 第一種用于主動雙目立體成像系統的深度學習方法
第一種用于主動雙目立體成像系統的深度學習方法
本文是計算機視覺頂會ECCV 2018錄取論文中備受關注的一篇,來自谷歌&普林斯頓大學的研究人員提出了第一個主動雙目立體成像系統的深度學習解決方案,在諸多具有挑戰性的場景中展示出最先進的結果。
深度傳感器(Depth sensors)為許多難題提供了額外的3D信息,如非剛性重構(non-rigid reconstruction)、動作識別和參數跟蹤,從而給計算機視覺帶來了革新。雖然深度傳感器技術有許多類型,但它們都有明顯的局限性。例如,飛行時間系統(Time of flight systems)容易遭受運動偽影和多路徑的干擾,結構光(structured light )容易受到環境光照和多設備干擾。在沒有紋理的區域,需要昂貴的全局優化技術,特別是在傳統的非學習方法中, passive stereo很難實現。
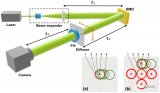
主動雙目立體視覺(Active stereo)提供了一種潛在的解決方案:使用一對紅外立體相機,使用一個偽隨機模式,通過圖案化的紅外光源對場景進行紋理化(如圖1所示)。通過合理選擇傳感波長,相機對捕獲主動照明和被動光線的組合,提高了結構光的質量,同時在室內和室外場景中提供了強大的解決方案。雖然這項技術幾十年前就提出了,但直到最近才出現在商業產品中。因此,從主動雙目立體圖像中推斷深度的先前工作相對較少,并且尚未獲得大規模的ground truth訓練數據。
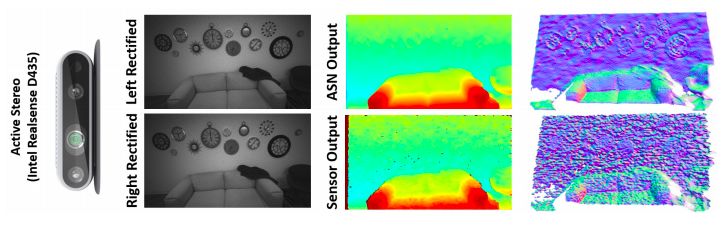
圖1:ActiveStereoNet (ASN)通過使用 Intel Realsense D D435相機獲得的一對經過修正的紅外圖像,產生平滑、詳細、無量化的結果。
在主動雙目立體成像系統中必須解決幾個問題。有些問題是所有的雙目系統問題共有的,例如,必須避免匹配被遮擋的像素,這會導致過度平滑、邊緣變厚和/或輪廓邊緣附近出現飛行像素。但是,其他一些問題是主動雙目系統特有的,例如,它必須處理非常高分辨率的圖像來匹配投影儀產生的高頻模式;它必須避免由于這些高頻模式的其他排列而產生的許多局部最小值;而且它還必須補償附近和遠處表面投影圖案之間的亮度差異。此外,它不能接受ground truth深度的大型主動雙目數據集的監督,因為沒有可用的數據。
在這篇論文中,我們介紹了ActiveStereoNet,這是主動雙目立體成像系統(active stereo systems)的第一個深度學習解決方案。由于缺乏ground truth,我們的方法是完全自我監督的,但它產生了精確的深度,子像素精度是像素的1/30;它沒有遭到常見的過度平滑問題,保留了邊緣,并且明確地處理了遮擋。
我們引入了一種新的重構誤差(reconstruction loss),它對噪聲和無紋理補丁(patches)更具穩健性,并且對光照的變化保持不變。我們提出的損失是通過基于窗口的成本聚合和自適應的支持權重方案優化的。這種成本聚合使邊緣保留并使損失函數平滑,這是使網絡達到引人注目的結果的關鍵。
最后,我們展示了預測無效區域(如遮擋)的任務是如何在沒有ground truth的情況下完成的,這對于減少模糊至關重要。我們對真實數據和合成數據進行了大量的定量和定性的評估,證明了該技術在許多具有挑戰性的場景中得到了state-of-the-art的結果。
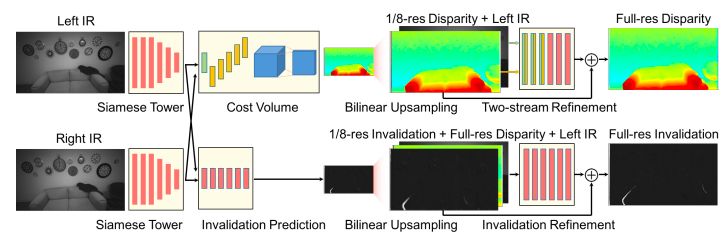
圖2:ActiveStereoNet的架構
ActiveStereoNet的架構如圖2所示。我們使用一個兩階段的網絡,其中一個低分辨率的成本體積被構建來推斷第一視差估計。一個雙線性上采樣后的殘差網絡用來預測最終視差圖。底部的Invalidation Network也被端到端地訓練來預測置信度圖。

圖3:光度損失(左)、LCN損失(中)和建議的加權LCN loss(右)的比較。
我們提出的loss對于遮擋更強健,它不依賴于像素的亮度,也不受低紋理區域的影響。
實驗和結果
我們進行了一系列實驗來評估ActiveStereoNet(ASN)。除了分析深度預測的準確性,并將其與以前的成果相比之外,我們還提供消融研究的結果,以研究擬損失的每個組成部分會對結果造成什么影響。在補充材料中,我們還評估了我們提出的self-supervised loss 方法在passive (RGB) stereo中的適用性,該方案表現出更高的泛化能力,在許多基準測試中達到了令人印象深刻的結果。
雙目立體匹配評估
在本節中,我們使用傳統的雙目立體匹配指標(如抖動和偏差),定性、定量地將我們的方法在實際數據的實驗中與最先進的立體算法進行比較。
抖動與偏差
假設某立體聲系統的基線標準為b,焦距為f,子像素視差精度為δ,則視差精度的深度誤差e與深度Z的平方成正比。由于視差誤差對深度的影響是可變的,一些簡單的評估度量(如視差的平均誤差)不能有效地反映估計深度的質量。而我們的方法首先標出深度估計的誤差,然后計算視差中的相應誤差。
為了評估ASN的子像素精度,我們記錄了相機在平坦的墻壁前記錄的100幀圖像,相機距離墻壁的范圍從500毫米到3500毫米不等,還有100幀,然后讓相機成50度角朝向墻壁,再記錄100幀,用來評估傾斜表面上的圖像。在本例中,我們將得到的結果與高魯棒性的平面擬合獲得的“ground truth”進行對比評估。
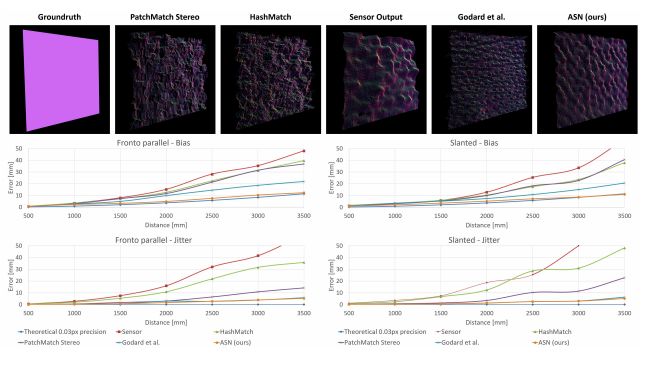
圖5.對最新技術的定量評估。
我們的方法的數據偏差降低了一個數量級,子像素精度為0.03像素,而且抖動非常低(參見文本)。我們還展示了距離墻壁3000毫米時,多種方案下預計出現的點云。請注意,盡管距離較遠(3米),但其他方法相比,我們的結果噪音更低。
為了表示精度,我們將偏差計算為預測深度和真實值之間的平均誤差l1。圖5所示為關于我們所用的方法的深度偏差和傳感器輸出、現有最佳技術的局部立體化方法(PatchMatch,HashMatch),以及我們所使用的最先進的非監督式訓練出的模型,并對點云做了表面法線著色處理的可視化操作。我們的系統在距墻壁全部距離上的性能都明顯優于其他方法,并且其誤差不會隨著深度增加而顯著增加。我們系統對應的子像素視差精度為1/30像素,這是通過使用上述方程(也在圖5中給出)擬合曲線而獲得的。這比其他方法的精度(不高于0.2像素)精確一個數量級。
為了表示噪聲,我們將抖動(Jitter)計算為深度誤差的標準偏差。圖5表明,與其他方法相比,我們的方法在幾乎每個深度上都能實現最低的抖動。
與現有最優技術的比較
在具有挑戰性的場景中對ASN的更多定性評估如圖6所示。可以看出,像PatchMatch和HashMatch這樣的局部方法無法處理有源光和無源光的混合照明場景,因此會產生不完整的差異圖像(缺失像素顯示為黑色)。使用半全局方案的傳感器輸出更適合此類數據,但仍然容易受到圖像噪聲的影響(請注意第四列中的噪聲結果)。相比之下,我們的方法可以產生完整的視差圖并保留清晰的邊界。

圖6.對現有最佳技術的定性評估。我們的方法可以生成詳細的視差圖。而目前最先進的方法會受到無紋理區域的影響。傳感器半全局方案的噪聲更大,輸出過于平滑。
關于真實序列的更多例子如圖8(右)所示,其中我們給出了由表面法線著色的點云。我們的輸出保留了所有細節,噪音很低。相比之下,我們使用自監督方法進行訓練的網絡產生了過度平滑的輸出。
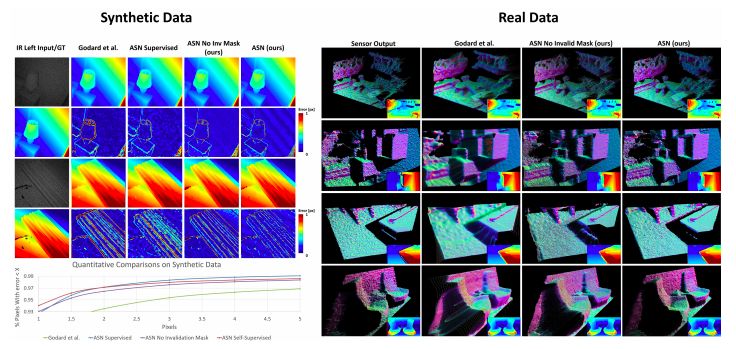
圖8:在合成數據和真實數據上的評估
我們的結果也不存在紋理復制問題,這很可能是因為我們使用成本量來明確地對匹配函數進行了建模,而不是直接從像素密度中學習。即使訓練數據主要是從辦公室環境中捕獲的,我們仍然發現,ASN很好地涵蓋了各種測試場景,如起居室、游戲室,餐廳和各式各樣的目標,比如人、沙發、植物、桌子等。具體如圖所示。
討論、局限性和未來方向
我們在本文中介紹了ActiveStereoNet(ASN),這是第一種用于主動雙目立體成像系統的深度學習方法。我們設計了一個新的損耗函數來處理高頻模式,照明效果和像素遮擋的情況,以解決自我監督設置中的主動立體聲問題。我們的方法能夠進行非常精確的重建,子像素精度達到0.03像素,比其他有源立體匹配方法精確一個數量級。與其他方法相比,ASN不會產生過于平滑的細節,可以生成完整的深度圖,保留有清晰的邊緣,沒有亂飛的像素。而失效網絡作為一個副產物,能夠得出可用于需要遮擋處理的高級應用的視差置信度圖。大量實驗顯示,使用NVidia Titan X顯卡和最先進的方法,用于不同具有挑戰性場景的處理任務,每幀運行平均時間為15ms。
局限性和未來方向
盡管我們的方法產生了令人信服的結果,但由于成本量的低分辨率,仍然存在透明對象和薄結構的問題。在未來的工作中,我們將提出解決方案來處理更高級任務的實施案例,比如語義分割。
-
成像系統
+關注
關注
2文章
203瀏覽量
14192 -
深度學習
+關注
關注
73文章
5554瀏覽量
122467
原文標題:ECCV18:谷歌普林斯頓提出首個端到端立體雙目系統深度學習方案
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
雙目立體視覺原理大揭秘(一)
雙目立體視覺的運用
雙目立體視覺在嵌入式中有何應用
一種隨機的人工神經網絡學習方法

一種模糊森林學習方法
一種基于塊對角化表示的多視角字典對學習方法
一文詳細剖析深度相機之雙目成像







 工商網監
工商網監
評論