") 一種在視覺語言導(dǎo)航任務(wù)中提出的新方法,來探索未知環(huán)境
一種在視覺語言導(dǎo)航任務(wù)中提出的新方法,來探索未知環(huán)境
CVPR 2019 接收論文編號(hào)公布以來,AI科技大本營開始陸續(xù)為大家介紹一些優(yōu)秀論文。今天推薦的論文,將與大家一起探討一種在視覺語言導(dǎo)航任務(wù)中提出的新方法,來探索未知環(huán)境。

作者
這篇論文是 UC Santa Barbara 大學(xué)(加州大學(xué)圣巴巴拉分校)與微軟研究院、Duke 大學(xué)合作完成,第一作者系 UC Santa Barbara 大學(xué)的王鑫。
據(jù) UC Santa Barbara 計(jì)算機(jī)科學(xué)系助理教授王威廉在其個(gè)人微博上發(fā)表的喜訊,這篇論文的一作是其組內(nèi)的成員,獲得了 3 個(gè) Strong Accept,在 5165 篇投稿文章中審稿得分排名第一,并且這篇論文已經(jīng)確定將在 6 月的 CVPR 會(huì)議上進(jìn)行報(bào)告。

這篇論文解決的任務(wù) vision-language navigation(VLN)我們之前介紹的并不多,所以,這次營長會(huì)先給大家簡單介紹 VLN,然后從這項(xiàng)任務(wù)存在的難點(diǎn)到解決方法、實(shí)驗(yàn)效果等方面為大家介紹,感興趣的小伙伴們可以從文末的地址下載論文,詳細(xì)閱讀。
什么是 VLN?
視覺語言導(dǎo)航(vision-language navigation, VLN)任務(wù)指的是引導(dǎo)智能體或機(jī)器人在真實(shí)三維場景中能理解自然語言命令并準(zhǔn)確執(zhí)行。結(jié)合下面這張圖再形象、通俗一點(diǎn)解釋:假如智能體接收到“向右轉(zhuǎn),徑直走向廚房,然后左轉(zhuǎn),經(jīng)過一張桌子后進(jìn)入走廊...”等一系列語言命令,它需要分析指令中的物體和動(dòng)作指令,在只能看到一部分場景內(nèi)容的情況下,腦補(bǔ)整個(gè)全局圖,并正確執(zhí)行命令。所以這是一個(gè)結(jié)合 NLP 和 CV 兩大領(lǐng)域,一項(xiàng)非常有挑戰(zhàn)性的任務(wù)。

難點(diǎn)
雖然我們理解這項(xiàng)任務(wù)好像不是很難,但是放到 AI 智能體上并不像我們理解起來那么容易。對(duì) AI 智能體來說,這項(xiàng)任務(wù)通常存在三大難點(diǎn):
難點(diǎn)一:跨模態(tài)的基標(biāo)對(duì)準(zhǔn)(cross-modal grounding);簡單解釋就是將NLP 的指令與 CV 場景相對(duì)應(yīng)。
難點(diǎn)二:不適定反饋(ill-posed feedback);就是通常一句話里面包含多個(gè)指令,但并不是每個(gè)指令都會(huì)進(jìn)行反饋,只有最終完成任務(wù)才有反饋,所以難以判斷智能體是否完全按照指令完成任務(wù)。
難點(diǎn)三:泛化能力問題;由于環(huán)境差異大,VLN 的模型難以泛化。
那這篇論文中,作者又做了哪些工作,獲得了評(píng)委們的一致青睞,獲得了 3 個(gè) Strong Accept 呢?方法來了~
方法
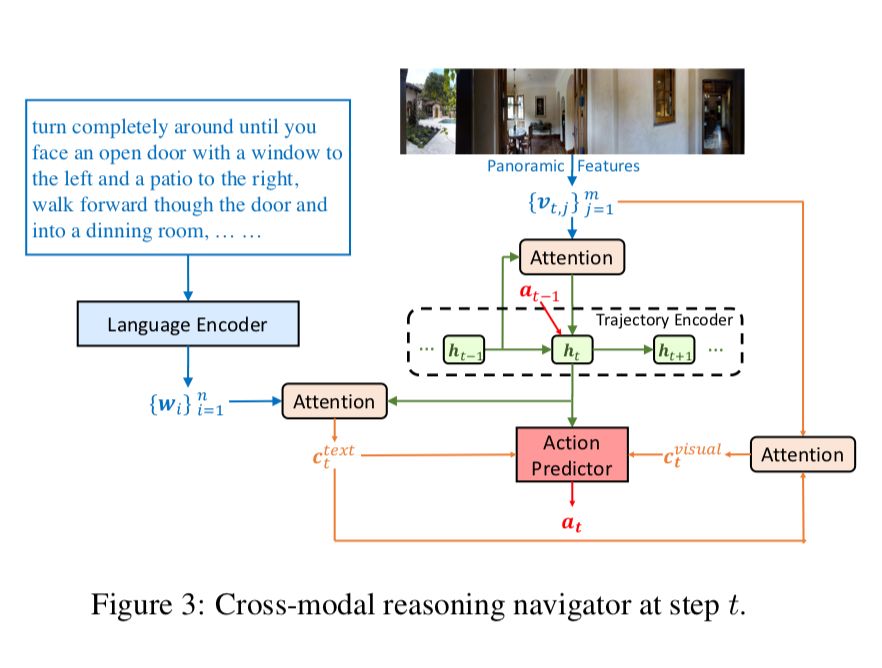
1、RCM(Reinforced Cross-Modal Matching)模型
針對(duì)第一和第二難點(diǎn),論文提出了一種全新的強(qiáng)化型跨模態(tài)匹配(RCM)方法,用強(qiáng)化學(xué)習(xí)方法將局部和全局的場景聯(lián)系起來。
RCM 模型主要由兩個(gè)模塊構(gòu)成:推理導(dǎo)航器和匹配度評(píng)估器。如圖所示,通過訓(xùn)練其中綠色的導(dǎo)航器,讓它學(xué)會(huì)理解局部的跨模態(tài)場景,推斷潛在的指令,并生成一系列動(dòng)作序列。另外,論文還設(shè)置了匹配度評(píng)估器(Matching Critic)和循環(huán)重建獎(jiǎng)勵(lì)機(jī)制,用于評(píng)價(jià)原始指令與導(dǎo)航器生成的軌跡之間的對(duì)齊情況,幫助智能體理解語言輸入,并且懲罰不符合語言指令的軌跡。

以上的方法僅僅是解決了第一個(gè)難點(diǎn),所以論文還提出了一個(gè)由環(huán)境驅(qū)動(dòng)的外部獎(jiǎng)勵(lì)函數(shù),用于度量每個(gè)動(dòng)作成功的信合和導(dǎo)航器之間的誤差。
2、SIL(Self-supervised Imitation Learning)方法
為了解決第三個(gè)難點(diǎn),論文提出了一種自監(jiān)督模仿學(xué)習(xí)(Self-supervised Imitation Learning, SIL),其目的是讓智能體能夠自主的探索未知的環(huán)境。其具體做法是,對(duì)于一個(gè)從未見過的語言指令和目標(biāo)位置,導(dǎo)航器會(huì)得到一組可能的軌跡并將其中最優(yōu)的軌跡(采用匹配度評(píng)估器)保存到緩沖區(qū)中,然后匹配度評(píng)估器會(huì)使用之前介紹的循環(huán)重建獎(jiǎng)勵(lì)機(jī)制來評(píng)估軌跡,SIL方法可以與多種學(xué)習(xí)方法想結(jié)合,通過模仿自己之前的最佳表現(xiàn)來得到更優(yōu)的策略。

測試結(jié)果
1、測試集:R2R(Room-to-Room)Dataset;視覺語言導(dǎo)航任務(wù)中一個(gè)真實(shí) 3D環(huán)境的數(shù)據(jù)集,包含 7189 條路徑,捕捉了大部分的視覺多樣性,21567 條人工注釋指令,其平均長度為 29 個(gè)單詞。
2、評(píng)價(jià)指標(biāo)
PL:路徑長度(Path Length)
NE:導(dǎo)航誤差(Navigation Error)
OSR:Oracle 成功率(Oracle Success Rate)
SR:成功率( Success Rate)
SPL:反向路徑長度的加權(quán)成功率(Success rate weighted by inverse Path Length)
3、實(shí)驗(yàn)對(duì)比:與 SOTA 進(jìn)行對(duì)比,此前在 R2R 數(shù)據(jù)集上效果最優(yōu)的方法。
Baseline:Random、seq2seq、RPA 和 Speaker-Follower。

測試結(jié)果顯示,RCM 模型的效果在 SPL 指標(biāo)上明顯優(yōu)于當(dāng)前的最優(yōu)結(jié)果。

并且在 SIL 方法學(xué)習(xí)后,學(xué)習(xí)效率也有明顯的提高,在見過和未見過的場景驗(yàn)證集上,并可視化了其內(nèi)部獎(jiǎng)勵(lì)指標(biāo)。

論文地址:
https://arxiv.org/pdf/1811.10092.pdf

-
智能體
+關(guān)注
關(guān)注
1文章
261瀏覽量
10945 -
自然語言
+關(guān)注
關(guān)注
1文章
291瀏覽量
13594 -
nlp
+關(guān)注
關(guān)注
1文章
490瀏覽量
22468
原文標(biāo)題:CVPR 2019審稿滿分論文:中國博士提出融合CV與NLP的視覺語言導(dǎo)航新方法
文章出處:【微信號(hào):rgznai100,微信公眾號(hào):rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄

大華股份榮獲中國創(chuàng)新方法大賽一等獎(jiǎng)
基于遺傳算法的QD-SOA設(shè)計(jì)新方法

一種降低VIO/VSLAM系統(tǒng)漂移的新方法
NaVILA:加州大學(xué)與英偉達(dá)聯(lián)合發(fā)布新型視覺語言模型
大華股份榮獲2024年中國創(chuàng)新方法大賽一等獎(jiǎng)
基于視覺語言模型的導(dǎo)航框架VLMnav
利用全息技術(shù)在硅晶圓內(nèi)部制造納米結(jié)構(gòu)的新方法
一種將NeRFs應(yīng)用于視覺定位任務(wù)的新方法

SLAM:機(jī)器人如何在未知地形環(huán)境中進(jìn)行導(dǎo)航
一種完全分布式的點(diǎn)線協(xié)同視覺慣性導(dǎo)航系統(tǒng)
一種半動(dòng)態(tài)環(huán)境中的定位方法
保護(hù)4-20 mA,±20-mA模擬輸入的新方法

實(shí)踐JLink 7.62手動(dòng)增加新MCU型號(hào)支持新方法
一種無透鏡成像的新方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論