 AI與RTC中結合點有那四大技術應用方向的詳細資料說明
AI與RTC中結合點有那四大技術應用方向的詳細資料說明
大到無人駕駛、智能物流,小到人們出國旅游手上拿著的翻譯機,AI 早已從曾經的天馬行空變得觸手可及。AI 也成了很多公司未來的核心戰略,并應用到了產品中。其實,在 RTC 領域亦是如此。
提到 RTC 中的 AI,你可能還會記得今年 RTC 領域中的熱門話題超分辨率。前幾天,據說某款手機已經將其應用于調節照片遠景放大后的清晰度上。我們也曾有不止一位演講人,曾在 RTC 2018 中分享過將超分辨率應用于實時音視頻中的研究。不過,超分辨率只是 AI 在 RTC 中的一個應用而已。
概括來講,目前 AI 與 RTC 的結合點有四個:
語音分析:使用機器學習分析,將實時音視頻中的語音轉錄為文本、字幕。
語音機器人:在對話框中與用戶交互的語音機器人,輸入與輸出皆通過語音,比如Siri、Alexa、Cortana等。
RTC 優化:用于提高服務質量或性能的機器學習算法模型。
1
語音分析(Speech Analytics)
如果你對今年 Google I/O 有印象,你可能還會記得官方曾經做過一段演示,YouTube 可以根據視頻的圖像和聲音,將視頻內容翻譯并以字幕形式顯示出來。而且,Google 在語音識別、分析方面做了優化,即使視頻中口音模糊,也能根據視頻內容進行智能翻譯,最終顯示為字幕。應用于其中的一個重要技術方向就是語音分析。
在 RTC 中,語音分析主要的應用形式包括電話中心智能語音交互、語音轉文本、翻譯等等。語音分析是一個相對成熟的技術應用方向,也是一個多學科應用于實際的范例。它涉及了信號處理、模式識別、概率論和信息論、發聲機理和聽覺機理、深度學習等。就像 Google 所做的,我們可以將它應用于自己的視頻會議、視頻通話、直播連麥等一系列實時音視頻場景中。如果想快速實現,市場上有很多 API 可以幫助到你;如果你的團隊技術實力雄厚,那么也有幾個比較著名,也比較老的開源工具可以使用。
業界有不少公司都能提供語音分析功能,例如國內的訊飛、百度、搜狗等,再例如 Google Speech API 和 Facebook 推出的 wav2letter 等。Agora 開發者也完全可以基于 SDK 的接口與這些語音識別、分析服務結合,實現創新場景。
如果自研,那么也有不少可以參考的算法模型。例如這4個“歷史悠久”的語音識別相關的開源項目與非開源項目:HTK、CMU Sphinx、Julius、Kaldi。我們逐一簡單介紹下。
1. HTK
首先 HTK 并不是開源項目,它是由劍橋大學工程學院(Cambridge University Engineering Department ,CUED)的機器智能實驗室于1989年開發的,用于構建CUED的大詞匯量的語音識別系統。HTK 主要包括語音特征提取和分析工具、模型訓練工具、語音識別工具。1999年 HTK 被微軟收購。2015年 HTK 發布了3.5 Beta 版本,也是目前最新的版本。
2. CMU-Sphinx
CMU-Sphinx 是卡內基-梅隆大學(CarnegieMellon University,CMU)開發的一款開源的語音識別系統。它包括了一系列語音識別器和聲學模型訓練工具,被稱為第一個高性能的連續語音識別系統。Sphinx 的發展也很快,Sphinx4 已經用 Java 改寫,所以適合嵌入到Android平臺。
3. Julius
Julius 是日本京都大學和 Information-technology Promotion Agency 聯合開發的一個實用高效雙通道的大詞匯連續語音識別引擎。Julius 通過結合語言模型和聲學模型,可以很方便地建立一個語音識別系統。Julius 支持的語言模型包括:N-gram模型,以規則為基礎的語法和針對孤立詞識別的簡單單詞列表。它支持的聲學模型必須是以分詞為單位,且由HMM定義的。HMM 作為語音信號的一種統計模型,是語音識別技術的主流建模方法,正在語音處理各個領域中獲得廣泛的應用。Julius 由 C 語言開發,遵循GPL開源協議,能夠運行在 Linux、Windows、Mac:OS X、Solaris 以及其他Unix平臺。Julius 最新的版本采用模塊化的設計思想,使得各功能模塊可以通過參數配置。
4. Kaldi
Kaldi 是2009年由 JohnsHopkins University 開發的,剛開始項目代碼是基于HTK進行的開發,現在是 C++ 作為主要語言。Kaldi的維護和更新非常及時,幾乎每一、兩天就有新的 commits,而且在跟進學術研究的新算法方面也更加快速。國內外很多公司和研究機構也都在用 Kaldi。
上述幾種語音識別開源代碼是基礎的開源版本,基于這些版本誕生了不少衍生的版本,比如 Platypus、FreeSpeech、Vedics、NatI、Simon、Xvoice、Zanzibar、OpenIVR、Dragon Naturally Speaking等。
2
語音機器人
現在很多呼叫中心都引入了 IVR(互動式語音應答),顧客可在任何時間打電話獲取他們希望得到的信息,當遇到無法解決的問題時才轉入人工坐席。它可以提高服務質量、節省費用。
但它自身也存在著問題。你可能也遇到過,有時候打給一個客戶中心,語音提供了多個選項讓你選擇,可當你聽到第五個之后,就忘了之前的選項都有什么,以至于還要再聽一遍。所以很多呼叫中心會把菜單設計成更少選項更多層級。但這會讓用戶的交互過程變得更長。
所以語音機器人開始成為呼叫中心的新選擇(也可能有人管它叫智能客服或其它名字)。用戶只需要說出想要什么,它就能根據關鍵信息篩選出用戶想要的信息,就好像電話那頭多了一個 Siri。
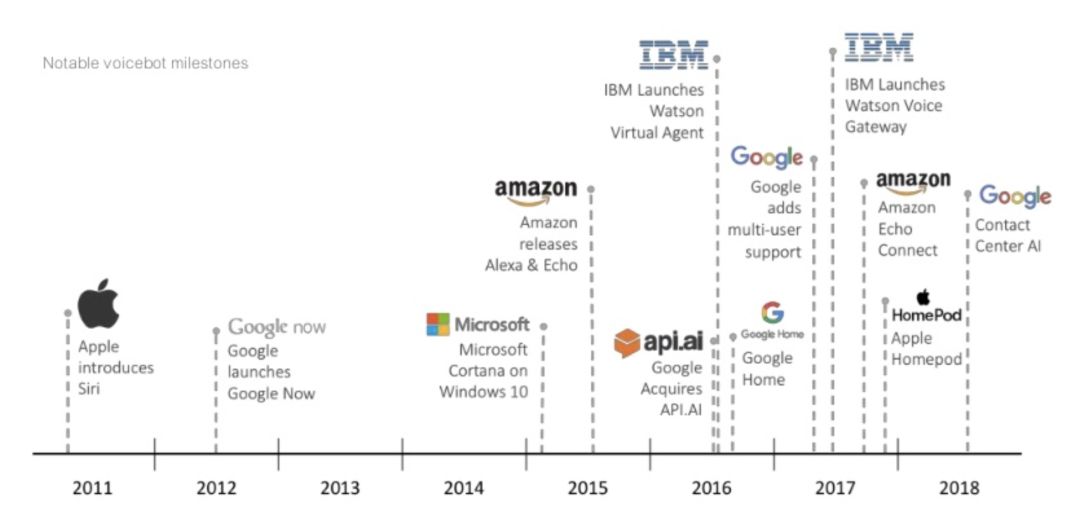
當然,Siri 也是是除了呼叫中心以外,語音機器人的另一種應用形式。目前已經有很多公司都推出了相應的產品或接口(如上圖所示)。不過,要建立一個能與人自然交流的語音機器人,從架構、音頻處理到算法模型的訓練等,需要面對很多問題:
處理噪音
處理方言和自定義詞匯表
語音驗證
處理延遲
使用 SSML 進行更自然的語音合成
模型訓練
3
計算機視覺
現在計算機視覺的應用應該已經很常見了,例如:
面部識別
物體檢測
手勢識別
情感分析
我們曾在年初的時候分享過兩篇文章,講述了如何結合 WebRTC 與 TensorFlow 實現物體識別,這是一位開發者的實驗。大體過程是,每秒將視頻圖像經由 HTTP 傳輸到服務器端,然后通過服務器端的機器學習算法模型處理后得出檢測結果,再反饋給本地,具體代碼可以看我們之前的文章。
不過這個實驗仍然存在很多的局限,如果圖像質量過高,會需要更多傳輸、處理的時間,這會影響檢測的實時性。所以,后來有人提出了可以在本地進行圖像識別。
上圖是一個基本架構,如果你感興趣,也可以嘗試一下。它利用了 google 的 AIY 硬件工具來運行 DNN。也就是說,當你采集到視頻之后,可以在本地進行處理,那么就無需擔心圖像識別的實時性問題了。
4
對 RTC 的優化
利用 AI 可以在實時音視頻方面做很多事情,例如利用超分辨率來提升實時視頻中模糊圖像的細節,給用戶呈現更高清的視頻效果,提高視覺體驗;同時,由于網絡傳輸線路上有丟包,接收的數據有失真,所以 AI 也被用來做算法補償,提升傳輸質量。
超分辨率是通過深度學習來提高其分辨率,進而改善實時視頻圖像質量的技術。為什么需要這項技術呢?因為盡管現在用戶都在高分辨率模式下獲取圖像,但在實時傳輸過程中,視頻編碼器可能會降低分辨率,以匹配可用帶寬和性能限制。由于這個處理機制,導致圖像質量通常會低于實際拍攝的質量。而超分辨率的目的就是將視頻質量恢復到原始狀態。
超分辨率在整個實時音視頻傳輸過程中屬于后處理中的一步。視頻源經過編碼在網絡上傳輸,解碼器收到后經過解碼出來是一個相對模糊的圖像,經過超分辨率處理把細節提升或者放大,再顯示出來。
現在很多的實時視頻場景都發生在移動設備上,所以對于一個深度學習算法模型來講,需要模型體量盡量要小,這就需要面對三個主要的挑戰:
模型能夠實時運行于移動設備上,且盡量降低功耗,避免引起發熱等問題。
模型小,但性能要好,可以得到足夠好的結果。
訓練要能夠基于比較合理數量的數據集。
我司的首席科學家鐘聲曾在 上海的 DevFest 活動和美國的 Kranky Geek 上分享過相關話題的演講。如果你希望深入了解,可以查看我們過去的分享。
除了超分辨率,開發者們還可以利用無監督學習來分析通過 WebRTC 的RTCStats接口收集到的數據,從而來確定影響通話質量的原因。也可以用 TensorFlow 來分析并規范化 MOS 數據。
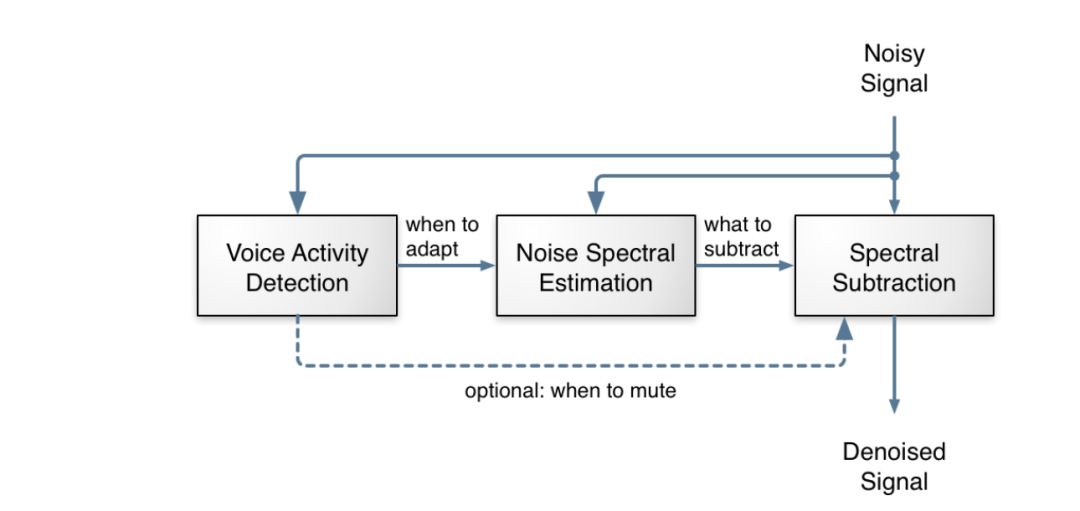
上圖所示是一個常規的降噪算法的處理邏輯,但在以后,,Mozilla 曾推出過一個 RNNoise Project,利用了深度學習,幫助 WebRTC 用戶,特別是在嘈雜環境中進行多方通話的用戶實現更好的降噪效果。他們也在官方提供了一個 Sample,與 Speexdsp 的降噪效果進行對比。在 Sample 中,他們模擬了人在馬路旁、咖啡館中、車上的通話效果,然后用不同的方式進行降噪處理。你會明顯聽出,通過 RNNoise 降噪后,無人說話時幾乎聽不到噪聲,而在有人說話時,還是會有輕微的噪音摻雜進來。如果你感興趣,可以去搜搜看,體驗一下。你可以在 xiph 的 Github 中找到它的代碼。盡管這只是一個研究項目,但提供了一種很好的改進思路。
盡管舉了這么多的研究案例與開源項目,但 AI 在 RTC 行業的應用還只是剛剛開始。
-
AI
+關注
關注
87文章
34146瀏覽量
275297 -
RTC
+關注
關注
2文章
607瀏覽量
68274 -
機器學習
+關注
關注
66文章
8490瀏覽量
134062
原文標題:AI 在 RTC 中的四大技術應用方向
文章出處:【微信號:shengwang-agora,微信公眾號:聲網Agora】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Keil C和Proteus結合使用的設計及開發實例詳細資料說明
運算放大器中接電容有什么樣的作用詳細資料說明

UART中的硬件流控RTS與CTS的知識點詳細資料說明

在寫Verilog時對時序約束的四大步驟的詳細資料說明
光電的知識點和單位運用等詳細資料說明







 工商網監
工商網監
評論