") 基于計算機(jī)視覺的自動搜索圖像語義分割架構(gòu)
基于計算機(jī)視覺的自動搜索圖像語義分割架構(gòu)
近日,斯坦福大學(xué)李飛飛組的研究者提出了 Auto-DeepLab,其在圖像語義分割問題上超越了很多業(yè)內(nèi)最佳模型,甚至可以在未經(jīng)過預(yù)訓(xùn)練的情況下達(dá)到預(yù)訓(xùn)練模型的表現(xiàn)。Auto-DeepLab 開發(fā)出與分層架構(gòu)搜索空間完全匹配的離散架構(gòu)的連續(xù)松弛,顯著提高架構(gòu)搜索的效率,降低算力需求。
深度神經(jīng)網(wǎng)絡(luò)已經(jīng)在很多人工智能任務(wù)上取得了成功,包括圖像識別、語音識別、機(jī)器翻譯等。雖然更好的優(yōu)化器 [36] 和歸一化技術(shù) [32, 79] 在其中起了重要作用,但很多進(jìn)步要?dú)w功于神經(jīng)網(wǎng)絡(luò)架構(gòu)的設(shè)計。在計算機(jī)視覺中,這適用于圖像分類和密集圖像預(yù)測。
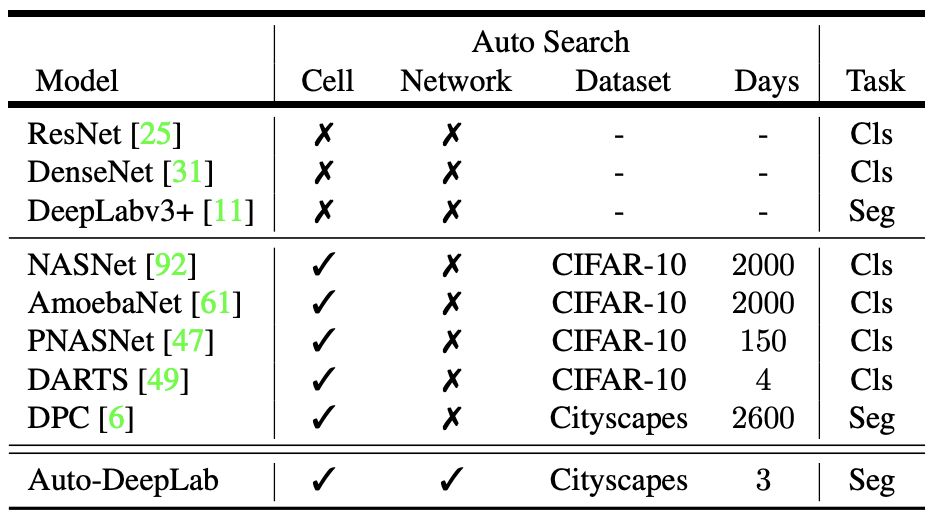
表 1:本研究提出的模型 Auto-DeepLab 和其它雙層 CNN 架構(gòu)的對比。主要區(qū)別有:(1) Auto-DeepLab 直接搜索用于語義分割的 CNN 架構(gòu);(2) Auto-DeepLab 搜索網(wǎng)絡(luò)級架構(gòu)和單元級架構(gòu);(3) Auto-DeepLab 的高效搜索在一個 P100 GPU 上僅需 3 天。
最近,在AutoML和 AI 民主化的影響下,人們對自動化設(shè)計神經(jīng)網(wǎng)絡(luò)架構(gòu)產(chǎn)生了極大興趣,自動化設(shè)計神經(jīng)網(wǎng)絡(luò)無需嚴(yán)重依賴專家經(jīng)驗(yàn)和知識。更重要的是,去年神經(jīng)架構(gòu)搜索(NAS)成功找到了在大規(guī)模圖像分類任務(wù)上超越人類設(shè)計架構(gòu)的網(wǎng)絡(luò)架構(gòu) [92, 47, 61]。
圖像分類對 NAS 來說是一個很好的起點(diǎn),因?yàn)樗亲罨A(chǔ)且研究最深入的高級識別任務(wù)。此外,該研究領(lǐng)域存在具有規(guī)模相對較小的基準(zhǔn)數(shù)據(jù)集(如 CIFAR-10),從而減少了計算量并加快了訓(xùn)練速度。然而,圖像分類不應(yīng)該是 NAS 的終點(diǎn),現(xiàn)下的成功表明它可以擴(kuò)展至要求更高的領(lǐng)域。在本文中,作者研究了用于語義圖像分割的神經(jīng)架構(gòu)搜索。這是一項(xiàng)重要的計算機(jī)視覺任務(wù),它為輸入圖像的每個像素分配標(biāo)簽,如「人」或「自行車」。
簡單地移植圖像分類的方法不足以進(jìn)行語義分割。在圖像分類中,NAS 通常使用從低分辨率圖像到高分辨率圖像的遷移學(xué)習(xí) [92],而語義分割的最佳架構(gòu)必須在高分辨率圖像上運(yùn)行。這表明,本研究需要:(1) 更松弛、更通用的搜索空間,以捕捉更高分辨率導(dǎo)致的架構(gòu)變體;(2) 更高效的架構(gòu)搜索技術(shù),因?yàn)楦叻直媛市枰挠嬎懔扛蟆?/p>
作者注意到,現(xiàn)代 CNN 設(shè)計通常遵循兩級分層結(jié)構(gòu),其中外層網(wǎng)絡(luò)控制空間分辨率的變化,內(nèi)層單元級架構(gòu)管理特定的分層計算。目前關(guān)于 NAS 的絕大多數(shù)研究都遵循這個兩級分層設(shè)計,但只自動化搜索內(nèi)層網(wǎng)絡(luò),而手動設(shè)計外層網(wǎng)絡(luò)。這種有限的搜索空間對密集圖像預(yù)測來說是一個問題,密集圖像預(yù)測對空間分辨率變化很敏感。因此在本研究中,作者提出了一種格子狀的網(wǎng)絡(luò)級搜索空間,該搜索空間可以增強(qiáng) [92] 首次提出的常用單元級搜索空間,以形成分層架構(gòu)搜索空間。本研究的目標(biāo)是聯(lián)合學(xué)習(xí)可重復(fù)單元結(jié)構(gòu)和網(wǎng)絡(luò)結(jié)構(gòu)的良好組合,用于語義圖像分割。
就架構(gòu)搜索方法而言,強(qiáng)化學(xué)習(xí)和進(jìn)化算法往往是計算密集型的——即便在低分辨率數(shù)據(jù)集 CIFAR-10 上,因此它們不太適合語義圖像分割任務(wù)。受 NAS 可微分公式 [68, 49] 的啟發(fā),本研究開發(fā)出與分層架構(gòu)搜索空間完全匹配的離散架構(gòu)的連續(xù)松弛。分層架構(gòu)搜索通過隨機(jī)梯度下降實(shí)施。當(dāng)搜索終止時,最好的單元架構(gòu)會被貪婪解碼,而最好的網(wǎng)絡(luò)架構(gòu)會通過維特比算法得到有效解碼。作者在從 Cityscapes 數(shù)據(jù)集中裁剪的 321×321 圖像上直接搜索架構(gòu)。搜索非常高效,在一個 P100 GPU 上僅需 3 天。
作者在多個語義分割基準(zhǔn)數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn),包括 Cityscapes、PASCAL VOC 2012 和 ADE20K。在未經(jīng) ImageNet 預(yù)訓(xùn)練的情況下,最佳 Auto-DeepLab 模型在 Cityscapes 測試集上的結(jié)果超過 FRRN-B 8.6%,超過 GridNet 10.9%。在利用 Cityscapes 粗糙標(biāo)注數(shù)據(jù)的實(shí)驗(yàn)中,Auto-DeepLab 與一些經(jīng)過 ImageNet 預(yù)訓(xùn)練的當(dāng)前最優(yōu)模型的性能相近。值得注意的是,本研究的最佳模型(未經(jīng)過預(yù)訓(xùn)練)與 DeepLab v3+(有預(yù)訓(xùn)練)的表現(xiàn)相近,但在 MultiAdds 中前者的速度是后者的 2.23 倍。另外,Auto-DeepLab 的輕量級模型性能僅比 DeepLab v3+ 低 1.2%,而參數(shù)量需求卻少了 76.7%,在 MultiAdds 中的速度是 DeepLab v3+ 的 4.65 倍。在 PASCAL VOC 2012 和 ADE29K 上,Auto-DeepLab 最優(yōu)模型在使用極少數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練的情況下,性能優(yōu)于很多當(dāng)前最優(yōu)模型。
本論文主要貢獻(xiàn)如下:
這是首次將 NAS 從圖像分類任務(wù)擴(kuò)展到密集圖像預(yù)測任務(wù)的嘗試之一。
該研究提出了一個網(wǎng)絡(luò)級架構(gòu)搜索空間,它增強(qiáng)和補(bǔ)充了已經(jīng)得到深入研究的單元級架構(gòu)搜索,并對網(wǎng)絡(luò)級和單元級架構(gòu)進(jìn)行更具挑戰(zhàn)性的聯(lián)合搜索。
本研究提出了一種可微的連續(xù)方式,保證高效運(yùn)行兩級分層架構(gòu)搜索,在一個 GPU 上僅需 3 天。
在未經(jīng) ImageNet 預(yù)訓(xùn)練的情況下,Auto-DeepLab 模型在 Cityscapes 數(shù)據(jù)集上的性能顯著優(yōu)于 FRRN-B 和 GridNet,同時也和 ImageNet 預(yù)訓(xùn)練當(dāng)前最佳模型性能相當(dāng)。在 PASCAL VOC 2012 和 ADE20K 數(shù)據(jù)集上,最好的 Auto-DeepLab 模型優(yōu)于多個當(dāng)前最優(yōu)模型。
論文:Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation

論文地址:https://arxiv.org/pdf/1901.02985v1.pdf
摘要:近期,在圖像分類問題上神經(jīng)架構(gòu)搜索(NAS)確定的神經(jīng)網(wǎng)絡(luò)架構(gòu)能力超越人類設(shè)計的網(wǎng)絡(luò)。本論文將研究用于語義圖像分割的 NAS,語義圖像分割是將語義標(biāo)簽分配給圖像中每個像素的重要計算機(jī)視覺任務(wù)。現(xiàn)有的研究通常關(guān)注搜索可重復(fù)的單元結(jié)構(gòu),對控制空間分辨率變化的外部網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行人工設(shè)計。這種做法簡化了搜索空間,但對于具備大量網(wǎng)絡(luò)級架構(gòu)變體的密集圖像預(yù)測而言,該方法帶來的問題很多。因此,該研究提出在搜索單元結(jié)構(gòu)之外還要搜索網(wǎng)絡(luò)級架構(gòu),從而形成一個分層架構(gòu)搜索空間。本研究提出一種包含多種流行網(wǎng)絡(luò)設(shè)計的網(wǎng)絡(luò)級搜索空間,并提出一個公式來進(jìn)行基于梯度的高效架構(gòu)搜索(在 Cityscapes 圖像上使用 1 個 P100 GPU 僅需 3 天)。本研究展示了該方法在較難的 Cityscapes、PASCAL VOC 2012 和 ADE20K 數(shù)據(jù)集上的效果。在不經(jīng)任何 ImageNet 預(yù)訓(xùn)練的情況下,本研究提出的專用于語義圖像分割的架構(gòu)獲得了當(dāng)前最優(yōu)性能。
4 方法
這部分首先介紹了精確匹配上述分層架構(gòu)搜索的離散架構(gòu)的連續(xù)松弛,然后討論了如何通過優(yōu)化執(zhí)行架構(gòu)搜索,以及如何在搜索終止后解碼離散架構(gòu)。
4.2 優(yōu)化
連續(xù)松弛的作用在于控制不同隱藏狀態(tài)之間連接強(qiáng)度的標(biāo)量現(xiàn)在也是可微計算圖的一部分。因此可以使用梯度下降對其進(jìn)行高效優(yōu)化。作者采用了 [49] 中的一階近似,將訓(xùn)練數(shù)據(jù)分割成兩個單獨(dú)的數(shù)據(jù)集 trainA 和 trainB。優(yōu)化在以下二者之間交替進(jìn)行:
1. 用 ?_w L_trainA(w, α, β) 更新網(wǎng)絡(luò)權(quán)重 w;
2. 用 ?_(α,β) L_trainB(w, α, β) 更新架構(gòu) α, β。
其中損失函數(shù) L 是在語義分割小批量上計算的交叉熵。
4.3 解碼離散架構(gòu)
單元架構(gòu)
和 [49] 一樣,本研究首先保留每個構(gòu)造塊的兩個最強(qiáng)前任者(predecessor),然后使用 argmax 函數(shù)選擇最可能的 operator,從而解碼離散單元架構(gòu)。
網(wǎng)絡(luò)架構(gòu)
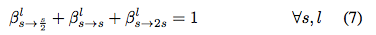
公式 7 本質(zhì)上表明圖 1 中每個藍(lán)色節(jié)點(diǎn)處的「outgoing 概率」的總和為 1。事實(shí)上,β 可被理解為不同「時間步」(層數(shù))中不同「狀態(tài)」(空間分辨率)之間的「transition 概率」。本研究的目標(biāo)是從頭開始找到具備「最大概率」的的路徑。在實(shí)現(xiàn)中,作者可以使用經(jīng)典維特比算法高效解碼該路徑。
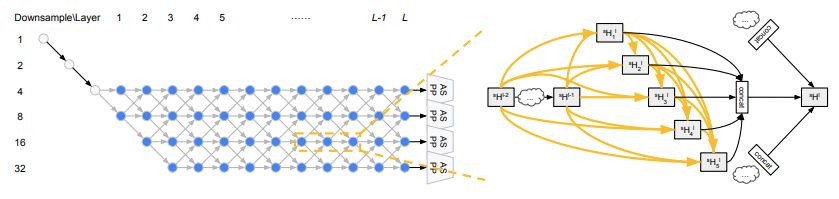
圖 1:左圖是 L = 12 時的網(wǎng)絡(luò)級搜索空間。灰色節(jié)點(diǎn)表示固定的「stem」層,沿著藍(lán)色節(jié)點(diǎn)形成的路徑表示候選網(wǎng)絡(luò)級架構(gòu)。右圖展示了搜索過程中,每個單元是一個密集連接的結(jié)構(gòu)。
5 實(shí)驗(yàn)結(jié)果
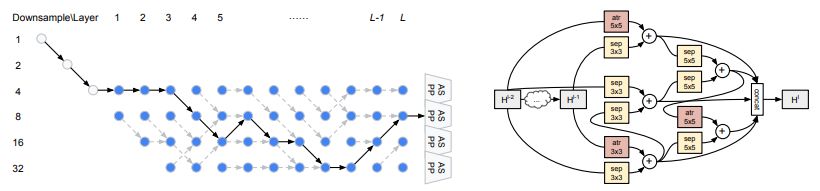
圖 3:使用本研究提出的分層神經(jīng)架構(gòu)搜索方法找到的最優(yōu)網(wǎng)絡(luò)架構(gòu)和單元架構(gòu)。灰色虛線箭頭表示每個節(jié)點(diǎn)處具備最大 β 值的連接。atr 指空洞卷積(atrous convolution),sep 指深度可分離卷積(depthwise-separable convolution)。
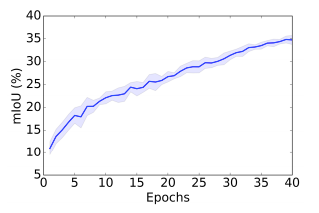
圖 4:在 10 次隨機(jī)試驗(yàn)中,40 個 epoch 中架構(gòu)搜索優(yōu)化的驗(yàn)證準(zhǔn)確率。
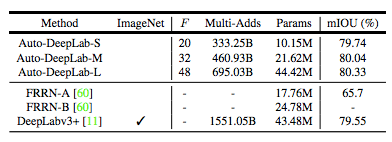
表 2:不同 Auto-DeepLab 模型變體在 Cityscapes 驗(yàn)證集上的結(jié)果。F:控制模型容量的 filter multiplier。所有 Auto-DeepLab 模型都是從頭開始訓(xùn)練,且在推斷過程中使用單尺度輸入。
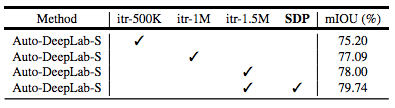
表 3:Cityscapes 驗(yàn)證集結(jié)果。研究采用不同的訓(xùn)練迭代次數(shù)(50 萬、100 萬與 150 萬次迭代)和 SDP(Scheduled Drop Path)方法進(jìn)行實(shí)驗(yàn)。所有模型都是從頭訓(xùn)練的。
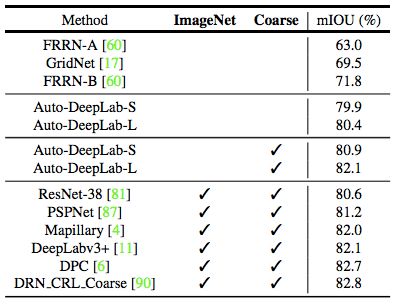
表 4:模型在推斷過程中使用多尺度輸入時在 Cityscapes 測試集上的結(jié)果。ImageNet:在 ImageNet 上預(yù)訓(xùn)練的模型。Coarse:利用粗糙注釋的模型。
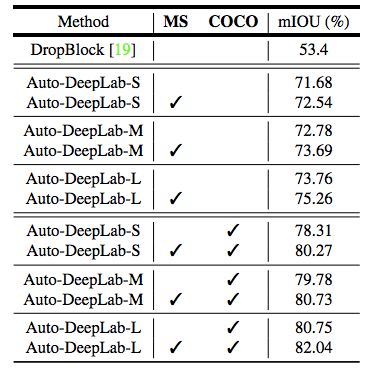
表 5:PASCAL VOC 2012 驗(yàn)證集結(jié)果。本研究采用多尺度推理(MS,multi-scale inference)和 COCO 預(yù)訓(xùn)練檢查點(diǎn)(COCO)進(jìn)行實(shí)驗(yàn)。在未經(jīng)任何預(yù)訓(xùn)練的情況下,本研究提出的最佳模型(Auto-DeepLab-L)超越了 DropBlock 20.36%。所有的模型都沒有使用 ImageNet 圖像做預(yù)訓(xùn)練。
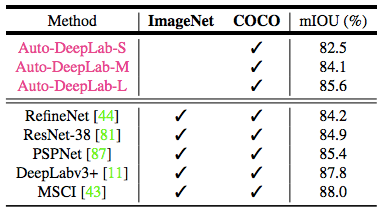
表 6:PASCAL VOC 2012 測試集結(jié)果。本研究提出的 AutoDeepLab-L 取得了可與眾多在 ImageNet 和 COCO 數(shù)據(jù)集上預(yù)訓(xùn)練的頂級模型相媲美的結(jié)果。
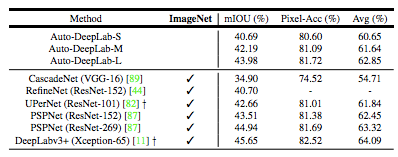
表 7:ADE20K 驗(yàn)證集結(jié)果。在推斷過程中使用多尺度輸入。? 表示結(jié)果分別是從他們最新的模型 zoo 網(wǎng)站獲得的。ImageNet:在 ImageNet 上預(yù)訓(xùn)練的模型。Avg:mIOU 和像素準(zhǔn)確率的均值。
圖 5:在 Cityscapes 驗(yàn)證集上的可視化結(jié)果。最后一行展示了本研究提出方法的故障模式,模型將一些較難的語義類別混淆了,如人和騎車的人。
圖 6:在 ADE20K 驗(yàn)證集上的可視化結(jié)果。最后一行展示了本研究提出方法的故障模式,模型無法分割非常細(xì)粒度的對象(如椅子腿),且將較難的語義類別混淆了(如地板和地毯)
-
人工智能
+關(guān)注
關(guān)注
1804文章
48677瀏覽量
246385 -
計算機(jī)視覺
+關(guān)注
關(guān)注
9文章
1706瀏覽量
46563
原文標(biāo)題:李飛飛等人提出Auto-DeepLab:自動搜索圖像語義分割架構(gòu)
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
深度解析計算機(jī)視覺的圖像分割技術(shù)

計算機(jī)圖形學(xué)總覽:圖像和圖像的概念辨析
聚焦語義分割任務(wù),如何用卷積神經(jīng)網(wǎng)絡(luò)處理語義圖像分割?
李飛飛等人提出Auto-DeepLab:自動搜索圖像語義分割架構(gòu)
深度學(xué)習(xí)改變的五大計算機(jī)視覺技術(shù)
計算機(jī)視覺中的重要研究方向
基于深度神經(jīng)網(wǎng)絡(luò)的圖像語義分割方法

跨圖像關(guān)系型KD方法語義分割任務(wù)-CIRKD







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論