還是經(jīng)過生成器生成的無水印圖像。通過兩者之間不斷的對(duì)抗訓(xùn)練,生成器生成的無水印圖像變得足夠“以假亂真”,從而達(dá)到理想的去水印效果。
在實(shí)際的實(shí)踐過程中,我們還做了一系列優(yōu)化改進(jìn)。下面我們分別介紹生成器和判別器的具體結(jié)構(gòu)以及訓(xùn)練細(xì)節(jié)。在生成器的選擇上,我們繼續(xù)使用U-net網(wǎng)絡(luò)結(jié)構(gòu),U-net通過在輸入和輸出之間添加跳躍連接,融合了低層級(jí)特征和高層級(jí)特征。與直接的編解碼器結(jié)構(gòu)相比,能夠保留更多的圖像背景信息,保證去除水印后的圖像的真實(shí)性。
在判別器方面,我們使用了基于區(qū)域判別的全卷積網(wǎng)絡(luò)。與傳統(tǒng)的判別器直接輸出整張圖像的真假結(jié)果不同,我們通過對(duì)圖像區(qū)域級(jí)別的判別,可以更好地對(duì)圖像上的無水印和有水印部分進(jìn)行區(qū)分。
此外,我們采用了Conditional GAN的思想,判別器在對(duì)原始真實(shí)的無水印圖像和生成器生成的無水印圖像進(jìn)行區(qū)分的時(shí)候會(huì)加入帶水印圖像的條件信息,從而進(jìn)一步提升生成器和判別器的學(xué)習(xí)性能。生成器和判別器的具體結(jié)構(gòu)和細(xì)節(jié)如下圖所示。
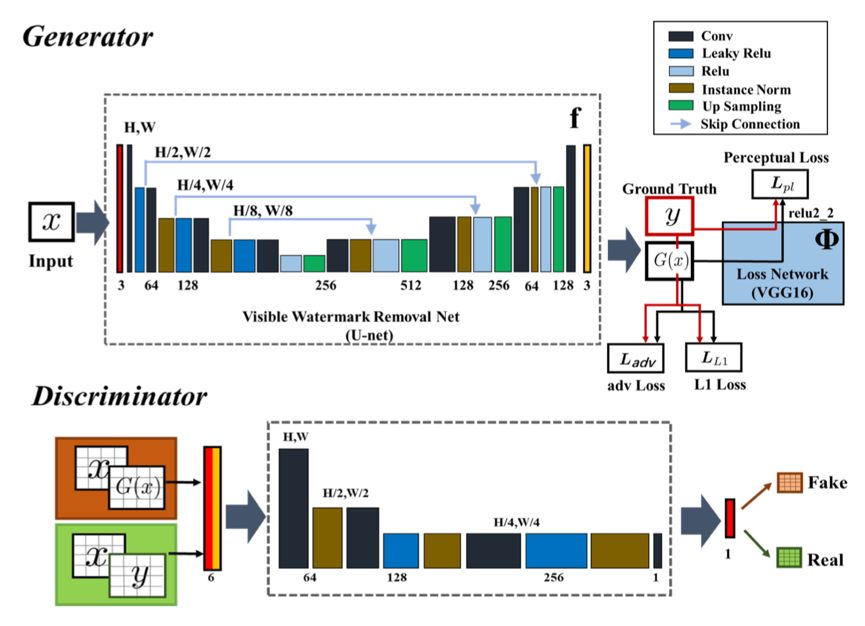
生成器生成的無水印圖像除了要令判別器分辨不了真假之外,還需要保證和真實(shí)的無水印圖像盡可能接近。為此我們組合一范數(shù)損失(L1 Loss)和感知損失(Perceptual Loss)作為內(nèi)容損失,在生成器和判別器對(duì)抗的過程中加入訓(xùn)練。最終的損失函數(shù)為
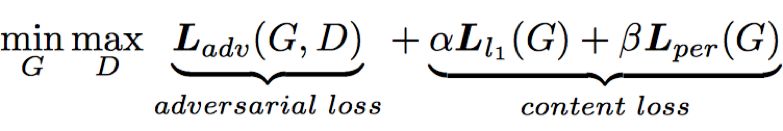
其中的條件對(duì)抗損失為
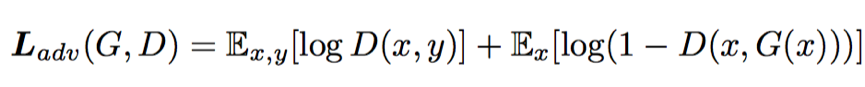
最終我們使用生成器作為水印去除器實(shí)現(xiàn)圖像上的水印去除。為了對(duì)比和單一全卷積網(wǎng)絡(luò)實(shí)現(xiàn)的水印去除器的效果,我們可視化了一些去水印結(jié)果,左列是輸入的水印區(qū)域,中間列是單一全卷積網(wǎng)絡(luò)得到的無水印區(qū)域,右列是生成對(duì)抗網(wǎng)絡(luò)得到的無水印區(qū)域。從可視化的結(jié)果可以看出,經(jīng)過對(duì)抗訓(xùn)練后的生成器對(duì)水印的去除效果更優(yōu)。
寫在最后
圖像水印去除問題吸引了越來越多人的研究興趣,本篇文章介紹了如何利用生成對(duì)抗網(wǎng)絡(luò)來實(shí)現(xiàn)水印自動(dòng)去除。去水印研究的目的是為了驗(yàn)證水印的魯棒性,更好地提升水印的反去除能力。如何設(shè)計(jì)一種AI去不掉的水印是一個(gè)極具挑戰(zhàn)的問題,接下來我們會(huì)在這方面做一些嘗試,希望能夠?yàn)榘鏅?quán)保護(hù)盡一份力。
-
水印
+關(guān)注
關(guān)注
0文章
26瀏覽量
11716 -
GaN
+關(guān)注
關(guān)注
19文章
2174瀏覽量
76138
原文標(biāo)題:基于GAN的圖像水印去除器,效果堪比PS高手
文章出處:【微信號(hào):rgznai100,微信公眾號(hào):rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
如何使用離線工具od SPSDK生成完整圖像?
使用OpenVINO GenAI和LoRA適配器進(jìn)行圖像生成
#新年新氣象,大家新年快樂!#AIGC入門及鴻蒙入門
AIGC入門及鴻蒙入門
借助谷歌Gemini和Imagen模型生成高質(zhì)量圖像

用TMS2812控制ADS1298進(jìn)行肌電采集,將相同的程序燒寫到flash中后再進(jìn)行采集時(shí)效果不理想,為什么?
Freepik攜手Magnific AI推出AI圖像生成器
請(qǐng)問LM311能準(zhǔn)確的交截生成對(duì)應(yīng)的PWM波形嗎?
OpenAI承認(rèn)正研發(fā)ChatGPT文本水印
如何在Tensorflow中實(shí)現(xiàn)反卷積
生成對(duì)抗網(wǎng)絡(luò)(GANs)的原理與應(yīng)用案例
人工神經(jīng)網(wǎng)絡(luò)模型的分類有哪些
卷積神經(jīng)網(wǎng)絡(luò)在圖像識(shí)別中的應(yīng)用
神經(jīng)網(wǎng)絡(luò)架構(gòu)有哪些
鴻蒙ArkTS聲明式開發(fā):跨平臺(tái)支持列表【圖像效果】 通用屬性





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論