 谷歌街景數據建立車禍預測新模型
谷歌街景數據建立車禍預測新模型
預測是機器學習算法最重要的一個研究方向。眾多保險公司利用機器學習算法為他們的客戶建立預測模型。其中,車禍預測模型是眾多模型里面最難建立的。
車禍發生的影響因素多種多樣,變化多端,著實讓人摸不著頭腦。
與其他商品不同的是,車禍保單的最終成本在初始銷售時是未知的。因此,建立一個合理的定價機制是非常具有挑戰的。有些保險公司嘗試使用統計方法來解決這一問題:預測每個客戶的未來風險。
例如,非常經典的汽車保險。大部分的保險公司確定的保險風險因素有司機的年齡、他的汽車配置相關以及汽車發生事故的歷史情況。這也是為什么保險公司會在成交汽車保險之前需要客戶提供的詳細信息的原因。
波蘭華沙大學經濟科學系的Kinga Kita-Wojciechowska和斯坦福大學生物工程系的?ukasz Kidziński利用谷歌Google街景收集相對應的房屋圖像,通過標釋房屋的特征:例如年齡、類型以及其它條件。然后與目前最先進的保險風險模型相比,最后發現用谷歌街景數據建立的模型,能夠有效地改進了汽車事故風險預測。
作者通過對谷歌街景數據的研究,發現下列結論?
房子的特征與居民的發生車禍風險相關,
與谷歌街景的其他研究用途相比,此模型數據特征來自于地址,并不是按照郵政編碼或地區進行匯總,可能存在更為精細的劃分;
從地址中提取的數據(房屋的圖像)可用于保險和其他行業;
現代數據收集和科技技術允許對個人數據進行前所未有的利用,可能會超過立法的發展速度,并增加個人隱私威脅。
建模數據收集方法與特點
保險公司之前進行的風險建模和定價,通常只使用郵政編碼這一特征。然而匯總到郵政編碼的索賠數據仍然太不穩定,所以還需要進一步地調整。
另一方面,對于一些“外人”來說,保險公司客戶的信息數據很難獲得。本文使用的谷歌街景數據可以從來自Google街景的公開圖像信息中提取出來。
圖1.位于同一郵政編碼中不同房屋的示例,根據當前保險公司的模型,這些房屋的居民具有相同的預期索賠頻率。
此數據集包含20,000條記錄的汽車保險數據集,數據來源于2012年1月至2015年12月期間收集到在波蘭的保險投資組合的隨機樣本。
其中每項記錄均涵蓋汽車發動機第三方責任(MTPL)保險單的特點,包括投保人的地址、風險敞口(定義為一小部分有效年份在2013-2015年期間的保單)以及2013-2015年間發生的財產損壞索賠的統計數量。保險公司還提供了這些保單的財產損失索賠的預期頻率,是根據他們目前最好的風險模型進行估計的,是根據客戶的郵政編碼進行分區的。

圖2.使用注釋功能將為數據庫中提供的地址,匹配收集谷歌衛星視圖和谷歌街景圖像。
對圖像中可見的房屋中以下特征作了說明:居民的年齡、狀況、財富以及鄰近地區其他建筑物的類型。根據Fleiss’kappa(屬性型測量分析)統計數據結果表明,它們之間大多數是一致穩健的。
繼續注釋剩余的19,371個地址(還從本研究的范圍中刪除了129個地址,因為它們要么是另外區域的,要么是Google地圖找不到的),剩余的都將得到了一組單獨的、隨機選擇的地址。
研究者比較了收集到的注釋的分布情況,并在最后對四個注釋器進行了小的修正,以匹配平均值和標準差。
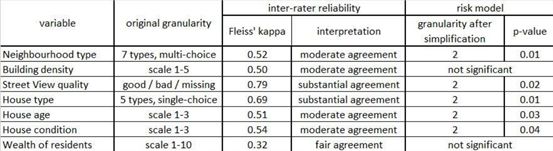
表1。在進行了必要的簡化后,風險模型中對7個新創建的變量進行了統計
建模過程
接下來,估計一個廣義線性模型(GLM)來研究新創建的變量對于風險預測的重要性。
假設索賠的概率模型如下:
頻率為f,定義為索賠次數除以風險敞口:
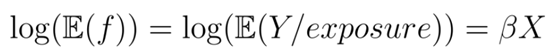
其中,MTPL保險中的一些財產損失索賠是服從泊松分布的,X是自變量的向量,也是系數的向量。
為了對方法所帶來的增加值進行評價,引入了三個模型:
模型A(空模型),其中向量為
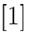
模型B(一流保險商模型):其中向量為
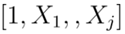
模型C(研究者使用的模型):其中向量為
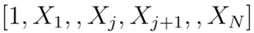
保險人為數據集中的每條記錄提供了模型B的實現。
該模型是在一個更大的未對外披露數據集上進行估計的,包含j個預測變量(駕駛員特征、車輛特征、索賠歷史、地理區域等)。
利用GLMs的特性,可以將模型C分解為兩個部分:一個對應于模型B,另一個則包含新變量。
因此,模型C為:
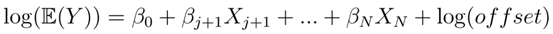
這些系數的值是否為非零,將表明研究者構造的變量為模型提供了額外的預測能力。在本研究中新創建的七個變量中,有五個對于預測財產損壞MTPL索賠頻率模型具有重要意義,而在最好的保險公司模型中使用的許多其它評級變量都是重要的(表1)。
通過觀察a、B、C模型的基尼系數的顯著變異性,特別是對于模型A(只包含截距且沒有選擇其他變量的空模型)在20次重采樣試驗中,其變化范圍為20 ~ 38%。將其解釋為證據,即所提供的數據集非常小(20,000條記錄),用于構建MTPL保險中的罕見事件,如財產損失索賠(平均頻率為5%)。
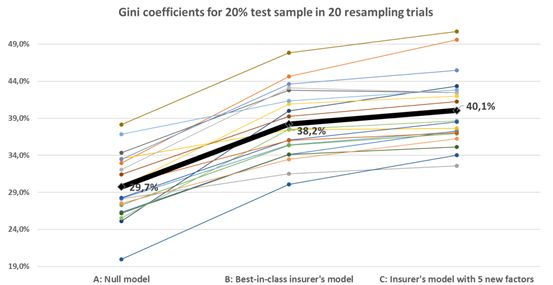
圖3.在20個自舉試驗中獲得的20%的檢驗樣本上的基尼系數(A),從零模型(A)到最好的保險公司的模型(B)和研究者新建立的變量模型(C)。
盡管數據的波動性很大,但將五個簡單變量加入到保險公司的模型中,在20次重新采樣試驗中的18次中嘗試,提高了它的性能,并提高了基尼系數的平均水平。提高系數接近2個百分點(從38.2%到40.1%)。
通常保險公司的模型會運用更大的數據集,并包含了廣泛的變量選擇(例如駕駛員特征、汽車特征、索賠歷史和基于客戶郵政編碼的地理區域),將基尼系數與空模型從0~30%提高到0~38%,提高了8個百分點(見圖3)。
創新之處
通常保險公司的預測模型都是以常規的特征進行預測的,比如駕駛車輛習慣,索賠歷史和客戶財富級別等特征。
但是文中的模型使用了全新的谷歌街景地圖的特征,比如街景地圖中房屋所在周圍環境,所在區域的密度,街景的質量和房屋類型年限等特征,評測結果也是比較令人欣慰,三個模型的基尼系數變動范圍在20%—38%之間,我們能從圖3中看見,經過20次的重采樣實驗得到的結果:具有街景新特征的模型比使用原有的優秀傳統模型還要高出接近2個百分點。
當然由于數據樣本量比較少,大概只有2萬條左右,所以這也在一定程度上影響了基尼系數的提升。但是這在預測模型的研究方向中,給了我們一個新的思路,原來街景地圖的特征會比傳統的特征更加有效。當然未來肯定還會有更加有效的特征出現,來幫助我們提升預測準確度。
總結
從一張房子的圖像中可見的特征預測發生車禍的風險,而且獨立于經常使用的變量,如年齡或郵政編碼。
這一發現邁出了一大步。它不僅提供了更為精確的風險預測模型,而且還說明了社會科學的一種新方法。
在這種方法中,真實世界中的細粒度數據可以經過大規模收集后進行分析。從保險公司的實際情況來看,給出的實驗結果是顯著的。研究者使用的模型中的5個變量包含了來自不完全注釋的一些偏差,與保險公司在其最佳風險模型中已經使用的眾多變量帶來的8個百分點的改進相比,基尼系數提高了近2個百分點。
保險行業可能很快就會被銀行效仿,因為保險風險模型與信用風險之間存在著已被證明的相關性。從谷歌街景(GoogleStreetView)中提取有價值信息的方法本身,不僅為金融業提供了各種機會。
此方法和深層次的學習技術可以使它在一個大規模自動化的模型中進行。同時,這種做法引起了人們對存儲在公開可用的Google街景、Microsoft Bing Streetside、Mapillary或類似的私有數據集中的數據隱私的擔憂。
-
谷歌
+關注
關注
27文章
6225瀏覽量
107600 -
機器學習
+關注
關注
66文章
8493瀏覽量
134147
原文標題:斯坦福最新研究:看圖“猜車禍”,用谷歌街景數據建立車禍預測新模型
文章出處:【微信號:BigDataDigest,微信公眾號:大數據文摘】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
預測性維護實戰:如何通過數據模型實現故障預警?






 工商網監
工商網監
評論