") 谷歌的智能助理Google Assistant 開啟了多語言支持
谷歌的智能助理Google Assistant 開啟了多語言支持
從今天開始,谷歌的智能助理可以同時說兩種語言了!這意味著雙語家庭可以用任何一種語言進(jìn)行查詢,而無需每次都更改設(shè)置。聽起來簡單,實現(xiàn)這一功能所需的技術(shù)可不簡單,谷歌的口語識別LangID技術(shù)已經(jīng)開發(fā)了5年!
使用 Google Assistant 的 Google Home Mini
多語家庭正變得越來越普遍,有一些研究發(fā)現(xiàn)多語人口已經(jīng)超過單語人口,而且這個數(shù)字還將繼續(xù)增長。隨著多語用戶數(shù)量的不斷增加,開發(fā)能夠同時支持多種語言的產(chǎn)品比以往任何時候都更加重要。
今天,谷歌的智能助理Google Assistant開啟了多語言支持,允許用戶同時使用兩種不同的語言進(jìn)行查詢,而無需返回語言設(shè)置。一旦用戶選擇了兩種支持的語言(目前支持的語言包括英語、西班牙語、法語、德語、意大利語和日語),他們就可以使用其中任一種語言與Google Assistant進(jìn)行對話,智能助理也會以同一種語言做出回復(fù)。
在此之前,用戶必須為智能助理選擇一種語言設(shè)置,每次想要使用另一種語言時都必須更改設(shè)置。但現(xiàn)在,對于多語家庭來說,與谷歌助理交流的體驗變得更加簡單方便了。
Google Assistant現(xiàn)在能夠識別語言、解釋查詢并使用正確的語言提供回復(fù),而無需用戶手動設(shè)置設(shè)置。
然而,實現(xiàn)這一功能并非易事。事實上,研究人員努力了多年,解決了許多具有挑戰(zhàn)性的問題。最后,我們將問題分解為三個獨立的部分:識別多種語言,理解多種語言,以及為Google Assistant用戶優(yōu)化多語言識別。
識別多種語言
人類是有能力識別出別人在說另一種語言的,即使他們自己不會說這種語言,只需要注意語音的聲學(xué)特征(語調(diào)、音域等等)。但是,即使借助于全自動語音識別系統(tǒng),定義一個自動口語語言識別的計算框架也是很有挑戰(zhàn)性的。
研究者通常認(rèn)為,口語識別比基于文本的語言識別更具挑戰(zhàn)性,對于文本語言識別來說,相對簡單的基于字典的技術(shù)已經(jīng)可以做得很好。口語詞匯的時間/頻率模式很難比較,口語詞匯很難劃界,因為口語可以毫無停頓地以不同的節(jié)奏說話,而且麥克風(fēng)可能會記錄除了語音之外的背景噪音。
在2013年,谷歌開始使用深度神經(jīng)網(wǎng)絡(luò)開發(fā)口語識別(LangID)技術(shù)。今天,谷歌最先進(jìn)的LangID模型已經(jīng)可以使用遞歸神經(jīng)網(wǎng)絡(luò)區(qū)分超過2000種可供選擇的語言對。遞歸神經(jīng)網(wǎng)絡(luò)特別適用于序列建模問題,例如語音識別、語音檢測、說話人識別等。研究人員遇到的挑戰(zhàn)之一是使用更大的音頻集——獲取能夠自動理解多種語言的模型,并達(dá)到允許這些模型正常工作的質(zhì)量標(biāo)準(zhǔn)。
理解多種語言
要同時理解一種以上的語言,需要并行地運行多個進(jìn)程,每個進(jìn)程都會產(chǎn)生增量結(jié)果,這樣智能助理不僅可以識別查詢所使用的語言,還可以解析查詢以創(chuàng)建可操作的命令。
例如,即使是單語環(huán)境,如果用戶要求“設(shè)一個下午6點的鬧鈴”,谷歌助理必須理解“設(shè)置鬧鈴”意味著打開時鐘app,完成“6pm”的顯式參數(shù),并推斷鬧鐘應(yīng)該設(shè)在今天。為任何一對支持的語言實現(xiàn)這個功能都是一項挑戰(zhàn),因為智能助理需要執(zhí)行與單語環(huán)境時相同的工作,但現(xiàn)在還必須另外啟用LangID。這不僅是一個語言識別系統(tǒng),而是相當(dāng)于兩個單語言識別系統(tǒng)。
更重要的是,Google Assistan以及在用戶查詢中異步引用的其他服務(wù)會生成需要在幾毫秒內(nèi)評估的實時增量結(jié)果。這是借助另外一種算法實現(xiàn)的,該算法使用LangID生成的候選語言的概率、我們對轉(zhuǎn)錄的信心以及用戶的偏好(例如,最喜歡的藝術(shù)家)對兩個語音識別系統(tǒng)提供的轉(zhuǎn)錄假設(shè)進(jìn)行排序。
Google Assistant使用的多語言語音識別系統(tǒng)與標(biāo)準(zhǔn)單語語音識別系統(tǒng)的示意圖。排序算法用于從兩個單語語音識別器中選擇最佳的識別假設(shè),利用了用戶的相關(guān)信息和增量的langID結(jié)果。
當(dāng)用戶停止說話時,該模型不僅確定了用戶所講的語言,還確定了所講的內(nèi)容。當(dāng)然,這個過程需要一個復(fù)雜的架構(gòu),增加了處理成本,并可能造成不必要的延遲。
優(yōu)化多語識別模型
為了最大限度地減少這些不良影響,系統(tǒng)決定使用哪種語言的速度越快越好。如果系統(tǒng)在用戶完成查詢之前確定了所使用的語言,那么它將停止通過losing recognizer運行用戶的語音,并丟棄losing hypothesis,從而降低處理成本,減少任何潛在的延遲。
考慮到這一點,我們嘗試了優(yōu)化系統(tǒng)的幾種方法。
我們考慮的一個用例是,人們通常在一個完整查詢過程中使用相同的語言(這個語言通常也是用戶希望智能助理回復(fù)使用的語言),除了詢問某個東西用不同語言怎樣說之外。這意味著,在大多數(shù)情況下,關(guān)注查詢的開頭部分就可以讓智能助理對所使用的語言進(jìn)行初步猜測,甚至在包含不同語言實體的句子中也是如此。
有了這種早期識別,我們就可以像處理單語查詢那樣,通過切換到單語語音識別器來簡化任務(wù)。然而,快速決定如何以及何時切換到一個單語言,在最后會需要一個技術(shù)轉(zhuǎn)折:具體來說,我們使用隨機森林(random forest)方法,結(jié)合多個上下文信號,例如正在使用的設(shè)備類型、發(fā)現(xiàn)的語音假設(shè)的數(shù)量、多久收到類似的假設(shè)、各個語音識別器的不確定性、以及每種語言的使用頻率等。
另外一種簡化和改進(jìn)系統(tǒng)質(zhì)量的方法是限制用戶可以選擇的候選語言列表。用戶可以谷歌智能助理設(shè)備目前支持的六種語言中選擇兩種語言,這已經(jīng)能夠支持大多數(shù)多語使用者。
不過,隨著LangID技術(shù)的不斷改進(jìn),谷歌希望接下來能夠解決三語支持的問題,這將進(jìn)一步提升多語用戶群的體驗。而且,谷歌負(fù)責(zé)產(chǎn)品的副總裁 Nick Fox 此前表示,接下來的幾個月里 Google Assistant 將增加支持丹麥語、荷蘭語、印地語、印度尼西亞語、挪威語、瑞典語和泰語。到今年年底,谷歌助理將支持超過 30 種語言,覆蓋 Android 手機使用語言的 95%。
-
谷歌
+關(guān)注
關(guān)注
27文章
6225瀏覽量
107600 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4810瀏覽量
102888
原文標(biāo)題:谷歌雙語助理來了!中英夾雜也不怕,遞歸神經(jīng)網(wǎng)絡(luò)和隨機森林顯神威
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
智能收銀語音交互新標(biāo)桿—WT3000T8語音合成芯片TTS技術(shù)應(yīng)用解析

S1C31D50/51/41愛普生MCU系列語音芯片助力智能語音應(yīng)用
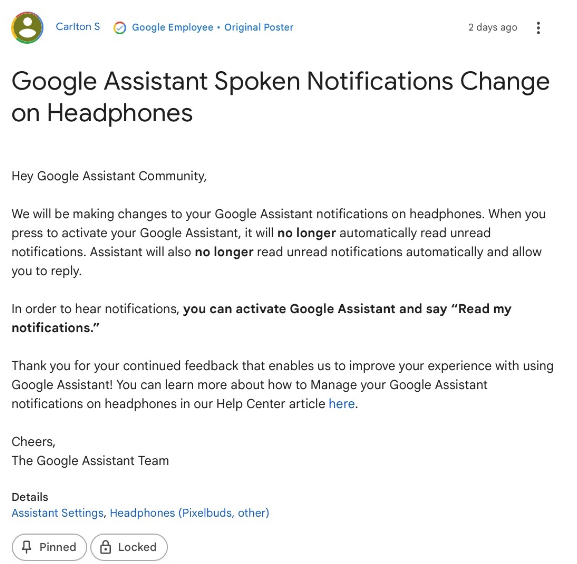
谷歌“減法”新動作:砍掉耳機按鍵喚醒朗讀功能
Meta與UNESCO合作推動多語言AI發(fā)展
微軟Copilot Voice升級,積極拓展多語言支持
Triton編譯器功能介紹 Triton編譯器使用教程
谷歌正式發(fā)布Gemini 2.0 性能提升近兩倍
Sora的功能優(yōu)勢及用戶評價
Llama 3 語言模型應(yīng)用
ChatGPT 的多語言支持特點
科大訊飛發(fā)布訊飛星火4.0 Turbo大模型及星火多語言大模型
谷歌全新推出開放式視覺語言模型PaliGemma
普羅格官網(wǎng)煥新,解鎖供應(yīng)鏈數(shù)智化無限可能

有效提升智能會議系統(tǒng)語音識別準(zhǔn)確性案例分享
有效提升智能會議系統(tǒng)語音識別準(zhǔn)確性案例分享






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論