") SDNet成為目前世界上唯一在CoQA領(lǐng)域內(nèi)數(shù)據(jù)集上F1得分超過80%的模型,達(dá)到80.7%
SDNet成為目前世界上唯一在CoQA領(lǐng)域內(nèi)數(shù)據(jù)集上F1得分超過80%的模型,達(dá)到80.7%

微軟語音與對話研究團(tuán)隊(duì)開發(fā)的SDNet,在面向公共數(shù)據(jù)集CoQA的問答對話系統(tǒng)模型性能挑戰(zhàn)賽中刷新最佳性能紀(jì)錄,成功奪冠!SDNet成為目前世界上唯一在CoQA領(lǐng)域內(nèi)數(shù)據(jù)集上F1得分超過80%的模型,達(dá)到80.7%。
近日,微軟語音與對話研究團(tuán)隊(duì)在斯坦福機(jī)器對話式問答數(shù)據(jù)挑戰(zhàn)賽CoQA Challenge中奪冠,并且單模型和集成模型分別位列第二和第一,讓機(jī)器閱讀理解向著人類水平又靠近了一步。
這也是繼語音識別、機(jī)器翻譯等成果之后,微軟取得的又一項(xiàng)好成績。
微軟研究人員將自注意力模型和外部注意力相結(jié)合,并且用新的方法整合了谷歌BERT語境模型,構(gòu)建了一個(gè)基于注意力的會話式問答深度神經(jīng)網(wǎng)絡(luò)SDNet,更有效地理解文本和對話歷史。
一直以來,微軟研究人員都有在機(jī)器閱讀理解中使用自注意力模型加外部注意力的想法,終于在這項(xiàng)工作中首次得以實(shí)現(xiàn)。
CoQA競賽:更接近人類對話的機(jī)器問答挑戰(zhàn)賽
CoQA是面向建立對話式問答系統(tǒng)的大型數(shù)據(jù)集,CoQA挑戰(zhàn)的目標(biāo)是衡量機(jī)器對文本的理解能力,以及機(jī)器面向?qū)υ捴谐霈F(xiàn)的彼此相關(guān)的問題的回答能力的高低(CoQA的發(fā)音是“扣卡”)。
CoQA包含12.7萬個(gè)問題和答案,這些內(nèi)容是從8000多個(gè)對話中收集而來的。每組對話都是通過眾籌方式,以真人問答的形式在聊天中獲取的。
CoQA的獨(dú)特之處在于:
數(shù)據(jù)集中的問題是對話式的
答案可以是自由格式的文本
每個(gè)答案還附有對話段落中相應(yīng)答案的理由
這些問題收集自七個(gè)不同的領(lǐng)域
CoQA 數(shù)據(jù)集旨在體現(xiàn)人類對話中的特質(zhì),追求答案的自然性和問答系統(tǒng)的魯棒性。在CoQA 中,答案沒有固定的格式,在問題中頻繁出現(xiàn)指代詞,而且有專門用于跨領(lǐng)域測試的數(shù)據(jù)集。
CoQA具備了許多現(xiàn)有閱讀理解數(shù)據(jù)集中不存在的挑戰(zhàn),比如共用參照和實(shí)用推理等。因此,CoQA Challenge 也更能反映人類真實(shí)對話的場景。
CoQA 與 SQuAD 兩個(gè)數(shù)據(jù)集對比:SQuAD 中約一半都是what型,CoAQ種類更多;SQuAD中沒有共識推斷,CoQA幾乎每組對話都需要進(jìn)行上下文理解推斷;SQuAD中所有答案均可從原文本中提取,CoQA中這一比例僅為66.8%。
此前,斯坦福大學(xué)的自然語言處理小組已經(jīng)先后發(fā)表了 SQuAD 和 SQuAD2.0 數(shù)據(jù)集。該數(shù)據(jù)集包含一系列文本和基于文本的問題、答案。針對該數(shù)據(jù)集提出的任務(wù)要求系統(tǒng)閱讀文本后判斷該問題是否可以從文本中得出答案,如果可以回答則從文本中截取某一片段做出回答。
目前,微軟語音與對話研究已經(jīng)把他們在CoQA Challenge上奪冠成果的預(yù)印本論文發(fā)在了Arxiv上。下面結(jié)合論文內(nèi)容,對該團(tuán)隊(duì)的實(shí)驗(yàn)方法和研究成果做簡單介紹。
結(jié)合自注意力模型和外部注意力,更有效理解文本和對話歷史
在本文中,我們提出了SDNet,一種基于語境注意力的會話問答的深度神經(jīng)網(wǎng)絡(luò)。我們的網(wǎng)絡(luò)源于機(jī)器閱讀理解模型,但具備幾個(gè)獨(dú)特的特征,來解決面向?qū)υ挼那榫忱斫鈫栴}。
首先,我們在對話和問題中同時(shí)應(yīng)用注意力和自我注意機(jī)制,更有效地理解文章和對話的歷史。其次,SDNet利用了NLP領(lǐng)域的最新突破性成果:比如BERT上下文嵌入Devlin等。
我們采用了BERT層輸出的加權(quán)和,以及鎖定的BERT參數(shù)。我們在前幾輪問題和答案之前加上了當(dāng)前問題,以納入背景信息。結(jié)果表明,每個(gè)部分都實(shí)現(xiàn)了顯著提高了預(yù)測準(zhǔn)確性的作用。
我們在CoQA數(shù)據(jù)集上對SDNet進(jìn)行了評估,結(jié)果在全局F1得分方面,比之前最先進(jìn)模型結(jié)果表現(xiàn)提升了1.6%(從75.0%至76.6%)。整體模型進(jìn)一步將F1得分提升至79.3%。此外,SDNet是有史以來第一個(gè)在CoQA的領(lǐng)域內(nèi)數(shù)據(jù)集上表現(xiàn)超過80%的模型。
實(shí)驗(yàn)方法與衡量指標(biāo)
我們在CoQA 上評估了我們的模型。在CoQA中,許多問題的答案需要理解之前的問題和答案,這對傳統(tǒng)的機(jī)器閱讀模型提出了挑戰(zhàn)。表1總結(jié)了CoQA中的領(lǐng)域分布。如圖所示,CoQA包含來自多個(gè)領(lǐng)域的段落,并且每個(gè)段落的平均問答超過15個(gè)。許多問題需要上下文的理解才能生成正確答案。
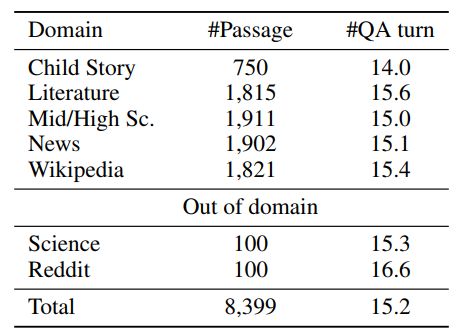
對于每個(gè)域內(nèi)數(shù)據(jù)集,開發(fā)集中有100個(gè)段落,測試集中有100個(gè)段落。其余的域內(nèi)數(shù)據(jù)集位于訓(xùn)練集中。測試集還包括所有域外段落。
基線模型和指標(biāo)
我們將SDNet與以下基線模型進(jìn)行了比較:PGNet(具有復(fù)制機(jī)制的Seq2Seq)、DrQA、DrQA +PGNet、BiDAF ++ Yatskar(2018)和FlowQA Huang等。 (2018)。與官方排行榜一致,我們使用F1作為評估指標(biāo),F(xiàn)1是在預(yù)測答案和基本事實(shí)之間的單詞級別的精度上的調(diào)和平均。
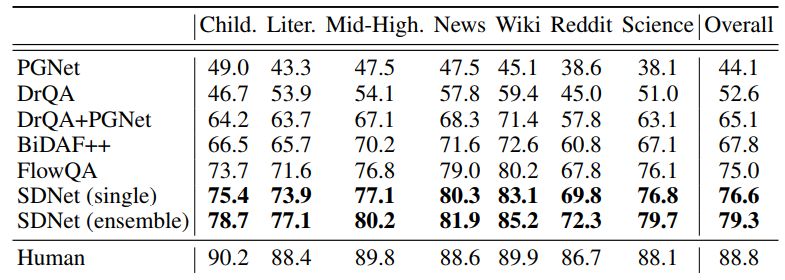
結(jié)果
上表所示為SDNet和基線模型的性能對比。如圖所示,使用SDNet的實(shí)現(xiàn)結(jié)果明顯好于基線模型。具體而言,與先前的CoQA FlowQA模型相比,單個(gè)SDNet模型將整體F1得分提高了1.6%。 Ensemble SDNet模型進(jìn)一步將整體F1得分提升了2.7%,SDNet是有史以來第一個(gè)在CoQA的領(lǐng)域內(nèi)數(shù)據(jù)集上表現(xiàn)超過80%的模型(80.7%)。
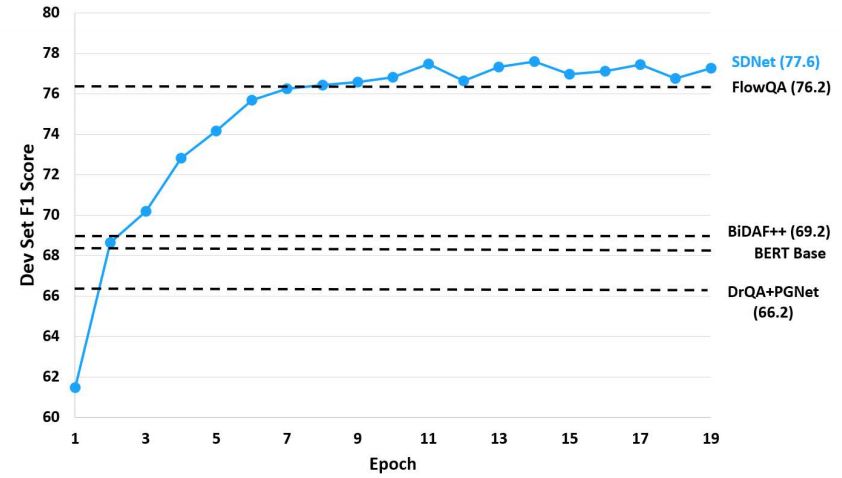
上圖所示為開發(fā)集隨epoch變化的F1得分情況。SDNet在第二個(gè)epoch之后的表現(xiàn)超越了兩個(gè)基線模型,并且僅在8個(gè)epoch后就實(shí)現(xiàn)了最優(yōu)秀的表現(xiàn)。

消融研究 (Ablation)
我們對SDNet模型進(jìn)行了消融研究,結(jié)果在上表中顯示。結(jié)果表明,正確使用上下文嵌入BERT是至關(guān)重要的。雖然移除BERT會使開發(fā)集的F1得分降低6.4%,但在未鎖定內(nèi)部權(quán)重的情況下加入BERT會使得F1得分降低13%。
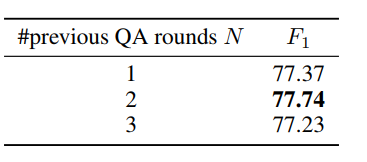
上下文歷史
在SDNet中,我們將當(dāng)前問題與前N輪問題和真實(shí)答案前置一致,來利用對話歷史記錄。我們試驗(yàn)了不同的N值的效果,并在表4中列出了結(jié)果。試驗(yàn)顯示,我們的模型的性能對N的設(shè)置不是非常敏感。最后,我們的最終模型設(shè)置N = 2。
未來:讓模型更接近于真人對話場景
我們提出了一種新的基于情境注意的深度神經(jīng)網(wǎng)絡(luò)SDNet,以解決對話問題的回答任務(wù)。通過在通過和對話歷史上利用注意力和自我關(guān)注,該模型能夠理解對話流并將其與消化段落內(nèi)容融合在一起。
此外,我們?nèi)谌肓俗匀徽Z言處理領(lǐng)域 BERT的最新突破,并以創(chuàng)新的方式利用它。與以前的方法相比,SDNet取得了卓越的成果。在公共數(shù)據(jù)集CoQA上,SDNet在整體F1指標(biāo)得分上的表現(xiàn)比之前最先進(jìn)的模型高1.6%。
縱觀CoQA Challenge排行榜,從今年8月21日到11月29日,短短3個(gè)月時(shí)間里,機(jī)器問答對話的總體成績就從52.6提升到79.3,距離人類水平88.8似乎指日可待。
“最后一公里往往是最難的,很難預(yù)測機(jī)器能否達(dá)到人類水平。”論文作者之一、微軟全球技術(shù)Fellow、負(fù)責(zé)微軟語音、自然語言和機(jī)器翻譯工作的黃學(xué)東博士告訴新智元。
未來,他們打算將SDNet模型應(yīng)用于具有大型語料庫或知識庫的開放域中,解決多循環(huán)問答問題,這類問題中,目標(biāo)段落可能是無法直接獲得的。這和人類世界中的問答的實(shí)際情況可能更為接近。
-
微軟
+關(guān)注
關(guān)注
4文章
6685瀏覽量
105742 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4814瀏覽量
103575 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1224瀏覽量
25445
原文標(biāo)題:微軟創(chuàng)CoQA挑戰(zhàn)新紀(jì)錄,最接近人類水平的NLP系統(tǒng)誕生
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
F1宣布與聯(lián)想集團(tuán)深化合作
F1?與亞馬遜云科技聯(lián)合推出全新在線體驗(yàn) 車迷可親手打造專屬賽道
AD7768與STM32F407進(jìn)行數(shù)據(jù)通信,SPI1讀取到的數(shù)據(jù)不完整,整體數(shù)據(jù)在字節(jié)上出現(xiàn)偏移,怎么解決?
聯(lián)想AI技術(shù)助力F1中國大獎(jiǎng)賽

NVIDIA推出開源物理AI數(shù)據(jù)集
RK3588開發(fā)板上部署DeepSeek-R1大模型的完整指南
DLPC410的datasheet寫明1bit的刷新率可以達(dá)到32KHz,在目前的EVM上可以實(shí)現(xiàn)嗎?
請問有沒有不在linux上對.pt模型向.kmodel轉(zhuǎn)換的教程呢?
GaNSafe–世界上最安全的GaN功率半導(dǎo)體

依托新的全球數(shù)據(jù)集識別人工智能領(lǐng)域新一輪涌現(xiàn)的杰出女性
世界上最貴的錫膏-金錫(Au80Sn20)

助力AIoT應(yīng)用:在米爾FPGA開發(fā)板上實(shí)現(xiàn)Tiny YOLO V4
激光軟釬焊技術(shù):SMT領(lǐng)域內(nèi)的現(xiàn)狀與未來發(fā)展趨勢(上)
在英特爾酷睿Ultra7處理器上優(yōu)化和部署Phi-3-min模型
chatglm2-6b在P40上做LORA微調(diào)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論