") 網(wǎng)絡(luò)爬蟲的基本工作流程
網(wǎng)絡(luò)爬蟲的基本工作流程
網(wǎng)絡(luò)爬蟲的基本工作流程
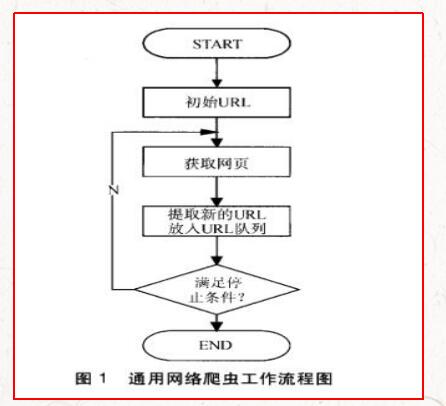
通用網(wǎng)絡(luò)爬蟲根據(jù)預(yù)先設(shè)定的一個(gè)或若干初始種子URL開(kāi)始,以此獲得初始網(wǎng)頁(yè)上的URL列表,在爬行過(guò)程中不斷從URL隊(duì)列中獲一個(gè)的URL,進(jìn)而訪問(wèn)并下載該頁(yè)面。頁(yè)面下載后頁(yè)面解析器去掉頁(yè)面上的HTML標(biāo)記后得到頁(yè)面內(nèi)容,將摘要、URL等信息保存到Web數(shù)據(jù)庫(kù)中,同時(shí)抽取當(dāng)前頁(yè)面上新的URL,保存到URL隊(duì)列,直到滿足系統(tǒng)停止條件。其工作流程如圖1所示。
主題爬蟲工作流程
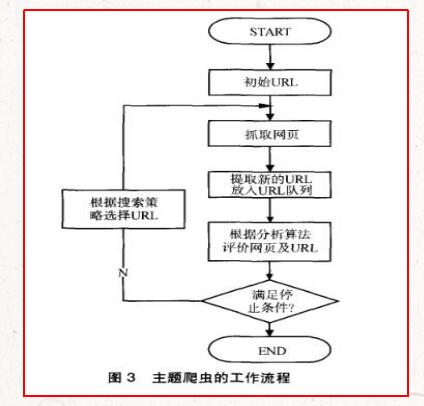
主題爬蟲需要根據(jù)一定的網(wǎng)頁(yè)分析算法,過(guò)濾掉與主題無(wú)關(guān)的鏈接,保留有用的鏈接并將其放入等待抓取的URL隊(duì)列。然后,它會(huì)根據(jù)一定的搜索策略從待抓取的隊(duì)列中選擇下一個(gè)要抓取的URL,并重復(fù)上述過(guò)程,直到滿足系統(tǒng)停止條件為止。所有被抓取網(wǎng)頁(yè)都會(huì)被系統(tǒng)存儲(chǔ),經(jīng)過(guò)一定的分析、過(guò)濾,然后建立索引,以便用戶查詢和檢索;這一過(guò)程所得到的分析結(jié)果可以對(duì)以后的抓取過(guò)程提供反饋和指導(dǎo)。其工作流程如圖3所示。
深度網(wǎng)絡(luò)爬蟲工作流程
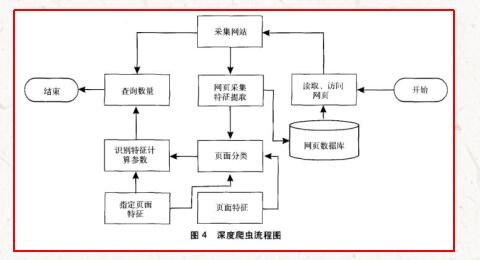
1994年Dr.jillEllsworth提出DeepWeb(深層頁(yè)面)的概念,即DeepWeb是指普通搜索引擎難以發(fā)現(xiàn)的信息內(nèi)容的Web頁(yè)面¨。DeepWeb中的信息量比普通的網(wǎng)頁(yè)信息量多,而且質(zhì)量更高。但是普通的搜索引擎由于技術(shù)限制而搜集不到這些高質(zhì)量、高權(quán)威的信息。這些信息通常隱藏在深度Web頁(yè)面的大型動(dòng)態(tài)數(shù)據(jù)庫(kù)中,涉及數(shù)據(jù)集成、中文語(yǔ)義識(shí)別等諸多領(lǐng)域。如此龐大的信息資源如果沒(méi)有合理的、高效的方法去獲取,將是巨大的損失。因此,對(duì)于深度網(wǎng)爬行技術(shù)的研究具有極為重大的現(xiàn)實(shí)意義和理論價(jià)值。
-
網(wǎng)絡(luò)爬蟲
+關(guān)注
關(guān)注
1文章
52瀏覽量
8879 -
爬蟲
+關(guān)注
關(guān)注
0文章
83瀏覽量
7346
發(fā)布評(píng)論請(qǐng)先 登錄
NX CAD軟件:數(shù)字化工作流程解決方案(CAD工作流程)

AI工作流自動(dòng)化是做什么的
IP地址數(shù)據(jù)信息和爬蟲攔截的關(guān)聯(lián)
使用pdfDocs提高工作效率,改進(jìn)PDF工作流程

LJ40B4-20J/EZ常開(kāi)型接近開(kāi)關(guān)工作流程及接線圖
用CPLD控制ADS7229,工作流程是怎么樣的?
ADS8331在開(kāi)發(fā)標(biāo)準(zhǔn)的工作流程是什么?
數(shù)據(jù)科學(xué)工作流原理
淺談無(wú)刷電機(jī)的工作流程
NVIDIA發(fā)布全新AI和仿真工具以及工作流
人員定位系統(tǒng)的原理和工作流程
從記錄到管理:?jiǎn)伪倍?b class='flag-5'>工作記錄儀如何優(yōu)化工作流程






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論