 手把手教你操作Faster R-CNN和Mask R-CNN
手把手教你操作Faster R-CNN和Mask R-CNN
機器視覺領域的核心問題之一就是目標檢測(Object Detection),它的任務是找出圖像當中所有感興趣的目標(物體),確定其位置和大小。
作為經典的目標檢測框架Faster R-CNN,雖然是2015年的論文,但是它至今仍然是許多目標檢測算法的基礎,這在飛速發展的深度學習領域十分難得。而在Faster R-CNN的基礎上改進的Mask R-CNN在2018年被提出,并斬獲了ICCV2017年的最佳論文。Mask R-CNN可以應用到人體姿勢識別,并且在實例分割、目標檢測、人體關鍵點檢測三個任務都取得了很好的效果。
因此,一些深度學習框架如百度PaddlePaddle開源了用于目標檢測的RCNN模型,從而可以快速構建滿足各種場景的應用,包括但不僅限于安防監控、醫學圖像識別、交通車輛檢測、信號燈識別、食品檢測等等。
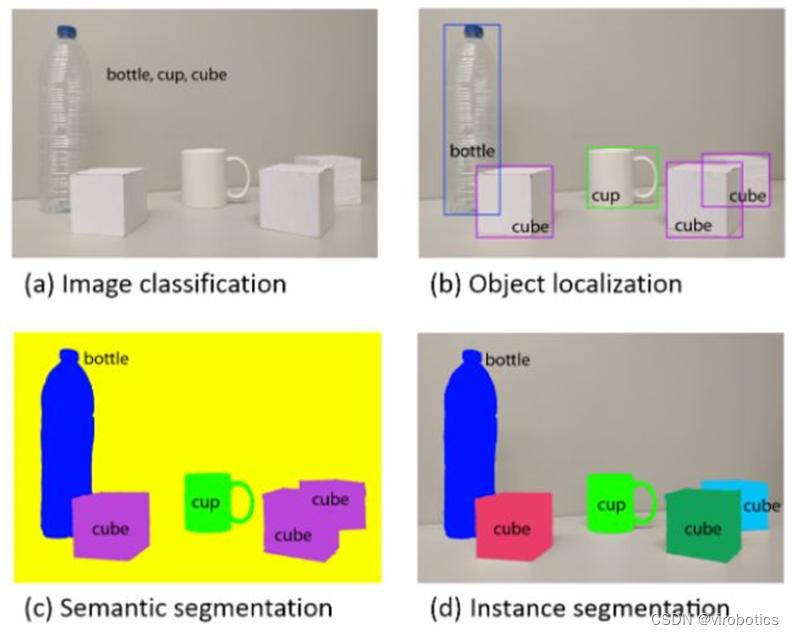
目標檢測(Object Detection)與實例分割(Instance Segmentation)
目標檢測的任務就是確定圖像當中是否有感興趣的目標存在,接著對感興趣的目標進行精準定位。當下非常火熱的無人駕駛汽車,就非常依賴目標檢測和識別,這需要非常高的檢測精度和定位精度。
目前,用于目標檢測的方法通常屬于基于機器學習的方法或基于深度學習的方法。 對于機器學習方法,首先使用SIFT、HOG等方法定義特征,然后使用支持向量機(SVM)、Adaboost等技術進行分類。 對于深度學習方法,深度學習技術能夠在沒有專門定義特征的情況下進行端到端目標檢測,并且通常基于卷積神經網絡(CNN)。但是傳統的目標檢測方法有如下幾個問題:光線變化較快時,算法效果不好;緩慢運動和背景顏色一致時不能提取出特征像素點;時間復雜度高;抗噪性能差。
因此,基于深度學習的目標檢測方法得到了廣泛應用,該框架包含有Faster R-CNN,Yolo,Mask R-CNN等,圖1和圖2分別顯示的是基于PaddlePaddle深度學習框架訓練的Faster R-CNN和Mask R-CNN模型對圖片中的物體進行目標檢測。
從圖1中可以看出,目標檢測主要是檢測一張圖片中有哪些目標,并且使用方框表示出來,方框中包含的信息有目標所屬類別。圖2與圖1的最大區別在于,圖2除了把每一個物體的方框標注出來,并且把每個方框中像素所屬的類別也標記了出來。
圖1 基于paddlepaddle訓練的Faster R-CNN模型預測結果
圖2 基于paddlepaddle訓練的Mask R-CNN模型預測結果
從R-CNN到Mask R-CNN
Mask R-CNN是承繼于Faster R-CNN,Mask R-CNN只是在Faster R-CNN上面增加了一個Mask Prediction Branch(Mask預測分支),并且在ROI Pooling的基礎之上提出了ROI Align。所以要想理解Mask R-CNN,就要先熟悉Faster R-CNN。同樣的,Faster R-CNN是承繼于Fast R-CNN,而Fast R-CNN又承繼于R-CNN,因此,為了能讓大家更好的理解基于CNN的目標檢測方法,我們從R-CNN開始切入,一直介紹到Mask R-CNN。
R-CNN
區域卷積神經網絡(Regions with CNN features)使用深度模型來解決目標檢測。
R-CNN的操作步驟
Selective search(選擇性搜索):首先對每一張輸入圖像使用選擇性搜索來選取多個高質量的提議區域(region proposal),大約提取2000個左右的提議區域;
Resize(圖像尺寸調整):接著對每一個提議區域,將其縮放(warp)成卷積神經網絡需要的輸入尺寸(277*277);
特征抽取:選取一個預先訓練好的卷積神經網絡,去掉最后的輸出層來作為特征抽取模塊;
SVM(類別預測):將每一個提議區域提出的CNN特征輸入到支持向量機(SVM)來進行物體類別分類。注:這里第 i 個 SVM 用來預測樣本是否屬于第 i 類;
Bounding Box Regression(邊框預測):對于支持向量機分好類的提議區域做邊框回歸,訓練一個線性回歸模型來預測真實邊界框,校正原來的建議窗口,生成預測窗口坐標。
R-CNN優缺點分析
優點:R-CNN 對之前物體識別算法的主要改進是使用了預先訓練好的卷積神經網絡來抽取特征,有效的提升了識別精度。
缺點:速度慢。對一張圖像我們可能選出上千個興趣區域,這樣導致每張圖像需要對卷積網絡做上千次的前向計算。
Fast R-CNN
R-CNN 的主要性能瓶頸在于需要對每個提議區域(region proposal)獨立的抽取特征,這會造成區域會有大量重疊,獨立的特征抽取導致了大量的重復計算。因此,Fast R-CNN 對 R-CNN 的一個主要改進在于首先對整個圖像進行特征抽取,然后再選取提議區域,從而減少重復計算。
Fast R-CNN 的操作步驟
Selective Search(選擇性搜索):首先對每一張輸入圖像使用選擇性搜索(selective search)算法來選取多個高質量的提議區域(region proposal),大約提取2000個左右的提議區域;
將整張圖片輸入卷積神經網絡,對全圖進行特征提取;
把提議區域映射到卷積神經網絡的最后一層卷積(feature map)上;
RoI Pooling:引入了興趣區域池化層(Region of Interest Pooling)來對每個提議區域提取同樣大小的輸出;
Softmax:在物體分類時,Fast R-CNN 不再使用多個 SVM,而是像之前圖像分類那樣使用 Softmax 回歸來進行多類預測。
Fast R-CNN優缺點分析
優點:對整個圖像進行特征抽取,然后再選取提議區域,從而減少重復計算;
缺點:選擇性搜索費時;
缺點:不用Resize,不適合求導;
Faster R-CNN
Faster R-CNN 對 Fast R-CNN 做了進一步改進,它將 Fast R-CNN 中的選擇性搜索替換成區域提議網絡(region proposal network)。RPN 以錨框(anchors)為起始點,通過一個小神經網絡來選擇區域提議。
Faster R-CNN整體網絡可以分為4個主要內容:
基礎卷積層(CNN):作為一種卷積神經網絡目標檢測方法,Faster R-CNN首先使用一組基礎的卷積網絡提取圖像的特征圖。特征圖被后續RPN層和全連接層共享。本示例采用ResNet-50作為基礎卷積層。
區域生成網絡(RPN):RPN網絡用于生成候選區域(proposals)。該層通過一組固定的尺寸和比例得到一組錨點(anchors), 通過softmax判斷錨點屬于前景或者背景,再利用區域回歸修正錨點從而獲得精確的候選區域。
RoI Pooling:該層收集輸入的特征圖和候選區域,將候選區域映射到特征圖中并池化為統一大小的區域特征圖,送入全連接層判定目標類別, 該層可選用RoIPool和RoIAlign兩種方式,在config.py中設置roi_func。
檢測層:利用區域特征圖計算候選區域的類別,同時再次通過區域回歸獲得檢測框最終的精確位置。
Faster R-CNN優缺點分析
優點:RPN 通過標注來學習預測跟真實邊界框更相近的提議區域,從而減小提議區域的數量同時保證最終模型的預測精度。
缺點:無法達到實時目標檢測。
Mask R-CNN
Faster R-CNN 在物體檢測中已達到非常好的性能,Mask R-CNN在此基礎上更進一步:得到像素級別的檢測結果。 對每一個目標物體,不僅給出其邊界框,并且對邊界框內的各個像素是否屬于該物體進行標記。Mask R-CNN同樣為兩階段框架,第一階段掃描圖像生成候選框;第二階段根據候選框得到分類結果,邊界框,同時在原有Faster R-CNN模型基礎上添加分割分支,得到掩碼結果,實現了掩碼和類別預測關系的解藕。
圖3 Mask R-CNN網絡結構泛化圖
Mask R-CNN的創新點
解決特征圖與原始圖像上的RoI不對準問題:在Faster R-CNN中,沒有設計網絡的輸入和輸出的像素級別的對齊機制(pixel to pixel)。為了解決特征不對準的問題,文章作者提出了RoIAlign層來解決這個問題,它能準確的保存空間位置,進而提高mask的準確率。
將掩模預測(mask prediction)和分類預測(class prediction)拆解:該框架結構對每個類別獨立的預測一個二值mask,不依賴分類(classification)分支的預測結果
掩模表示(mask representation):有別于類別,框回歸,這幾個的輸出都可以是一個向量,但是mask必須要保持一定的空間結構信息,因此作者采用全連接層(FCN)對每一個RoI中預測一個m*m的掩模。
圖4展示了Mask R-CNN在像素級別的目標檢測結果:
圖4 Mask R-CNN:像素級別的目標檢測
基于PaddlePaddle的實戰
環境準備:需要PaddlePaddle Fluid的v.1.3.0或以上的版本。如果你的運行環境中的PaddlePaddle低于此版本,請根據安裝文檔中的說明來更新PaddlePaddle。
數據準備:在MS-COCO數據集上進行訓練,可以通過腳本來直接下載數據集:
cddataset/coco./download.sh
數據目錄結構如下:
data/coco/├──annotations│├──instances_train2014.json│├──instances_train2017.json│├──instances_val2014.json│├──instances_val2017.json|...├──train2017│├──000000000009.jpg│├──000000580008.jpg|...├──val2017│├──000000000139.jpg│├──000000000285.jpg|...
模型訓練:下載預訓練模型:本示例提供Resnet-50預訓練模型,該模性轉換自Caffe,并對批標準化層(Batch Normalization Layer)進行參數融合。采用如下命令下載預訓練模型。
sh./pretrained/download.sh
通過初始化pretrained_model加載預訓練模型。同時在參數微調時也采用該設置加載已訓練模型。 請在訓練前確認預訓練模型下載與加載正確,否則訓練過程中損失可能會出現NAN。
安裝cocoapi:
訓練前需要首先下載cocoapi:
gitclonehttps://github.com/cocodataset/cocoapi.gitcdcocoapi/PythonAPI#ifcythonisnotinstalledpipinstallCython#Installintoglobalsite-packagesmakeinstall#Alternatively,ifyoudonothavepermissionsorprefer#nottoinstalltheCOCOAPIintoglobalsite-packagespython2setup.pyinstall--user
數據準備完畢后,可以通過如下的方式啟動訓練:
Faster RCNN
pythontrain.py--model_save_dir=output/--pretrained_model=${path_to_pretrain_model}--data_dir=${path_to_data}--MASK_ON=False
Mask RCNN
pythontrain.py--model_save_dir=output/--pretrained_model=${path_to_pretrain_model}--data_dir=${path_to_data}--MASK_ON=False
通過設置export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7指定8卡GPU訓練。
通過設置MASK_ON選擇Faster RCNN和Mask RCNN模型。
可選參數見:
python train.py –help
數據讀取器說明:
數據讀取器定義在reader.py中。所有圖像將短邊等比例縮放至scales,若長邊大于max_size, 則再次將長邊等比例縮放至max_size。在訓練階段,對圖像采用水平翻轉。支持將同一個batch內的圖像padding為相同尺寸。
模型設置:
分別使用RoIAlign和RoIPool兩種方法。
訓練過程pre_nms=12000,post_nms=2000,測試過程pre_nms=6000, post_nms=1000。nms閾值為0.7。
RPN網絡得到labels的過程中,fg_fraction=0.25,fg_thresh=0.5,bg_thresh_hi=0.5,bg_thresh_lo=0.0
RPN選擇anchor時,rpn_fg_fraction=0.5,rpn_positive_overlap=0.7,rpn_negative_overlap=0.3
訓練策略:
采用momentum優化算法訓練,momentum=0.9。
權重衰減系數為0.0001,前500輪學習率從0.00333線性增加至0.01。在120000,160000輪時使用0.1,0.01乘子進行學習率衰減,最大訓練180000輪。同時我們也提供了2x模型,該模型采用更多的迭代輪數進行訓練,訓練360000輪,學習率在240000,320000輪衰減,其他參數不變,訓練最大輪數和學習率策略可以在config.py中對max_iter和lr_steps進行設置。
非基礎卷積層卷積bias學習率為整體學習率2倍。
基礎卷積層中,affine_layers參數不更新,res2層參數不更新。
模型評估:模型評估是指對訓練完畢的模型評估各類性能指標。本示例采用COCO官方評估。eval_coco_map.py是評估模塊的主要執行程序,調用示例如下:
Faster RCNN
pythoneval_coco_map.py--dataset=coco2017--pretrained_model=${path_to_trained_model}--MASK_ON=False
Mask RCNN
pythoneval_coco_map.py--dataset=coco2017--pretrained_model=${path_to_trained_model}--MASK_ON=True
通過設置--pretrained_model=${path_to_trained_model}指定訓練好的模型,注意不是初始化的模型。
通過設置export CUDA\_VISIBLE\_DEVICES=0指定單卡GPU評估。
通過設置MASK_ON選擇Faster RCNN和Mask RCNN模型。
模型精度:下表為模型評估結果。
Faster RCNN:
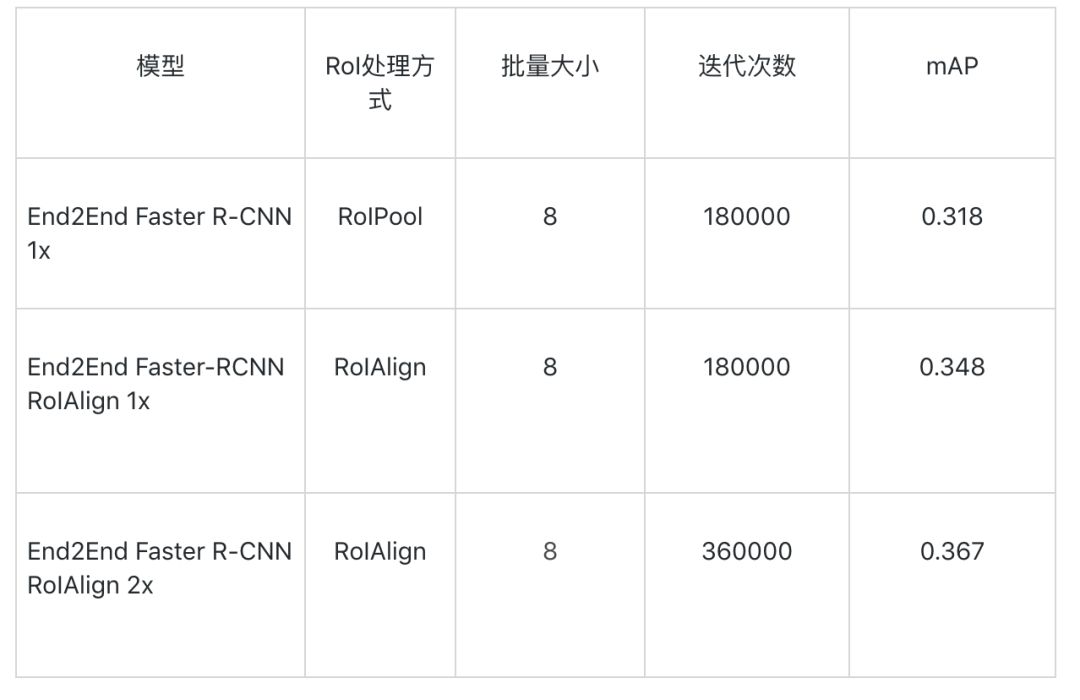
End2End Faster R-CNN: 使用RoIPool,不對圖像做填充處理。
End2End Faster R-CNN RoIAlign 1x:使用RoIAlign,不對圖像做填充處理。
End2End Faster R-CNN RoIAlign 2x:使用RoIAlign,不對圖像做填充處理。訓練360000輪,學習率在240000,320000輪衰減。
Mask RCNN:
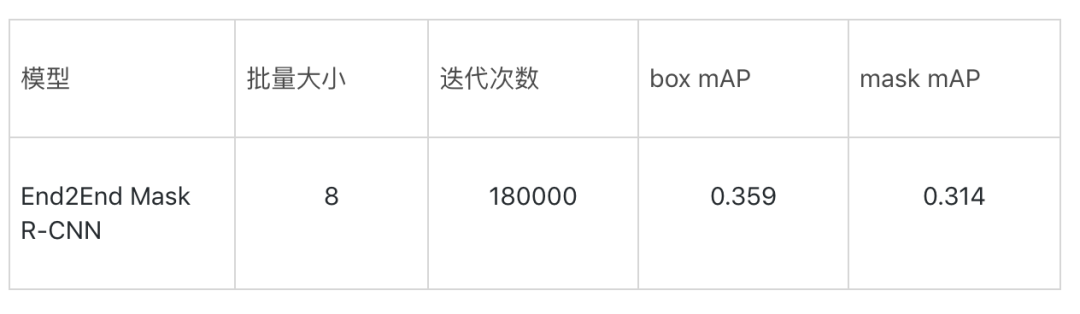
End2End Mask R-CNN: 使用RoIAlign,不對圖像做填充處理。
模型推斷:模型推斷可以獲取圖像中的物體及其對應的類別,infer.py是主要執行程序,調用示例如下:
pythoninfer.py--pretrained_model=${path_to_trained_model}--image_path=dataset/coco/val2017/000000000139.jpg--draw_threshold=0.6
注意,請正確設置模型路徑${path_to_trained_model}和預測圖片路徑。默認使用GPU設備,也可通過設置--use_gpu=False使用CPU設備。可通過設置draw_threshold調節得分閾值控制檢測框的個數。
-
機器視覺
+關注
關注
163文章
4508瀏覽量
122228 -
無人駕駛
+關注
關注
99文章
4151瀏覽量
122847 -
深度學習
+關注
關注
73文章
5554瀏覽量
122469
原文標題:完整代碼+實操!手把手教你操作Faster R-CNN和Mask R-CNN
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
介紹目標檢測工具Faster R-CNN,包括它的構造及實現原理

什么是Mask R-CNN?Mask R-CNN的工作原理
引入Mask R-CNN思想通過語義分割進行任意形狀文本檢測與識別
一種新的帶有不確定性的邊界框回歸損失,可用于學習更準確的目標定位

基于改進Faster R-CNN的目標檢測方法
一種基于Mask R-CNN的人臉檢測及分割方法

基于Mask R-CNN的遙感圖像處理技術綜述
用于實例分割的Mask R-CNN框架
PyTorch教程14.8之基于區域的CNN(R-CNN)

PyTorch教程-14.8。基于區域的 CNN (R-CNN)






 工商網監
工商網監
評論