") Dropout如何成為SDR的特殊情況
Dropout如何成為SDR的特殊情況
編者按:多層神經(jīng)網(wǎng)絡(luò)在多種基準任務(wù)上都有了顯著成果,例如文本、語音和圖像處理。盡管如此,這些深層神經(jīng)網(wǎng)絡(luò)會導(dǎo)致高維非線性的參數(shù)空間,讓搜索難以進行,并且還會導(dǎo)致過度擬合和較差的泛化。早期由于數(shù)據(jù)不足、無法恢復(fù)梯度損失以及不良局部最小值而引起的高捕捉概率,讓使用反向傳播的神經(jīng)網(wǎng)絡(luò)很容易失敗。
2006年,Hinton的深度學(xué)習提出了一些創(chuàng)新的方法以減少這些過度擬合和過度參數(shù)化的問題,包括減少連續(xù)梯度損失的ReLU和Dropout等。在這篇文章中,美國羅格斯大學(xué)的兩位研究者將關(guān)注深層網(wǎng)絡(luò)的過度參數(shù)化問題,盡管現(xiàn)在各項分類任務(wù)都有大量可用的數(shù)據(jù)。本文已提交到NIPS 2018,以下是論智對原文的大致編譯,如有錯誤請批評指正。
Dropout是用來減輕過度參數(shù)化、深度學(xué)習的過擬合以及避免偶然出現(xiàn)的不良局部最小值。具體說來,Dropout在每次更新時會添加一個帶有概率p的Bernoulli隨機變量、刪除隱藏的單元以及網(wǎng)絡(luò)中的連接,從而創(chuàng)造一個稀疏的網(wǎng)絡(luò)架構(gòu)。學(xué)習結(jié)束后,深度學(xué)習網(wǎng)絡(luò)會通過計算每個權(quán)重的期望值進行重組。大多數(shù)案例證明,深度學(xué)習的Dropout能將常見基準的錯誤減少50%以上。
在這篇論文中,我們將介紹一種通用的Dropout類型,它可以在權(quán)重層面操作,在每次更新中插入梯度相關(guān)的噪音,稱為隨機Delta規(guī)則(SDR)。SDR是在每個權(quán)重上執(zhí)行一個隨機變量,并對隨機變量中的每個參數(shù)提供更新之后的規(guī)則。雖然SDR在任意隨機變量下都能工作,但是我們將展示,Dropout在擁有二項式隨機變量中的固定參數(shù)下是非常特別的。最終我們在含有高斯SDR的標準基準下測試DenseNet,結(jié)果證明二項式Dropout有著非常大的優(yōu)勢。
隨機delta規(guī)則(SDR)
眾所周知,神經(jīng)傳輸會包含噪聲。如果皮質(zhì)分離的神經(jīng)元受到周期性、相同的刺激,將會產(chǎn)生不同的反應(yīng)。SDR的部分motivation是基于生命系統(tǒng)中信號在神經(jīng)元之間傳播的隨機性。顯然,平滑的神經(jīng)速率函數(shù)是基于很多刺激實驗得來的平均值,這使得我們認為兩個神經(jīng)元之間的突觸可以用一個具有固定參數(shù)的分布建模。
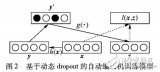
圖1顯示了我們用一個高斯隨機變量和平均μwij以及σwij實施的SDR算法。每個權(quán)重都會從高斯隨機變量中進行采樣。實際上,和Dropout一樣,很多網(wǎng)絡(luò)都是在訓(xùn)練時的更新中進行采樣。這里和Dropout的不同之處在于,SDR在更新時,會根據(jù)錯誤的梯度調(diào)整權(quán)重和隱藏單元。
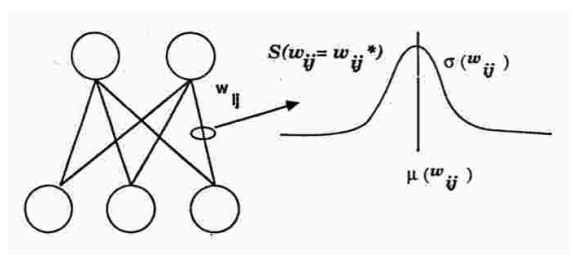
圖1
因此,每個權(quán)重梯度就是基于隱藏單元的隨機變量,基于此,系統(tǒng)可以:
給定相同的樣本/獎勵,生成多個回復(fù)假設(shè)
保持歷史預(yù)測,而不像Dropout一樣只有局部的隱藏單元權(quán)重
有可能會返回到不良局部最小值而造成貪婪搜索,但同時越來越遠離更好的局部最小值
最后一個優(yōu)點是,如Hinton所說,局部噪聲的插入可能會導(dǎo)致收斂到更好的局部最小值的速度更快、更穩(wěn)定。
實施SDR有三個更新規(guī)則,以下是權(quán)重分布中的權(quán)重值的更新規(guī)則:
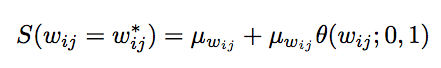
第一個更新規(guī)則用于計算權(quán)重分布的平均數(shù):
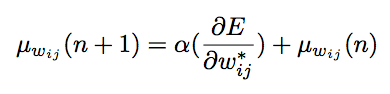
第二個用于權(quán)重分布的標準偏差:
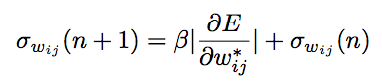
第三種是將標準偏差收斂到0,讓平均權(quán)重值達到一個固定點,將所有樣本都聚集起來:
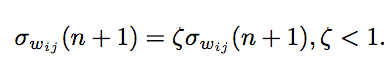
接下來,我們將講述Dropout如何成為SDR的特殊情況。最明顯的方法是首先將隨機搜索看作一種特殊的采樣分布。
將Dropout看作SDR的二項式固定參數(shù)
如之前所說,Dropout需要將每層的隱藏單元在Bernoulli過程中刪除。如果我們在同樣的網(wǎng)絡(luò)中,將Dropout和SDR進行對比,可以發(fā)現(xiàn)二者的不同在于隨機處理是否影響了權(quán)重或隱藏單元。圖2我們描述了Dropout在隱藏單元采樣時的收斂。可以看到明顯的不同是,SDR在適應(yīng)性地更新隨機變量參數(shù),而Dropout是用固定參數(shù)進和Binomial隨機變量進行采樣。另一個重要區(qū)別在于,SDR在隱藏層中的共享權(quán)重比Dropout的更“局部”。
圖2
那么,SDR所表現(xiàn)出的參數(shù)的增加,是否使得搜索更加有效、更加穩(wěn)定?下一步我們將開展實驗。
測試及結(jié)果
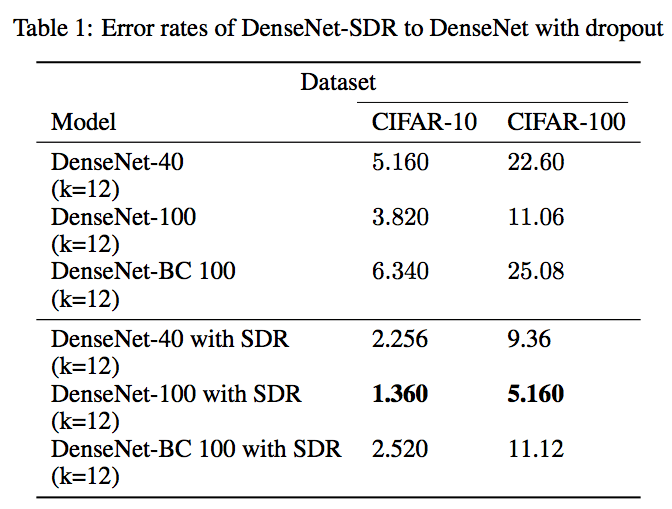
這里我們采用了在TensorFlow上搭建的經(jīng)過改進的DenseNet。模型用DenseNet-40、DenseNet-100和DenseNet-BC 100網(wǎng)絡(luò),它們經(jīng)過了CIFAR-10和CIFAR-100的訓(xùn)練,初始DenseNet參數(shù)相同。
最終的結(jié)果顯示,將SDR換成Dropout后的DenseNet測試中,錯誤率下降了50%以上。
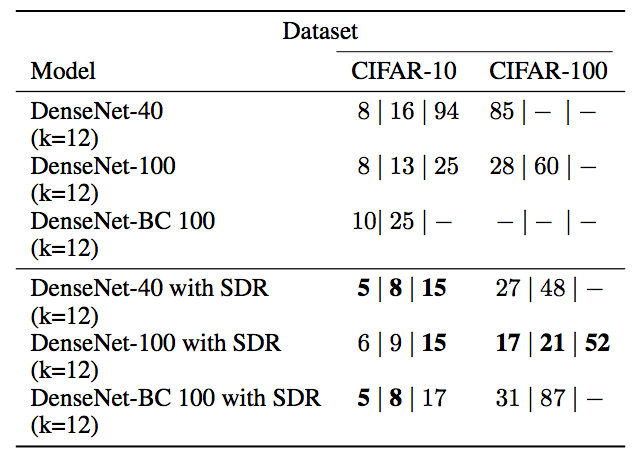
同時在錯誤率分別為15、10和5的情況下,訓(xùn)練所需次數(shù)也比單獨DenseNet減少:

訓(xùn)練精確度(DenseNet-100橙色,有SDR的DenseNet-100,藍色)
結(jié)語
這篇文章展示了一個基礎(chǔ)的深度學(xué)習算法(Dropout)是如何實施隨機搜索并幫助解決過度擬合的。未來我們將展示SDR是如何超越Dropout在深度學(xué)習分類中的表現(xiàn)的。
數(shù)據(jù)科學(xué)家、fast.ai創(chuàng)始人Jeremy Howard點評:“如果該論文結(jié)果真的這么好,那絕對值得關(guān)注。”
但是谷歌機器學(xué)習專家David Ha有不同意見:“結(jié)果看上去很可疑(我覺得他們搞錯了)。CIFAR-10的準確率能到98.64%,CIFAR-100真的能到94.84%嗎?”
-
神經(jīng)元
+關(guān)注
關(guān)注
1文章
368瀏覽量
18744 -
Dropout
+關(guān)注
關(guān)注
0文章
13瀏覽量
10166 -
深度學(xué)習
+關(guān)注
關(guān)注
73文章
5554瀏覽量
122446
原文標題:爭議 | 錯誤減少50%!這難道是更快更準確的深度學(xué)習?
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
SDR_SDR是什么意思


ref sdr sdram verilog代碼
SDR SDRAM Controller (White Pa
ref sdr sdram vhdl代碼
dropout正則化技術(shù)介紹
SDR的技術(shù)原理介紹及案例分析
基于動態(tài)dropout的改進堆疊自動編碼機方法
執(zhí)行節(jié)點分析時的特殊情況介紹






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論