") 如何改進(jìn)CPU性能發(fā)展瓶頸問題?
如何改進(jìn)CPU性能發(fā)展瓶頸問題?
通常一個(gè)處理器包含多個(gè)核心(Core),集成 Cache 子系統(tǒng),內(nèi)存子系統(tǒng)通過內(nèi)部或外部總線與其通信。在經(jīng)典CPU中一般有兩個(gè)常用的組件:北橋(North Bridge)和南橋(South Bridge)。它們是處理器和內(nèi)存以及其他外設(shè)溝通的渠道。圖1給出了處理器、內(nèi)存、南北橋以及其他總線之間的關(guān)系。

圖1
從圖一可以看到:
1)處理器訪問內(nèi)存需要通過北橋。
2)處理器訪問所有的外設(shè)都需要通過北橋。
3)掛在南橋的所有設(shè)備訪問內(nèi)存也需要通過北橋。
那么CPU訪問南橋上的外部設(shè)備和北橋上的DDR內(nèi)存的訪問速率受CPU的主頻、Local Bus帶寬、南橋外設(shè)總線的速率、CPU取指令機(jī)制等多方面所影響。
處理器主頻和集成度在過去二十年里一直按照摩爾定律在發(fā)展,從單核到多核以及超線程。處理器的性能提高不少,同時(shí)處理器的功耗也正比于主頻的三次方在增加。因?yàn)槭褂玫?a target="_blank">晶體管柵極材料存在漏電現(xiàn)象,高頻率下電子遷移顯著,勢(shì)必為導(dǎo)致產(chǎn)熱量增加,散熱帶了重大問題。CPU歡快的朝著頻率越來(lái)越高的方向發(fā)展,受到物理極限的挑戰(zhàn),又轉(zhuǎn)為核數(shù)越來(lái)越多的方向發(fā)展。由于所有CPU Core都是通過共享一個(gè)北橋來(lái)讀取內(nèi)存,隨著核數(shù)如何的發(fā)展,北橋在響應(yīng)時(shí)間上的性能瓶頸越來(lái)越明顯當(dāng)北橋出現(xiàn)擁塞時(shí),所有的設(shè)備和處理器都要癱瘓。這種系統(tǒng)設(shè)計(jì)的另外一個(gè)瓶頸體現(xiàn)在對(duì)內(nèi)存的訪問上。不管是處理器或者顯卡,還是南橋的硬盤、網(wǎng)卡或者光驅(qū),都需要頻繁訪問內(nèi)存,當(dāng)這些設(shè)備都爭(zhēng)相訪問內(nèi)存時(shí),增大了對(duì)北橋帶寬的競(jìng)爭(zhēng),而且北橋到內(nèi)存之間也只有一條總線。
為了改善對(duì)內(nèi)存的訪問瓶頸,出現(xiàn)了另外一種系統(tǒng)設(shè)計(jì),內(nèi)存控制器并沒有被集成在北橋中,而是被單獨(dú)隔離出來(lái)以協(xié)調(diào)北橋與某個(gè)相應(yīng)的內(nèi)存之間的交互。系統(tǒng)結(jié)構(gòu)如圖2所示。
圖 2 所示的這種架構(gòu)增加了內(nèi)存的訪問帶寬,緩解了不同設(shè)備對(duì)同一內(nèi)存訪問的擁塞問題,但是卻沒有改進(jìn)單一北橋芯片的瓶頸的問題。
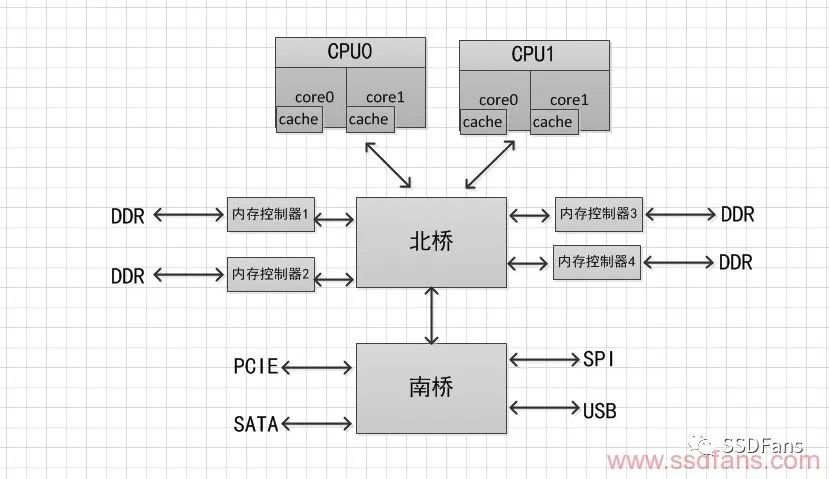
圖2
為了解決北橋北橋在響應(yīng)時(shí)間上的性能瓶頸,把內(nèi)存控制器(原本北橋中讀取內(nèi)存的部分)也做個(gè)拆分,平分到了每個(gè)CPU上。于是NUMA(Non-Uniform Memory Access)就出現(xiàn)了。內(nèi)存控制器集成到CPU內(nèi)部,Intel第二代酷睿I系列以及將主板北橋合并到CPU內(nèi)部,所以Intel第二代酷睿I系列沒有北橋,只有南橋。AMD沒有吞并北橋。順便補(bǔ)充一下Intel 單個(gè)socket只支持單個(gè)node,AMD 單個(gè)socket配對(duì)多個(gè)node。(Node,socket,core,thread)是NUMA中的概念,linux下查看cpu參數(shù)通過如下命令:
a)lscpu
圖3
圖3可以看出CPU是小端模式,每個(gè)CPU有一個(gè)core,每一個(gè)core有一個(gè)thread。三級(jí)cache大小,F(xiàn)lags查看支持的大頁(yè)內(nèi)存,比如pse 代表支持2MB的內(nèi)存頁(yè),pdpe1gb代表支持1G內(nèi)存頁(yè)。
b)cat /proc/cpuinfo
圖4
從圖4可以到Core ID、超線程數(shù)、Core的16進(jìn)制編碼(在DPDK應(yīng)用中會(huì)用到這些參數(shù))。
NUMA設(shè)計(jì)框架如圖5所示。紅色綠色箭頭代表訪問處理器本地內(nèi)存(Local memory),紅色箭頭訪問遠(yuǎn)程內(nèi)存(remote memory),即其他處理器的本地內(nèi)存,需要通過額外的總線!
NUMA中,雖然內(nèi)存直接attach在CPU上,但是由于內(nèi)存被平均分配在了各個(gè)die上。只有當(dāng)CPU訪問自身直接attach內(nèi)存對(duì)應(yīng)的物理地址時(shí),才會(huì)有較短的響應(yīng)時(shí)間(后稱Local Access)。而如果需要訪問其他CPU attach的內(nèi)存的數(shù)據(jù)時(shí),就需要通過inter-connect通道訪問,響應(yīng)時(shí)間就相比之前變慢了(后稱Remote Access)。所以NUMA(Non-Uniform Memory Access)就此得名。

圖5
從前面分析發(fā)現(xiàn),確實(shí)提高了CPU訪問內(nèi)存和外設(shè)的速率,奈何CPU處理速率遠(yuǎn)遠(yuǎn)超過了內(nèi)存的吞吐速率,這里就帶來(lái)了CPU不必要的開銷。一般來(lái)說(shuō),當(dāng)CPU從DDR中取指令時(shí),大概要花費(fèi)幾百個(gè)時(shí)鐘周期,在這幾百個(gè)時(shí)鐘周期內(nèi),處理器除了等待什么也不能做。在這種環(huán)境下,才提出了Cache的概念,其目的就是為了匹配處理器和內(nèi)存之間存在的巨大的速度鴻溝。
Cache 由三級(jí)組成,之所以對(duì)Cach 進(jìn)行分級(jí),也是從成本和生產(chǎn)工藝的角度考慮的。一級(jí)(L1)最快,但是容量最小,一級(jí)cache分為指令cache和數(shù)據(jù)cache,圖3中可以查看;三級(jí)(LLC, Last Level Cache)最慢,但是容量最大。當(dāng)CPU需要訪問某個(gè)地址時(shí)候,首先在cache中目錄表中查詢是否有該內(nèi)容,有就直接取指令或者數(shù)據(jù),沒有就從DDR中取取指令或者數(shù)據(jù)。在cache有對(duì)應(yīng)的數(shù)據(jù)簡(jiǎn)稱指令命中,反之指令沒有命中。L3 cache命中,大約需要40個(gè)時(shí)鐘周期,L3 cache沒命中,一個(gè)內(nèi)存讀需要140個(gè)時(shí)鐘周期。
Cache 的預(yù)取指令分為時(shí)間局部性和空間局部性。時(shí)間局部性是指程序即將用到的指令/數(shù)據(jù)可能就是目前正在使用的指令數(shù)據(jù)。因此,當(dāng)前用到的指令/數(shù)據(jù)在使用完畢之后以暫時(shí)存放在Cache中,可以在將來(lái)的時(shí)候再被處理器用到。空間局部性是指程序即將用到的指/數(shù)據(jù)可能與目前正在使用的指令/數(shù)據(jù)在空間上相鄰或者相近。因此,在處理器處理當(dāng)前指令/數(shù)據(jù)時(shí),可以從內(nèi)存中把相鄰區(qū)域的指令/數(shù)據(jù)讀取到Cache中,當(dāng)處理器需要處理相鄰內(nèi)存區(qū)域的指令/數(shù)據(jù)時(shí),可以直接從Cache中讀取,節(jié)省訪問內(nèi)存的時(shí)間。這里可以創(chuàng)建一個(gè)二維數(shù)組,然后順序橫向a[i][j]和豎向a[j][i]賦值計(jì)算時(shí)間做對(duì)比,由于a[j][i]地址是跳躍性的賦值,cache不能命中,所以消耗的時(shí)間遠(yuǎn)遠(yuǎn)大于連續(xù)地址的賦值。
提高CPU性能還可以采用多核并行計(jì)算,一個(gè)時(shí)鐘周期讀取N條指令。在軟件上也可以做適當(dāng)?shù)南到y(tǒng)優(yōu)化和算法優(yōu)化,比如配置CPU 親和性,CPU 親和性(Core affinity)就是一個(gè)特定的任務(wù)要在某個(gè)定的 CPU 上盡量長(zhǎng)時(shí)間地運(yùn)行而不被遷移到其他處理器上的傾向性。
-
處理器
+關(guān)注
關(guān)注
68文章
19785瀏覽量
233313 -
cpu
+關(guān)注
關(guān)注
68文章
11028瀏覽量
215811
原文標(biāo)題:CPU性能發(fā)展遇到的瓶頸
文章出處:【微信號(hào):SSDFans,微信公眾號(hào):SSDFans】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
處理器性能過剩?探秘CPU對(duì)SSD性能影響
通信系統(tǒng)關(guān)鍵的AD器件發(fā)展情況及瓶頸
LED產(chǎn)業(yè)發(fā)展面臨六大瓶頸
克服嵌入式CPU性能瓶頸
智能家居發(fā)展的瓶頸是什么?如何才能突破瓶頸?
我國(guó)物聯(lián)網(wǎng)的發(fā)展面臨什么瓶頸?
物聯(lián)網(wǎng)發(fā)展有什么瓶頸?
物聯(lián)網(wǎng)產(chǎn)業(yè)發(fā)展有什么瓶頸
運(yùn)用TMAM客觀分析程序運(yùn)行過程中內(nèi)在CPU資源出現(xiàn)的瓶頸
無(wú)線流媒體通信性能瓶頸的仿真研究
芯片開發(fā)商ARM宣布對(duì)CPU與GPU的一系列改進(jìn),性能大幅提升
突破性能瓶頸,實(shí)現(xiàn)CPU與內(nèi)存高性能互連
CPU單核性能與多核性能的區(qū)別
華為云 X 實(shí)例 CPU 性能測(cè)試詳解與優(yōu)化策略






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論