") 機(jī)器學(xué)習(xí)實用指南——集成學(xué)習(xí)和隨機(jī)森林
機(jī)器學(xué)習(xí)實用指南——集成學(xué)習(xí)和隨機(jī)森林
梯度提升
另一個非常著名的提升算法是梯度提升。與 Adaboost 一樣,梯度提升也是通過向集成中逐步增加分類器運行的,每一個分類器都修正之前的分類結(jié)果。然而,它并不像 Adaboost 那樣每一次迭代都更改實例的權(quán)重,這個方法是去使用新的分類器去擬合前面分類器預(yù)測的殘差 。
讓我們通過一個使用決策樹當(dāng)做基分類器的簡單的回歸例子(回歸當(dāng)然也可以使用梯度提升)。這被叫做梯度提升回歸樹(GBRT,Gradient Tree Boosting 或者 Gradient Boosted Regression Trees)。首先我們用DecisionTreeRegressor去擬合訓(xùn)練集(例如一個有噪二次訓(xùn)練集):
>>>from sklearn.tree import DecisionTreeRegressor >>>tree_reg1 = DecisionTreeRegressor(max_depth=2) >>>tree_reg1.fit(X, y)
現(xiàn)在在第一個分類器的殘差上訓(xùn)練第二個分類器:
>>>y2 = y - tree_reg1.predict(X) >>>tree_reg2 = DecisionTreeRegressor(max_depth=2) >>>tree_reg2.fit(X, y2)
隨后在第二個分類器的殘差上訓(xùn)練第三個分類器:
>>>y3 = y2 - tree_reg1.predict(X) >>>tree_reg3 = DecisionTreeRegressor(max_depth=2) >>>tree_reg3.fit(X, y3)
現(xiàn)在我們有了一個包含三個回歸器的集成。它可以通過集成所有樹的預(yù)測來在一個新的實例上進(jìn)行預(yù)測。
>>>y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3))
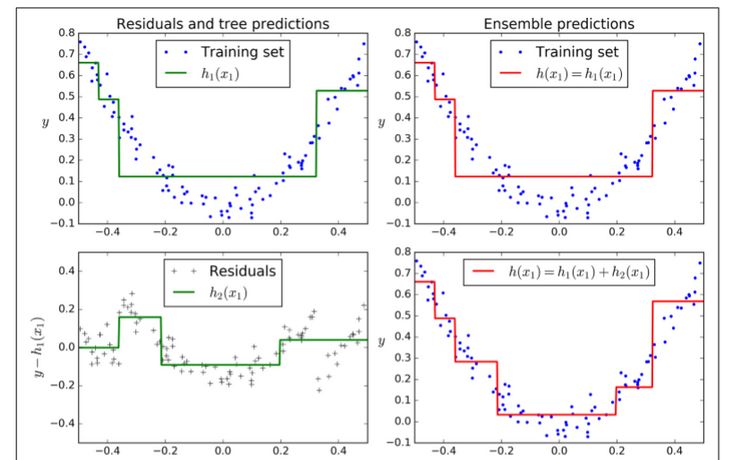
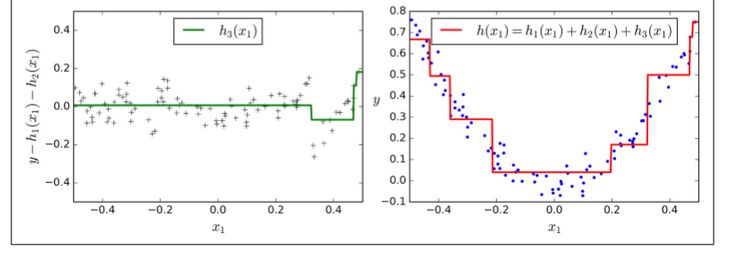
圖7-9在左欄展示了這三個樹的預(yù)測,在右欄展示了集成的預(yù)測。在第一行,集成只有一個樹,所以它與第一個樹的預(yù)測相似。在第二行,一個新的樹在第一個樹的殘差上進(jìn)行訓(xùn)練。在右邊欄可以看出集成的預(yù)測等于前兩個樹預(yù)測的和。相同的,在第三行另一個樹在第二個數(shù)的殘差上訓(xùn)練。你可以看到集成的預(yù)測會變的更好。
我們可以使用 sklean 中的GradientBoostingRegressor來訓(xùn)練 GBRT 集成。與RandomForestClassifier相似,它也有超參數(shù)去控制決策樹的生長(例如max_depth,min_samples_leaf等等),也有超參數(shù)去控制集成訓(xùn)練,例如基分類器的數(shù)量(n_estimators)。接下來的代碼創(chuàng)建了與之前相同的集成:
>>>from sklearn.ensemble import GradientBoostingRegressor>>>gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=3, learning_rate=1.0) >>>gbrt.fit(X, y)
超參數(shù)learning_rate 確立了每個樹的貢獻(xiàn)。如果你把它設(shè)置為一個很小的樹,例如 0.1,在集成中就需要更多的樹去擬合訓(xùn)練集,但預(yù)測通常會更好。這個正則化技術(shù)叫做 shrinkage。圖 7-10 展示了兩個在低學(xué)習(xí)率上訓(xùn)練的 GBRT 集成:其中左面是一個沒有足夠樹去擬合訓(xùn)練集的樹,右面是有過多的樹過擬合訓(xùn)練集的樹。

為了找到樹的最優(yōu)數(shù)量,你可以使用早停技術(shù)(第四章討論)。最簡單使用這個技術(shù)的方法就是使用staged_predict():它在訓(xùn)練的每個階段(用一棵樹,兩棵樹等)返回一個迭代器。加下來的代碼用 120 個樹訓(xùn)練了一個 GBRT 集成,然后在訓(xùn)練的每個階段驗證錯誤以找到樹的最佳數(shù)量,最后使用 GBRT 樹的最優(yōu)數(shù)量訓(xùn)練另一個集成:
>>>import numpy as np >>>from sklearn.model_selection import train_test_split>>>from sklearn.metrics import mean_squared_error>>>X_train, X_val, y_train, y_val = train_test_split(X, y)>>>gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=120) >>>gbrt.fit(X_train, y_train)>>>errors = [mean_squared_error(y_val, y_pred) for y_pred in gbrt.staged_predict(X_val)] >>>bst_n_estimators = np.argmin(errors)>>>gbrt_best = GradientBoostingRegressor(max_depth=2,n_estimators=bst_n_estimators) >>>gbrt_best.fit(X_train, y_train)
驗證錯誤在圖 7-11 的左面展示,最優(yōu)模型預(yù)測被展示在右面。

你也可以早早的停止訓(xùn)練來實現(xiàn)早停(與先在一大堆樹中訓(xùn)練,然后再回頭去找最優(yōu)數(shù)目相反)。你可以通過設(shè)置warm_start=True來實現(xiàn) ,這使得當(dāng)fit()方法被調(diào)用時 sklearn 保留現(xiàn)有樹,并允許增量訓(xùn)練。接下來的代碼在當(dāng)一行中的五次迭代驗證錯誤沒有改善時會停止訓(xùn)練:
>>>gbrt = GradientBoostingRegressor(max_depth=2, warm_start=True)min_val_error = float("inf") error_going_up = 0 for n_estimators in range(1, 120): gbrt.n_estimators = n_estimators gbrt.fit(X_train, y_train) y_pred = gbrt.predict(X_val) val_error = mean_squared_error(y_val, y_pred) if val_error < min_val_error: ? ? ? ? ? ? ? ?min_val_error = val_error ? ? ? ? ? ? ? ?error_going_up = 0 ? ? ? ?else: ? ? ? ? ? ? ? ?error_going_up += 1 ? ? ? ? ? ? ? ?if error_going_up == 5: ? ? ? ? ? ? ? ? ? ? ? ?break ?# early stopping
GradientBoostingRegressor也支持指定用于訓(xùn)練每棵樹的訓(xùn)練實例比例的超參數(shù)subsample。例如如果subsample=0.25,那么每個樹都會在 25% 隨機(jī)選擇的訓(xùn)練實例上訓(xùn)練。你現(xiàn)在也能猜出來,這也是個高偏差換低方差的作用。它同樣也加速了訓(xùn)練。這個技術(shù)叫做隨機(jī)梯度提升。
也可能對其他損失函數(shù)使用梯度提升。這是由損失超參數(shù)控制(見 sklearn 文檔)。
Stacking
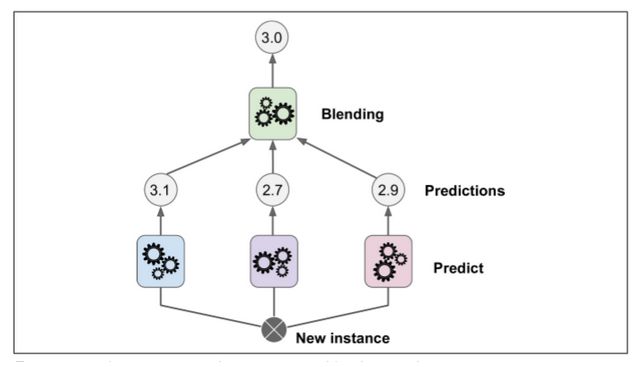
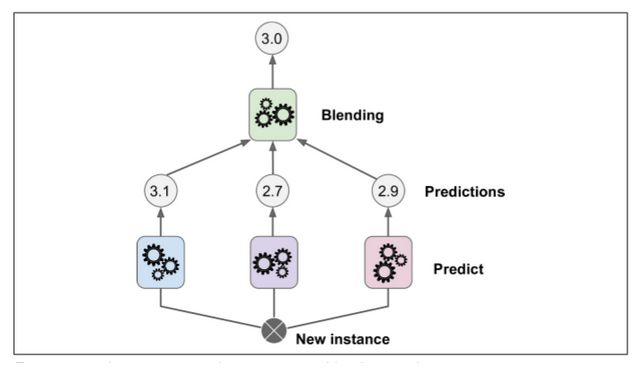
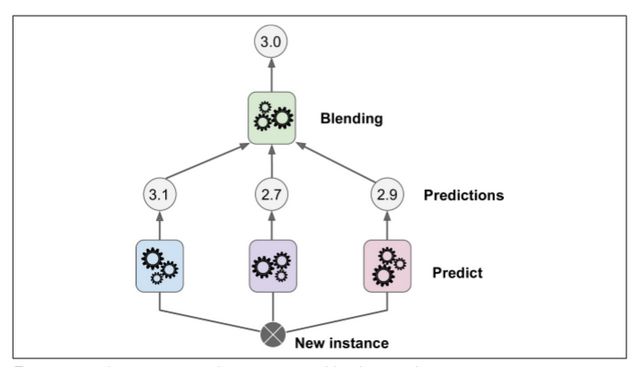
本章討論的最后一個集成方法叫做 Stacking(stacked generalization 的縮寫)。這個算法基于一個簡單的想法:不使用瑣碎的函數(shù)(如硬投票)來聚合集合中所有分類器的預(yù)測,我們?yōu)槭裁床挥?xùn)練一個模型來執(zhí)行這個聚合?圖 7-12 展示了這樣一個在新的回歸實例上預(yù)測的集成。底部三個分類器每一個都有不同的值(3.1,2.7 和 2.9),然后最后一個分類器(叫做 blender 或者 meta learner )把這三個分類器的結(jié)果當(dāng)做輸入然后做出最終決策(3.0)。
為了訓(xùn)練這個 blender ,一個通用的方法是采用保持集。讓我們看看它怎么工作。首先,訓(xùn)練集被分為兩個子集,第一個子集被用作訓(xùn)練第一層(詳見圖 7-13).
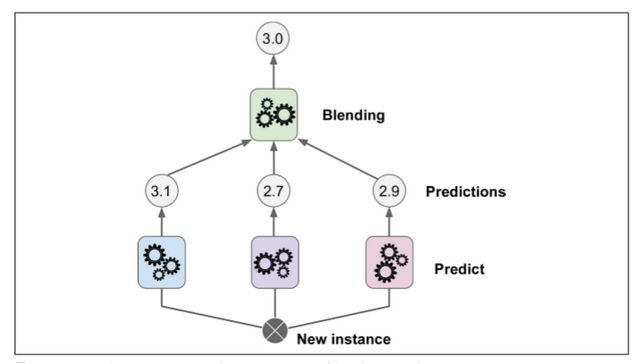
接下來,第一層的分類器被用來預(yù)測第二個子集(保持集)(詳見 7-14)。這確保了預(yù)測結(jié)果很“干凈”,因為這些分類器在訓(xùn)練的時候沒有使用過這些事例。現(xiàn)在對在保持集中的每一個實例都有三個預(yù)測值。我們現(xiàn)在可以使用這些預(yù)測結(jié)果作為輸入特征來創(chuàng)建一個新的訓(xùn)練集(這使得這個訓(xùn)練集是三維的),并且保持目標(biāo)數(shù)值不變。隨后 blender 在這個新的訓(xùn)練集上訓(xùn)練,因此,它學(xué)會了預(yù)測第一層預(yù)測的目標(biāo)值。
顯然我們可以用這種方法訓(xùn)練不同的 blender (例如一個線性回歸,另一個是隨機(jī)森林等等):我們得到了一層 blender 。訣竅是將訓(xùn)練集分成三個子集:第一個子集用來訓(xùn)練第一層,第二個子集用來創(chuàng)建訓(xùn)練第二層的訓(xùn)練集(使用第一層分類器的預(yù)測值),第三個子集被用來創(chuàng)建訓(xùn)練第三層的訓(xùn)練集(使用第二層分類器的預(yù)測值)。以上步驟做完了,我們可以通過逐個遍歷每個層來預(yù)測一個新的實例。詳見圖 7-15.
然而不幸的是,sklearn 并不直接支持 stacking ,但是你自己組建是很容易的(看接下來的練習(xí))。或者你也可以使用開源的項目例如 brew (網(wǎng)址為 https://github.com/viisar/brew)
練習(xí)
如果你在相同訓(xùn)練集上訓(xùn)練 5 個不同的模型,它們都有 95% 的準(zhǔn)確率,那么你是否可以通過組合這個模型來得到更好的結(jié)果?如果可以那怎么做呢?如果不可以請給出理由。
軟投票和硬投票分類器之間有什么區(qū)別?
是否有可能通過分配多個服務(wù)器來加速 bagging 集成系統(tǒng)的訓(xùn)練?pasting 集成,boosting 集成,隨機(jī)森林,或 stacking 集成怎么樣?
out-of-bag 評價的好處是什么?
是什么使 Extra-Tree 比規(guī)則隨機(jī)森林更隨機(jī)呢?這個額外的隨機(jī)有什么幫助呢?那這個 Extra-Tree 比規(guī)則隨機(jī)森林誰更快呢?
如果你的 Adaboost 模型欠擬合,那么你需要怎么調(diào)整超參數(shù)?
如果你的梯度提升過擬合,那么你應(yīng)該調(diào)高還是調(diào)低學(xué)習(xí)率呢?
導(dǎo)入 MNIST 數(shù)據(jù)(第三章中介紹),把它切分進(jìn)一個訓(xùn)練集,一個驗證集,和一個測試集(例如 40000 個實例進(jìn)行訓(xùn)練,10000 個進(jìn)行驗證,10000 個進(jìn)行測試)。然后訓(xùn)練多個分類器,例如一個隨機(jī)森林分類器,一個 Extra-Tree 分類器和一個 SVM。接下來,嘗試將它們組合成集成,使用軟或硬投票分類器來勝過驗證集上的所有集合。一旦找到了,就在測試集上實驗。與單個分類器相比,它的性能有多好?
從練習(xí) 8 中運行個體分類器來對驗證集進(jìn)行預(yù)測,并創(chuàng)建一個新的訓(xùn)練集并生成預(yù)測:每個訓(xùn)練實例是一個向量,包含來自所有分類器的圖像的預(yù)測集,目標(biāo)是圖像類別。祝賀你,你剛剛訓(xùn)練了一個 blender ,和分類器一起組成了一個疊加組合!現(xiàn)在讓我們來評估測試集上的集合。對于測試集中的每個圖像,用所有分類器進(jìn)行預(yù)測,然后將預(yù)測饋送到 blender 以獲得集合的預(yù)測。它與你早期訓(xùn)練過的投票分類器相比如何?
-
分類器
+關(guān)注
關(guān)注
0文章
152瀏覽量
13396 -
隨機(jī)森林
+關(guān)注
關(guān)注
1文章
22瀏覽量
4346
原文標(biāo)題:【翻譯】Sklearn 與 TensorFlow 機(jī)器學(xué)習(xí)實用指南 —— 第7章 集成學(xué)習(xí)和隨機(jī)森林 (下)
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
機(jī)器學(xué)習(xí)算法之隨機(jī)森林算法詳解及工作原理圖解
不可錯過 | 集成學(xué)習(xí)入門精講
集成學(xué)習(xí)和隨機(jī)森林,提供代碼實現(xiàn)
5分鐘內(nèi)看懂機(jī)器學(xué)習(xí)和深度學(xué)習(xí)的區(qū)別
機(jī)器學(xué)習(xí)的隨機(jī)森林算法簡介
淺談機(jī)器學(xué)習(xí)技術(shù)中的隨機(jī)森林算法
10大常用機(jī)器學(xué)習(xí)算法匯總
一種基于數(shù)據(jù)集成的隨機(jī)森林算法

隨機(jī)森林的概念、工作原理及用例
利用隨機(jī)森林進(jìn)行特征重要性評估
使用機(jī)器學(xué)習(xí)的森林動物計數(shù)器

基于Python實現(xiàn)隨機(jī)森林算法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論