 PAKDD 2019 AutoML挑戰賽結果出爐:國內團隊DeepBlueAI斬獲第一名
PAKDD 2019 AutoML挑戰賽結果出爐:國內團隊DeepBlueAI斬獲第一名

近日,數據挖掘領域頂會PAKDD的AutoML挑戰賽結果出爐,DeepBlueAI、微軟&北航、清華大學等團隊斬獲前三名。本文帶來冠軍團隊解決方案的技術分享。
PAKDD 2019 AutoML挑戰賽結果出爐:國內團隊 DeepBlueAI 斬獲第一名,微軟亞洲研究院&北航組成的ML Intelligence團隊獲得第二名,清華大學Meta_Learners團隊獲得第三。
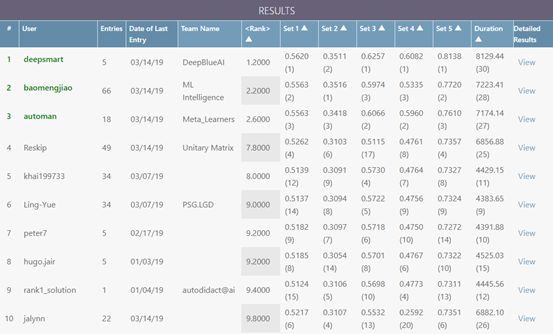
Feedback phase 排行榜
PAKDD 全稱亞太地區知識發現與數據挖掘國際會議(Pacific Asia Knowledge Discovery and Data Mining),是亞太地區數據挖掘領域的頂級國際會議。該會議在全球數據挖掘領域享有盛譽,一直受到業內各國科學家的高度重視和廣泛認可。
PAKDD 2019 第 4 屆自動機器學習挑戰賽(AutoML Challenge)的主題是“AutoML for Lifelong Machine Learning”,要求參賽選手創建一個自動預測模型(沒有任何人為干預),并在一個終身機器學習(Lifelong Machine Learning)設置中訓練和評估該模型。
AutoML,全稱為Automated Machine Learning,是機器學習領域的一個新興方向。旨在自動化整個機器學習的流程,降低數據預處理、特征工程、模型選擇、參數調節等環節中的人工成本。
隨著機器學習系統的日益復雜化,AutoML 得到了產學研各界的廣泛關注,已成為人工智能領域最熱門的研究方向之一。
據悉,本次競賽共有 127 個隊伍參加,共收到 550 多個方案,最終有 31 個隊伍進入決賽。
最終獲勝的隊伍為:
冠軍:DeepBlueAI,羅志鵬,黃堅強,陳明健
亞軍:ML Intelligence,包夢蛟,Hui Xue,Yihuan Mao,Yujing Wang
季軍:Meta_Learners,熊錚,蔣繼研,張文鵬
接下來,本文帶來冠軍團隊解決方案的分享。
冠軍方案關鍵技術:自動特征工程和自動快速特征選擇
如下圖所示,研究團隊實現了一個Lifelong AutoML 框架,包括自動特征工程和自動快速特征選擇、自動模型調參、自動模型融合等步驟,在類別不平衡的處理上我們使用了自適應采樣并在模型訓練上有一定的創新,對概念漂移問題我們結合DNN的預訓練和LightGBM的再訓練以及針對性地設計特征來緩解概念漂移,并且利用了多種策略對運行時間和運行內存進行了有效的控制,以確保解決方案能在限制時間和內存下完成整個流程。
自動特征工程與快速特征選擇:
與以往的AutoML框架所不同的是,我們的框架更加注重自動特征工程與特征選擇,我們構建的自動特征工程不僅是基于時間特征、分類特征、數值特征、多值分類特征做特征間的高階組合,同時我們自動提取跨時間、樣本的高階組合。
對于特征選擇,我們結合特征重要性及序列后向選擇算法實現了一個有效的快速特征選擇,在忽略重要性低的特征上結合序列后向特征選擇算法,對重要性極高的特征進行篩選,這能快速地篩選掉過擬合特征,從而大幅度提高模型性能。為了避免維度災難,我們迭代地進行特征工程和特征選擇,在低階特征生成后,利用特征選擇過濾大部分特征,在其基礎上進行更高階的特征組合,更有效地提取了高階特征并避免了維度災難。
緩解類別不平衡:
我們能夠自動針對數據情況(數據大小,數據類型,以及正負樣本比例),以及比賽時間的限制等各種因素的不同,自適應地對數據采取不同的采樣方式和比例,既保證了效率的同時又保證了效果。傳統的類別不平衡的數據訓練方式,是通過提前對數據進行采樣,緩解類別不平衡問題,然后將數據加入模型中訓練。但是這樣會損失大量的數據信息,所以我們在數據采樣的時候,仍然保留大量的高比例樣本,并且將其分批,在加入模型中訓練時,讓模型在梯度提升中輪流訓練分批數據,這樣能夠盡可能保留更多的原始數據的信息,同時緩解了類別不平衡問題。
抗概念漂移處理:
針對數據大小,數據復雜度,自適應選擇batch數目。同時,對于每個batch,加入了“不同batch間采樣率隨時間增加”機制。我們使用DNN模型對特征Embedding進行預訓練,遷移到新的數據批上進行再訓練,有效地緩解了概念漂移和增強了特征表達。
挑戰和改進
研究團隊表示,不同特征類型的處理是本次大賽最棘手的挑戰。
本次大賽數據由多種不同的數據類型組成,這些都是現實世界問題需要處理的真實數據。而現有的AutoML框架往往只支持數值類型,不能簡單將現有框架應用到這些現實數據中。研究人員通過以往的大量競賽及實際項目經驗,在特征工程處理上加入了大量的先驗知識,使得框架能支持不同特征類型的特征工程,以及能自動對這些不同類型特征做高階組合以及特征選擇。支持更多的數據類型而不僅僅是數值類型保證了AutoML能應用到更廣泛的現實問題中,大大增強了AutoML的實用性。
團隊表示,該解決方案有一些可以改進的方面:
首先,比賽所使用的數據僅來自于10個不同的任務,雖然我們在10個任務的數據集上都取得了很好的效果,但并不能保證我們的AutoML框架能應用到更廣泛的不同現實世界問題中。
其次,比賽所提供的都是單表數據,而現實中的問題往往是多表關聯的且關系復雜的,表間的關系往往包括多對多、一對多、多對一、一對一等多種關系。
為了更好地將AutoML應用到現實問題中,我們將設計并實現并實現支持多表聯結數據以及不同數據類型的AutoML框架,將該框架應用到更多現實世界問題的數據上進行測試。
終生自動化機器學習:AutoML對現實世界問題的意義
這次比賽將AutoML擴展到了多種不同的數據類型上,其目標是實現一個支持不同數據類型并能適應概念漂移的終生自動化機器學習。
首先,現實世界問題的數據往往是多種不同數據類型的,需要特定領域的專家對這些數據進行大量的預處理及特征工程,而現有的自動化機器學習框架又僅支持數值類型,對其他類型不能有很好的支持,很難應用到各種現實世界問題中。在這次比賽中,我們團隊設計的AutoML將自動化機器學習擴展到了多種數據類型,引入了不同類型的特征預處理以及不同類型特征的特征工程及特征組合,這樣能在不需要專家的干預下將AutoML應用到更多的現實世界問題中。
其次,許多現實世界問題數據是根據時間逐漸獲取的,數據間往往帶有概念漂移,并存在大量的類別不平衡問題,模型需要不停地重復訓練去適應概念漂移并需要專家去處理概念漂移及類別不平衡問題。我們團隊設計的框架通過融合不同時期的數據以及結合DNN和LightGBM的訓練來自適應概念漂移,引入了自適應采樣以及對梯度提升模型的采樣率進行改進來緩解類別不平衡,實現了終生機器學習。
我們設計的終生自動化機器學習框架可以應用到各種現實世界問題中,例如在推薦系統、異常檢測、在線廣告、欺詐檢測、運輸監控、計量經濟學、病人監控等諸多領域中,無需領域專家的干預,我們的框架可以訓練出一個性能高、時效性強、時間可行的模型,從而降低應用門檻,縮短項目開發周期,促進機器學習的大規模落地。
-
微軟
+關注
關注
4文章
6685瀏覽量
105734 -
數據挖掘
+關注
關注
1文章
406瀏覽量
24705 -
機器學習
+關注
關注
66文章
8501瀏覽量
134583
原文標題:PAKDD AutoML競賽結果出爐,冠軍方案關鍵技術解讀
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
潤和軟件穩居數字業務類解決方案市場第一名
傳音多媒體團隊攬獲CVPR NTIRE 2025兩項挑戰賽冠亞軍,推動視頻畫質升級

傳音多媒體團隊攬獲CVPR NTIRE 2025兩項挑戰賽冠亞軍

華為榮登GlobalData運營商基礎設施管理服務排名報告Leader象限第一名

芯華章持續助力EDA精英挑戰賽
達實再度榮獲十大出入口控制品牌第一名
EDA精英挑戰賽賽果公布!思爾芯“戰隊”薪火相承斬獲“麒麟杯”

蔚來獲得CACSI車型滿意度和售后服務滿意度第一名
理想L6和理想L8榮獲中國新能源汽車用戶滿意度測評第一名
2024年ICPC與華為挑戰賽冠軍杯圓滿落幕
50萬獎金池!開放原子大賽——第二屆OpenHarmony創新應用挑戰賽正式啟動
思爾芯賽題正式發布,邀你共戰EDA精英挑戰賽!
評測活動第一名李工:我用Jupiter畫了個原理圖,然后成了段子手…






 工商網監
工商網監
評論