") 不會PS還想做圖?微軟、京東出黑科技:說一句話就能生成圖片!
不會PS還想做圖?微軟、京東出黑科技:說一句話就能生成圖片!

微軟和京東最近出了一個黑科技:說一句話就能生成圖片!在這項研究中,研究人員提出了一種新的機器學(xué)習(xí)框架——ObjGAN,可以通過關(guān)注文本描述中最相關(guān)的單詞和預(yù)先生成的語義布局(semantic layout)來合成顯著對象。
不會PS還想做圖?可以的!
近期,由紐約州立大學(xué)奧爾巴尼分校、微軟研究院和京東AI研究院合作的一篇文章就可以實現(xiàn)這個需求:只需要輸入一句話,就可以生成圖片!
輸入:
![]()
輸出:
在這項研究中,研究人員提出了一種新的機器學(xué)習(xí)框架——ObjGAN,可以通過關(guān)注文本描述中最相關(guān)的單詞和預(yù)先生成的語義布局(semantic layout)來合成顯著對象。
此外,他們還提出了一種新的基于Fast R-CNN的關(guān)于對象(object-wise)鑒別器,用來提供關(guān)于合成對象是否與文本描述和預(yù)先生成的布局匹配的對象識別信號。

論文地址:
https://www.microsoft.com/en-us/research/uploads/prod/2019/06/1902.10740.pdf
這項工作已經(jīng)發(fā)表在計算機視覺和模式識別領(lǐng)域頂會CVPR 2019。
這篇論文的合著作者表示,與之前最先進(jìn)的技術(shù)相比,他們的方法大大提高了圖像質(zhì)量:
我們的生成器能夠利用細(xì)粒度的單詞和對象級(object-level)信息逐步細(xì)化合成圖像。
大量的實驗證明了ObjGAN在復(fù)雜場景的文本到圖像生成方面的有效性和泛化能力。
一句話秒生成圖片!
根據(jù)文本的描述來生成圖像,可以說是機器學(xué)習(xí)中一項非常重要的任務(wù)。
這項任務(wù)需要處理自然語言描述中模糊和不完整的信息,并且還需要跨視覺和語言模式來進(jìn)行學(xué)習(xí)。
自從GAN提出后,這項任務(wù)在結(jié)果上取得了較好的成績,但是目前這些基于GAN的方法有一個缺點:
大多數(shù)圖像合成方法都是基于全局句子向量來合成圖像,而全局句子向量可能會丟失單詞級別(word-level)的重要細(xì)粒度信息,從而阻礙高質(zhì)量圖像的生成。
大多數(shù)方法都沒有在圖像中明確地建模對象及其關(guān)系,因此難以生成復(fù)雜的場景。
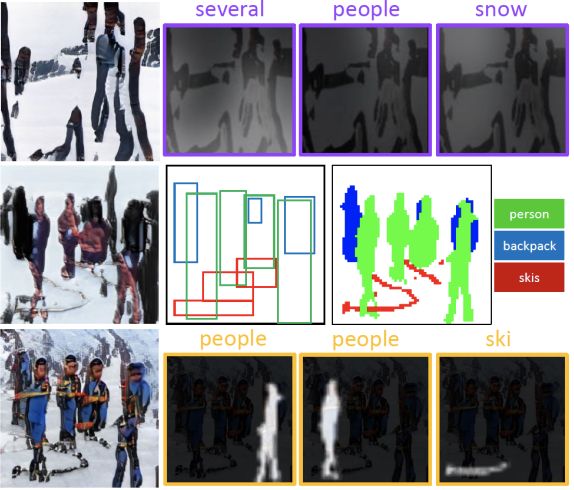
圖1 頂部:AttnGAN及其網(wǎng)格注意力可視化;中部:修改前人工作的結(jié)果;底部:ObjGAN及其對象驅(qū)動的注意力可視化
舉個例子,如果要根據(jù)“幾個人穿滑雪服的人在雪地里”這句話生成一張圖片,那么需要對不同的對象(人、滑雪服)及其交互(穿滑雪服的人)進(jìn)行建模,還需要填充缺失的信息(例如背景中的巖石)。
圖1的第一行是由AttnGAN生成的圖像,雖然圖像中包含了人和雪的紋理,但是人的形狀是扭曲的,圖像布局在語義上是沒有意義的。
為了解決這個問題,首先從文本構(gòu)造語義布局,然后通過反卷積圖像生成器合成圖像。
從圖1的中間一行可知,雖然細(xì)粒度的word/objectlevel信息仍然沒有很好的用于生成。因此,合成的圖像沒有包含足夠的細(xì)節(jié)讓它們看起來更加真實。
本研究的目標(biāo)就是生成具有語義意義(semantically meaningful)的布局和現(xiàn)實對象的高質(zhì)量復(fù)雜圖像。
為此,研究人員提出了一種新穎的對象驅(qū)動的注意力生成對抗網(wǎng)絡(luò)(Object-driven Attentive Generative Adversarial Networks,Obj-GAN),該網(wǎng)絡(luò)能夠有效地捕獲和利用細(xì)粒度的word/objectlevel信息進(jìn)行文本到圖像的合成。
ObjGAN由一對兒對象驅(qū)動的注意力圖像生成器和object-wise判別器組成,并采用了一種新的對象驅(qū)動注意機制。
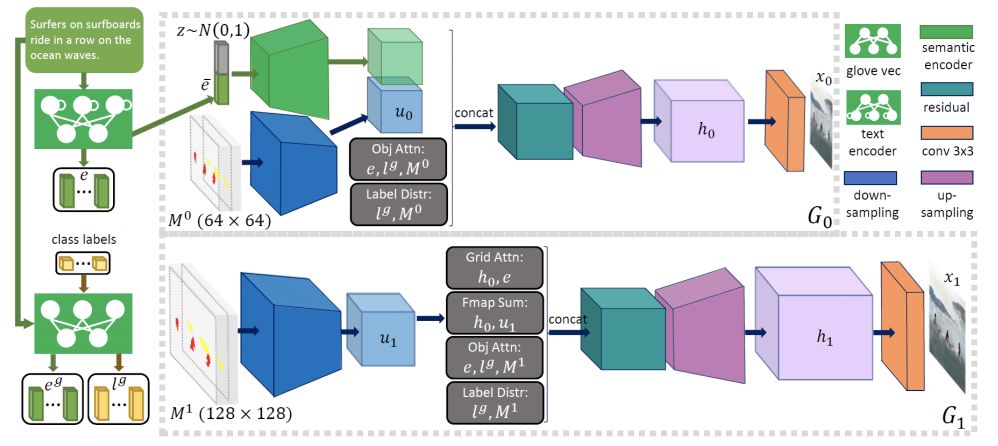
圖2 對象驅(qū)動的注意力圖像生成器
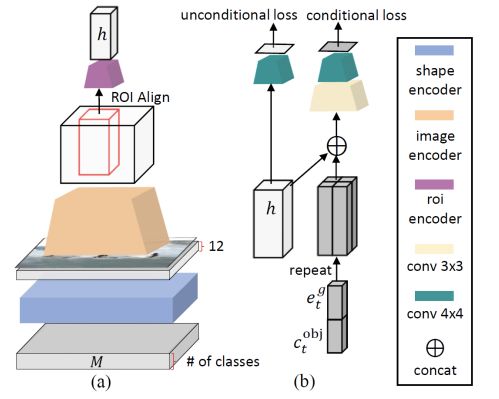
圖3 Object-wise判別器
該圖像生成器以文本描述和預(yù)先生成的語義布局為輸入,通過多階段由粗到精的過程合成高分辨率圖像。
在每個階段,生成器通過關(guān)注與該邊界框中的對象最相關(guān)的單詞來合成邊界框內(nèi)的圖像區(qū)域,如圖1的底部行所示。
更具體地說,它使用一個新的對象驅(qū)動的注意層,使用類標(biāo)簽查詢句子中的單詞,形成一個單詞上下文向量,如圖4所示,然后根據(jù)類標(biāo)簽和單詞上下文向量條件合成圖像區(qū)域。
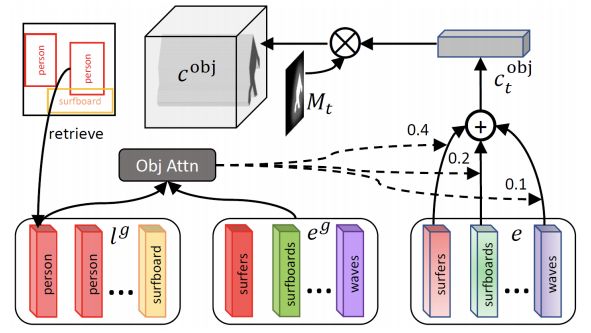
圖4 對象驅(qū)動的注意力
Object-wise判別器會對每個邊界框進(jìn)行檢查,確保生成的對象確實與預(yù)先生成的語義布局是匹配的。
同時,為了有效地計算所有邊界框的識別損失,object-wise判別器基于一個Fast-RNN,并且每個邊界框都有一個二院交叉熵?fù)p失。
實驗結(jié)果
研究人員在實驗過程中采用的數(shù)據(jù)集是COCO數(shù)據(jù)集。它包含80個對象類,其中每個圖像與對象注釋(即,邊界框和形狀)和5個文本描述相關(guān)聯(lián)。
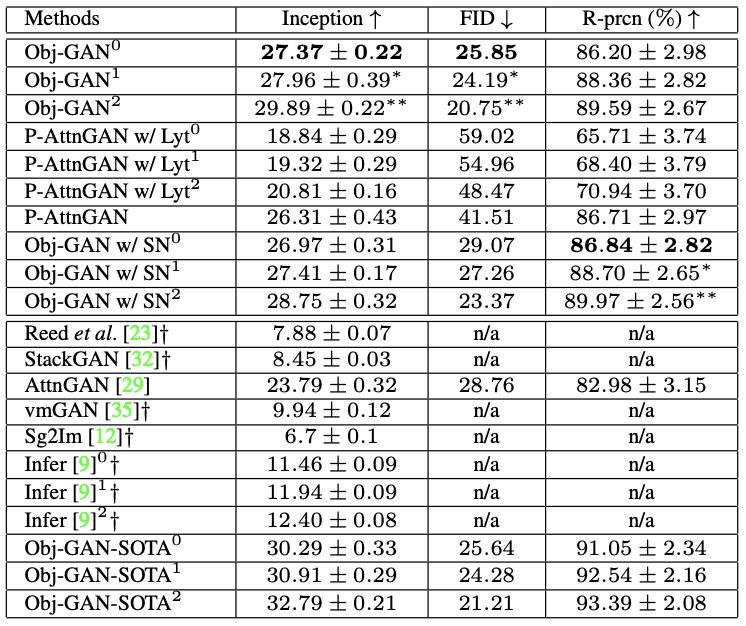
在評價指標(biāo)方面,研究人員采用 Inception score(IS)和Frechet Inception distance(FID) score作為定量評價指標(biāo)。結(jié)果如下表所示:
表1
接下來,是采用不同方法生成圖像的結(jié)果與實際圖像的對比結(jié)果:
圖5 整體定性比較。所有圖像都是在不使用任何ground-truth的情況下生成的。
圖6 與P-AttnGAN w/ Lyt進(jìn)行定性比較
圖7 與P-AttnGAN的定性比較。 每個方法的注意力圖顯示在生成的圖像旁邊。
-
微軟
+關(guān)注
關(guān)注
4文章
6685瀏覽量
105742 -
京東方
+關(guān)注
關(guān)注
25文章
1542瀏覽量
61052
原文標(biāo)題:CVPR 2019:微軟最新提出ObjGAN,輸入一句話秒生成圖片
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄

CYW55513是否支持linux4.4?
使用FX3 SDK發(fā)布源代碼是否違反許可?
樹莓派遇上ChatGPT,魔法熱線就此誕生!

想讀ADS1248寄存器寫入的值,是否必須改變SPI工作模式?
使用ADS1220設(shè)計一款電路用來采集一個電阻橋式傳感器,使用內(nèi)部的2.048V基準(zhǔn)作為基準(zhǔn)電壓?
福田汽車2025合作伙伴大會有哪些看點
晶科能源N型TOPCon技術(shù)為什么能領(lǐng)跑行業(yè)

開關(guān)電源布線 一句話:要運行最穩(wěn)定、波形最漂亮、電磁兼容性最好

求助,關(guān)于TLE2141的供電問題求解
想把差分信號轉(zhuǎn)為單端信號,不是音頻信號,OPA365是否還可以使用呢?
知網(wǎng)狀告AI搜索:搜到我家論文題目和摘要,你侵權(quán)了!





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論