 AI生成的圖像可能會取代現有的攝影技術
AI生成的圖像可能會取代現有的攝影技術

自GAN誕生以來,在計算機視覺領域中表現可謂是驚艷連連:文本-圖像轉換、域遷移、圖像修復/拓展、人臉合成甚至是細微表情的改變,無所不能。本文對此進行了盤點,并且作者表示:GAN很快就可能替代現有的攝影技術了!
AI生成的圖像可能會取代現有的攝影技術。
許多人當聽到“人工智能”、“機器學習”或者“bot”的時候,首先浮現在腦海當中的應當是科幻片中經常出現、未來感十足的既會走路又會說話的機器人。
但事實并非如此!人工智能已經“潛伏”在我們身邊很多年了。現在就有可能在你的智能手機里(Siri/谷歌語音助手)、汽車GPS系統里。
然而,在過去幾年中,沒有哪個域比計算機視覺更受其影響。
隨著科技的發展,具有超高分辨率視覺吸引力的圖像變得越來越普遍。人們不再需要學習如何使用Photoshop和CorelDRAW等工具來增強和修改圖像,因為AI可以在這些方面產生最佳效果的圖像。然而,最新提出的想法實際上是綜合使用AI來生成圖像。
以往我們所看到的所有圖像,其生成過程肯定都或多或少有“人”的參與。但是試想一下,一個計算機程序可以從零開始繪制你想要它繪制的任何內容,在不久的將來,你只需要給它一些指令,例如“我想要一張站在埃菲爾鐵塔旁邊的照片”,然后圖像就生成了(當然,你的輸入要準確)!
生成對抗網絡(GAN)
“在機器學習過去的10年里,GAN是最有趣的一個想法。”
——Yann LeCun
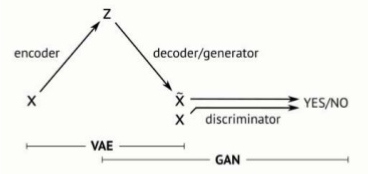
生成這種合成圖像的基礎就是生成對抗網絡(GAN)。
自從Ian Goodfellow和他的同事在2014年發現并推出他們的研究論文以來,GAN一直是深度學習中最迷人且被最廣泛使用的技術之一。這項技術無窮無盡的應用,也就是所謂對抗性訓練的核心,不僅包括計算機視覺,還包括數據分析、機器人技術和預測模型。
那么,GAN有什么了不起的呢?
生成性對抗網絡屬于一組生成模型。 這意味著他們的工作是在完全自動化的過程中創建或“生成”新數據的。
lan Goodfellow論文中生成的圖像。
地址:https://arxiv.org/abs/1406.2661
顧名思義,GAN實際上由兩個相互競爭的獨立神經網絡組成(以對抗的方式)。其中一個神經網絡稱為生成器,從隨機噪聲中生成新的數據實例;另一個神經網絡稱為鑒別器,它會對這些實例進行真實性評估。換言之,鑒別器決定它檢查的每個數據實例是否屬于實際的訓練數據集。
一個簡單的例子
假設你的任務就是高仿一幅著名畫作。但不幸的是,你并不知道這位藝術家是誰,也沒有見過他的畫作。但你的任務就是高仿它,并作為原作之一在拍賣會上展出。
你只有一些顏料和畫布。但是拍賣商不希望隨意出售作品,所以他們雇了一名偵探來對畫作辨別真偽。偵探手中有這幅名作的真跡,所以若是你隨意拿出一個作品,偵探立刻就能知道你的畫作是贗品(甚至完全不同)。
當偵探拒絕了一次之后,你會再去創作一個作品。但是通過這次經驗,你會通過偵探得到一些提示(這些提示有關真跡畫作應該是什么樣子)。
當你再次嘗試的時候,畫作會比第一次好一些。此時,偵探還是不相信這是真跡,于是你在又得到一些提示的情況下,再次嘗試,以此類推。直到你畫了1000次,偵探拿著你的高仿作品,已然不知道哪幅畫是真跡了。
GAN的工作流程是什么?
將上述的思維過程應用于神經網絡組合,GAN的訓練過程包括以下步驟:

GAN的基本框架。
地址:https://medium.freecodecamp.org/an-intuitive-introduction-to-generative-adversarial-networks-gans-7a2264a81394
最開始,發生器接收一些隨機噪聲并將其傳遞給鑒別器;
因為鑒別器已經訪問了真實圖像的數據集,所以它將這些真實數據集與從生成器接收到的圖像進行比較,并評估其真實性;
由于初始圖像只是隨機噪聲,它將被評估為“假”;
生成器通過不斷改變參數,開始生成更好的圖像;
隨著訓練的進行,生成假圖像的生成器和檢測它們的鑒別器會變得越發的智能;
最后,生成器設法創建一個與真實圖像數據集中的圖像難以區分的圖像。此時,鑒別器便無法分辨給定的圖像是真還是假;
此時,訓練結束,生成的圖像就是我們想要的最終結果。

我們自己的GAN生成汽車標志圖像的過程。
現在,讓我們來看一下代碼吧!
下面是用Pytorch實現的一個基本生成網絡:
1importargparse 2importos 3importnumpyasnp 4importmath 5 6importtorchvision.transformsastransforms 7fromtorchvision.utilsimportsave_image 8 9fromtorch.utils.dataimportDataLoader 10fromtorchvisionimportdatasets 11fromtorch.autogradimportVariable 12 13importtorch.nnasnn 14importtorch.nn.functionalasF 15importtorch 16 17os.makedirs('images',exist_ok=True) 18 19parser=argparse.ArgumentParser() 20parser.add_argument('--n_epochs',type=int,default=200,help='numberofepochsoftraining') 21parser.add_argument('--batch_size',type=int,default=64,help='sizeofthebatches') 22parser.add_argument('--lr',type=float,default=0.0002,help='adam:learningrate') 23parser.add_argument('--b1',type=float,default=0.5,help='adam:decayoffirstordermomentumofgradient') 24parser.add_argument('--b2',type=float,default=0.999,help='adam:decayoffirstordermomentumofgradient') 25parser.add_argument('--n_cpu',type=int,default=8,help='numberofcputhreadstouseduringbatchgeneration') 26parser.add_argument('--latent_dim',type=int,default=100,help='dimensionalityofthelatentspace') 27parser.add_argument('--img_size',type=int,default=28,help='sizeofeachimagedimension') 28parser.add_argument('--channels',type=int,default=1,help='numberofimagechannels') 29parser.add_argument('--sample_interval',type=int,default=400,help='intervalbetwenimagesamples') 30opt=parser.parse_args() 31print(opt) 32 33img_shape=(opt.channels,opt.img_size,opt.img_size) 34 35cuda=Trueiftorch.cuda.is_available()elseFalse 36 37classGenerator(nn.Module): 38def__init__(self): 39super(Generator,self).__init__() 40 41defblock(in_feat,out_feat,normalize=True): 42layers=[nn.Linear(in_feat,out_feat)] 43ifnormalize: 44layers.append(nn.BatchNorm1d(out_feat,0.8)) 45layers.append(nn.LeakyReLU(0.2,inplace=True)) 46returnlayers 47 48self.model=nn.Sequential( 49*block(opt.latent_dim,128,normalize=False), 50*block(128,256), 51*block(256,512), 52*block(512,1024), 53nn.Linear(1024,int(np.prod(img_shape))), 54nn.Tanh() 55) 56 57defforward(self,z): 58img=self.model(z) 59img=img.view(img.size(0),*img_shape) 60returnimg 61 62classDiscriminator(nn.Module): 63def__init__(self): 64super(Discriminator,self).__init__() 65 66self.model=nn.Sequential( 67nn.Linear(int(np.prod(img_shape)),512), 68nn.LeakyReLU(0.2,inplace=True), 69nn.Linear(512,256), 70nn.LeakyReLU(0.2,inplace=True), 71nn.Linear(256,1), 72nn.Sigmoid() 73) 74 75defforward(self,img): 76img_flat=img.view(img.size(0),-1) 77validity=self.model(img_flat) 78 79returnvalidity 80 81#Lossfunction 82adversarial_loss=torch.nn.BCELoss() 83 84#Initializegeneratoranddiscriminator 85generator=Generator() 86discriminator=Discriminator() 87 88ifcuda: 89generator.cuda() 90discriminator.cuda() 91adversarial_loss.cuda() 92 93#Configuredataloader 94os.makedirs('../../data/mnist',exist_ok=True) 95dataloader=torch.utils.data.DataLoader( 96datasets.MNIST('../../data/mnist',train=True,download=True, 97transform=transforms.Compose([ 98transforms.ToTensor(), 99transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))100])),101batch_size=opt.batch_size,shuffle=True)102103#Optimizers104optimizer_G=torch.optim.Adam(generator.parameters(),lr=opt.lr,betas=(opt.b1,opt.b2))105optimizer_D=torch.optim.Adam(discriminator.parameters(),lr=opt.lr,betas=(opt.b1,opt.b2))106107Tensor=torch.cuda.FloatTensorifcudaelsetorch.FloatTensor108109#----------110#Training111#----------112113forepochinrange(opt.n_epochs):114fori,(imgs,_)inenumerate(dataloader):115116#Adversarialgroundtruths117valid=Variable(Tensor(imgs.size(0),1).fill_(1.0),requires_grad=False)118fake=Variable(Tensor(imgs.size(0),1).fill_(0.0),requires_grad=False)119120#Configureinput121real_imgs=Variable(imgs.type(Tensor))122123#-----------------124#TrainGenerator125#-----------------126127optimizer_G.zero_grad()128129#Samplenoiseasgeneratorinput130z=Variable(Tensor(np.random.normal(0,1,(imgs.shape[0],opt.latent_dim))))131132#Generateabatchofimages133gen_imgs=generator(z)134135#Lossmeasuresgenerator'sabilitytofoolthediscriminator136g_loss=adversarial_loss(discriminator(gen_imgs),valid)137138g_loss.backward()139optimizer_G.step()140141#---------------------142#TrainDiscriminator143#---------------------144145optimizer_D.zero_grad()146147#Measurediscriminator'sabilitytoclassifyrealfromgeneratedsamples148real_loss=adversarial_loss(discriminator(real_imgs),valid)149fake_loss=adversarial_loss(discriminator(gen_imgs.detach()),fake)150d_loss=(real_loss+fake_loss)/2151152d_loss.backward()153optimizer_D.step()154155print("[Epoch%d/%d][Batch%d/%d][Dloss:%f][Gloss:%f]"%(epoch,opt.n_epochs,i,len(dataloader),156d_loss.item(),g_loss.item()))157158batches_done=epoch*len(dataloader)+i159ifbatches_done%opt.sample_interval==0:160save_image(gen_imgs.data[:25],'images/%d.png'%batches_done,nrow=5,normalize=True)
優點和缺點
與其它技術一樣,GAN也有自身的優缺點。
下面是GAN的一些潛在優勢:
GAN并不總是需要帶標簽的樣本來訓練;
它們更容易訓練依賴于蒙特卡羅(Monte Carlo)近似的對數分割函數梯度的生成模型。由于蒙特卡羅方法在高維空間中不能很好地工作,這樣的生成模型不能很好地執行像使用ImageNet進行訓練的現實任務。
他們沒有引入任何確定性偏差。 像變分自動編碼器這樣的某些生成方法會引入確定性偏差,因為它們優化了對數似然的下界,而不是似然本身。
同樣,GAN也有它的缺點:
GAN特別難訓練。這些網絡試圖優化的函數是一個本質上沒有封閉形式的損失函數。因此,優化這一損失函數是非常困難的,需要在網絡結構和訓練協議方面進行大量的反復試驗;
(特別是)對于圖像生成,沒有適當的措施來評估準確性。 由于合成圖像可以通過計算機本身來實現,因此實際結果是一個非常主觀的主題,并且取決于人類觀察者。 相反,我們有起始分數和Frechet初始距離等功能來衡量他們的表現。
GAN的應用
最有趣的部分來了!
我們可以用GAN做的所有驚人的東西。 在它所有潛在用途中,GAN已經在計算機視覺領域中實現了大量應用。
文本-圖像轉換
這個概念有許多實驗的方法,例如TAC-GAN(文本條件輔助分類器生成對抗網絡)。
左:TAC-GAN的結構示意圖。右:將一行文本輸入網絡所產生的結果。
域遷移(Domain Transfer)
它包括使用稱為CGAN(條件生成對抗網絡)的特殊類型的GAN進行圖像到圖像的轉換。
繪畫和概念設計從未如此簡單。
然而,雖然GAN可以從它的草圖中完成像錢包這樣簡單的繪圖,但繪制更復雜的東西,如完美的人臉,目前還不是GAN的強項。
CGAN pix2pix的實驗結果
Image Inpaintinng(圖像修復)/Image Outpainting(圖像拓展)
生成網絡的兩個非常激動人心的應用是:圖像修復(Inpainting)和圖像拓展(Outpainting)。
第一種包括在圖像中填充或噪聲,這可以看作是圖像的修復。例如,給定一個殘缺的圖像,GAN能夠以“passable”的方式對其進行糾正它。
另一方面,圖像拓展涉及到使用網絡自身的學習來想象一個圖像在當前邊界之外可能會是什么樣子。
左:圖像修復結果;右:圖像拓展結果。
人臉合成
由于生成網絡的存在,使得人臉合成成為了可能,這涉及到從不同角度生成單個人臉圖像。
這就是為什么面部識別不需要數百個人臉樣本,只需要用一個樣本就能識別出來的原因。
不僅如此,生成“人造人臉”也變得可能。 NVIDIA最近使用他們的GAN 2.0在Celeba Hq數據集上生成了高清分辨率的人造人臉,這是高分辨率合成圖像生成的第一個例子。
用Progressive GAN生成想象中的名人面孔。
GANimation
GAN使得諸如改變面部運動這樣的事情也成為可能。GANimation是一項使用PyTorch的研究成果,它將自己定義為“從一張圖像中提取具有解剖學意義的面部動畫”。
GANimation官方實現。
地址:https://www.albertpumarola.com/research/GANimation/index.html
繪畫-照片轉換
利用GAN使圖像變得更逼真的另一個例子是簡單地將繪畫變成照片。
這是使用稱為CycleGAN的特殊類型的GAN完成的,它使用兩個發生器和兩個鑒別器。
我們把一個發生器稱為G,它把圖像從X域轉換成Y域。另一個生成器稱為F,它將圖像從Y轉換為X。每個生成器都有一個對應的鑒別器,該鑒別器試圖將其合成的圖像與真實圖像區分開來。
CycleGAN的結果。
地址:https://github.com/junyanz/CycleGAN
GAN是一把雙刃劍
機器學習和GAN肯定會在不久的將來對成像和攝影產生巨大影響。
目前,該技術能夠從文本輸入生成簡單圖像。然而,在可預見的未來,它不僅能夠創建高分辨率的精確圖像,還能夠創建完整的視頻。
想象一下,只需要簡單地將腳本輸入到GAN中,便可以生成一部電影。不僅如此,每個人都可以使用簡單的交互式應用程序來創建自己的電影(甚至可以自己主演!)。
當然,技術是一把雙刃劍。
若是這么好的技術被壞人利用,后果是不堪設想的。完美的假圖像還需要一種方法來識別和檢測它們,我們需要對這類圖像的產生進行管制。
目前,GAN已經被用于制作虛假視頻或“Deepfakes”,這些視頻正以消極的方式被使用著,例如生成名人假的不良視頻或讓人們在不知情的情況下“被發表言論”。
音頻、視頻合成技術使用不良手段造成傳播后的結果將是非常可怕的。
-
AI
+關注
關注
88文章
35109瀏覽量
279612 -
GaN
+關注
關注
19文章
2207瀏覽量
76783 -
計算機視覺
+關注
關注
9文章
1708瀏覽量
46774
原文標題:為什么說GAN很快就要替代現有攝影技術了?
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
基于擴散模型的圖像生成過程

現有的技術能實現嗎?
電動汽車會取代燃油汽車嗎?
你知道哪些高科技可能會含有的小功率模塊電源嗎
MRAM實現對車載MCU中嵌入式存儲器的取代
未來AI可能會更替180萬個崗位,你該如何應對?
人工智能可能會替代人類嗎
Stability AI開源圖像生成模型Stable Diffusion
虹軟圖像深度恢復技術與生成式AI的創新 生成式AI助力
在線研討會 | 9 月 19 日,利用 GPU 加速生成式 AI 圖像內容生成






 工商網監
工商網監
評論