") 強化學(xué)習(xí)的經(jīng)典基礎(chǔ)性缺陷可能限制它解決很多復(fù)雜問題
強化學(xué)習(xí)的經(jīng)典基礎(chǔ)性缺陷可能限制它解決很多復(fù)雜問題
在上一篇文章里,我們提到了棋盤游戲的比喻和純強化學(xué)習(xí)技術(shù)的缺陷(斯坦福學(xué)者冷思考:強化學(xué)習(xí)存在基礎(chǔ)性缺陷)。在這一部分中,我們會列舉一些添加先驗知識的方法,同時會對深度學(xué)習(xí)進行介紹,并且展示對最近的成果進行調(diào)查。
那么,為什么不跳出純強化學(xué)習(xí)的圈子呢?
你可能會想:
我們不能越過純強化學(xué)習(xí)來模仿人類的學(xué)習(xí)——純強化學(xué)習(xí)是嚴(yán)格制定的方法,我們用來訓(xùn)練AI智能體的算法是基于此的。盡管從零開始學(xué)習(xí)不如多提供些信息,但是我們沒有那樣做。
的確,加入先驗知識或任務(wù)指導(dǎo)會比嚴(yán)格意義上的純強化學(xué)習(xí)更復(fù)雜,但是事實上,我們有一種方法既能保證從零開始學(xué)習(xí),又能更接近人類學(xué)習(xí)的方法。
首先,我們先明確地解釋,人類學(xué)習(xí)和純強化學(xué)習(xí)有什么區(qū)別。當(dāng)開始學(xué)習(xí)一種新技能,我們主要做兩件事:猜想大概的操作方法是什么,或者度說明書。一開始,我們就了解了這一技能要達(dá)到的目標(biāo)和大致使用方法,并且從未從低端的獎勵信號開始反向生成這些東西。
UC Berkeley的研究者最近發(fā)現(xiàn),人類的學(xué)習(xí)速度比純強化學(xué)習(xí)在某些時候更快,因為人類用了先驗知識
使用先驗知識和說明書
這種想法在AI研究中有類似的成果:
解決“學(xué)習(xí)如何學(xué)習(xí)”的元學(xué)習(xí)方法:讓強化學(xué)習(xí)智能體更快速地學(xué)會一種新技術(shù)已經(jīng)有類似的技巧了,而學(xué)習(xí)如何學(xué)習(xí)正是我們需要利用先驗知識超越純強化學(xué)習(xí)的方法。
MAML是先進的元學(xué)習(xí)算法。智能體可以在元學(xué)習(xí)少次迭代后學(xué)會向前和向后跑動
遷移學(xué)習(xí):顧名思義,就是將在一種問題上學(xué)到的方法應(yīng)用到另一種潛在問題上。關(guān)于遷移學(xué)習(xí),DeepMind的CEO是這樣說的。
我認(rèn)為(遷移學(xué)習(xí))是強人工智能的關(guān)鍵,而人類可以熟練地使用這種技能。例如,我現(xiàn)在已經(jīng)玩過很多棋盤類游戲了,如果有人再教我另一種棋類游戲,我可能不會那么陌生,我會把在其他游戲上學(xué)到的啟發(fā)性方法用到這一游戲上,但是現(xiàn)在機器還做不到……所以我想這是強人工智能所面臨的重大挑戰(zhàn)。
零次學(xué)習(xí)(Zero-shot learning):它的目的也是掌握新技能,但是卻不用新技能進行任何嘗試,智能體只需從新任務(wù)接收“指令”,即使沒有執(zhí)行過新的任務(wù)也能一次性表現(xiàn)的很好。
一次學(xué)習(xí)(one-shot learning)和少次學(xué)習(xí)(few-shot learning):這兩類是研究的熱門區(qū)域,他們和零次學(xué)習(xí)不同,因為它們會用到即將學(xué)習(xí)的技巧做示范,或者只需要少量迭代。
終身學(xué)習(xí)(life long learning)和自監(jiān)督學(xué)習(xí)(self supervised learning):也就是長時間不在人類的指導(dǎo)下學(xué)習(xí)。
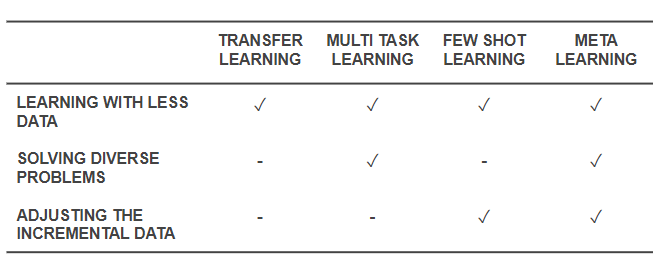
這些都是除了從零學(xué)習(xí)之外的強化學(xué)習(xí)方法。特別是元學(xué)習(xí)和零次學(xué)習(xí)體現(xiàn)了人在學(xué)習(xí)一種新技能時更有可能的做法,與純強化學(xué)習(xí)有差別。一個元學(xué)習(xí)智能體會利用先驗知識快速學(xué)習(xí)棋類游戲,盡管它不明白游戲規(guī)則。另一方面,一個零次學(xué)習(xí)智能體會詢問游戲規(guī)則,但是不會做任何學(xué)習(xí)上的嘗試。一次學(xué)習(xí)和少次學(xué)習(xí)方法相似,但是只知道如何運用技能,也就是說智能體會觀察其他人如何玩游戲,但不會要求解釋游戲規(guī)則。
最近一種混合了一次學(xué)習(xí)和元學(xué)習(xí)的方法。來自O(shè)ne-Shot Imitation from Observing Humans via Domain-Adaptive Meta-Learning
元學(xué)習(xí)和零次學(xué)習(xí)(或少次學(xué)習(xí))的一般概念正是棋類游戲中合理的部分,然而更好的是,將零次學(xué)習(xí)(或少次學(xué)習(xí))和元學(xué)習(xí)結(jié)合起來就更接近人類學(xué)習(xí)的方法了。它們利用先驗經(jīng)驗、說明指導(dǎo)和試錯形成最初對技能的假設(shè)。之后,智能體親自嘗試了這一技巧并且依靠獎勵信號進行測試和微調(diào),從而做出比最初假設(shè)更優(yōu)秀的技能。
這也解釋了為什么純強化學(xué)習(xí)方法目前仍是主流,針對元學(xué)習(xí)和零次學(xué)習(xí)的研究不太受關(guān)注。有一部分原因可能是因為強化學(xué)習(xí)的基礎(chǔ)概念并未經(jīng)受過多質(zhì)疑,元學(xué)習(xí)和零次學(xué)習(xí)的概念也并沒有大規(guī)模應(yīng)用到基礎(chǔ)原理的實現(xiàn)中。在所有運用了強化學(xué)習(xí)的代替方法的研究中,也許最符合我們希望的就是DeepMind于2015年提出的Universal Value Function Approximators,其中Richard Sutton提出了“通用價值函數(shù)(general value function)”。這篇論文的摘要是這樣寫的:
價值函數(shù)是強化學(xué)習(xí)系統(tǒng)中的核心要素。主要思想就是建立一個單一函數(shù)近似器V(s;θ),通過參數(shù)θ來估計任意狀態(tài)s的長期獎勵。在這篇論文中,我們提出了通用價值函數(shù)近似器(UVFAs)V(s, g;θ),不僅能生成狀態(tài)s的獎勵值,還能生成目標(biāo)g的獎勵值。
將UVFA應(yīng)用到實際中
這種嚴(yán)格的數(shù)學(xué)方法將目標(biāo)看作是基礎(chǔ)的、必須的輸入。智能體被告知應(yīng)該做什么,就像在零次學(xué)習(xí)和人類學(xué)習(xí)中一樣。
現(xiàn)在距論文發(fā)表已經(jīng)三年,但只有極少數(shù)人對論文的結(jié)果表示欣喜(作者統(tǒng)計了下只有72人)。據(jù)谷歌學(xué)術(shù)的數(shù)據(jù),DeepMind同年發(fā)表的Human-level control through deep RL一文已經(jīng)有了2906次引用;2016年發(fā)表的Mastering the game of Go with deep neural networks and tree search已經(jīng)獲得了2882次引用。
所以,的確有研究者朝著結(jié)合元學(xué)習(xí)和零次學(xué)習(xí)的方向努力,但是根據(jù)引用次數(shù),這一方向仍然不清楚。關(guān)鍵問題是:為什么人們不把這種結(jié)合的方法看作是默認(rèn)方法呢?
答案很明顯,因為太難了。AI研究傾向于解決獨立的、定義明確的問題,以更好地做出進步,所以除了純強化學(xué)習(xí)以及從零學(xué)習(xí)之外,很少有研究能做到,因為它們難以定義。但是,這一答案似乎還不夠令人滿意:深度學(xué)習(xí)讓研究人員創(chuàng)造了混合方法,例如包含NLP和CV兩種任務(wù)的模型,或者原始AlphaGo加入了深度學(xué)習(xí)等等。事實上,DeepMind最近的論文Relational inductive biases, deep learning, and graph networks也提到了這一點:
我們認(rèn)為,通向強人工智能的關(guān)鍵方法就是將結(jié)合生成作為第一要義,我們支持運用多種方法達(dá)到目標(biāo)。生物學(xué)也并不是單純的自然和后期培養(yǎng)相對立,它是將二者結(jié)合,創(chuàng)造了更有效的結(jié)果。我們也認(rèn)為,架構(gòu)和靈活性之間并非對立的,而是互補的。通過最近的一些基于結(jié)構(gòu)的方法和深度學(xué)習(xí)混合的案例,我們看到了結(jié)合技術(shù)的巨大前景。
最近元學(xué)習(xí)(或零次學(xué)習(xí))的成果
現(xiàn)在我們可以得出結(jié)論:
受上篇棋盤游戲比喻的激勵,以及DeepMind通用價值函數(shù)的提出,我們應(yīng)該重新考慮強化學(xué)習(xí)的基礎(chǔ),或者至少更加關(guān)注這一領(lǐng)域。
雖然現(xiàn)有成果并未流行,但我們?nèi)阅馨l(fā)現(xiàn)一些令人激動的成果:
Hindsight Experience Replay
Zero-shot Task Generalization with Multi-Task Deep Reinforcement Learning
Representation Learning for Grounded Spatial Reasoning
Deep Transfer in Reinforcement Learning by Language Grounding
Cross-Domain Perceptual Reward Functions
Learning Goal-Directed Behaviour
上述論文都是結(jié)合了各種方法、或者以目標(biāo)為導(dǎo)向的方法。而更令人激動的是最近有一些作品研究了本能激勵和好奇心驅(qū)使的學(xué)習(xí)方法:
Kickstarting Deep Reinforcement Learning
Surprise-Based Intrinsic Motivation for Deep Reinforcement Learning
Meta-Reinforcement Learning of Structured Exploration Strategies
Learning Robust Rewards with Adversarial Inverse Reinforcement Learning
Curiosity-driven Exploration by Self-supervised Prediction
Learning by Playing - Solving Sparse Reward Tasks from Scratch
Learning to Play with Intrinsically-Motivated Self-Aware Agents
Unsupervised Predictive Memory in a Goal-Directed Agent
World Models
接著,我們還可以從人類的學(xué)習(xí)中獲得靈感,也就是直接學(xué)習(xí)。事實上,過去和現(xiàn)在的神經(jīng)科學(xué)研究直接表明,人類和動物的學(xué)習(xí)可以用強化學(xué)習(xí)和元學(xué)習(xí)共同表示。
Meta-Learning in Reinforcement Learning
Prefrontal cortex as a meta-reinforcement learning system
最后一篇論文的結(jié)果和我們的結(jié)論相同,論智此前曾報道過這篇:DeepMind論文:多巴胺不只負(fù)責(zé)快樂,還能幫助強化學(xué)習(xí)。從根本上講,人們可以認(rèn)為,人類的智慧正是強化學(xué)習(xí)和元學(xué)習(xí)的結(jié)合——元強化學(xué)習(xí)的成果。如果真的是這種情況,我們是否也該對AI做同樣的事呢?
結(jié)語
強化學(xué)習(xí)的經(jīng)典基礎(chǔ)性缺陷可能限制它解決很多復(fù)雜問題,像本文提到的很多論文中都提到,不采用從零學(xué)習(xí)的方法也不是必須有手工編寫或者嚴(yán)格的規(guī)則。元強化學(xué)習(xí)讓智能體通過高水平的指導(dǎo)、經(jīng)驗、案例更好地學(xué)習(xí)。
目前的時機已經(jīng)成熟到可以展開上述工作,將注意力從純強化學(xué)習(xí)的身上移開,多多關(guān)注從人類身上學(xué)到的學(xué)習(xí)方法。但是針對純強化學(xué)習(xí)的工作不應(yīng)該立即停止,而是應(yīng)該作為其他工作的補充。基于元學(xué)習(xí)、零次學(xué)習(xí)、少次學(xué)習(xí)、遷移學(xué)習(xí)及它們的結(jié)合的方法應(yīng)該成為默認(rèn)方法,我很愿意為此貢獻(xiàn)自己的力量。
-
智能體
+關(guān)注
關(guān)注
1文章
262瀏覽量
10951 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5554瀏覽量
122467 -
強化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
269瀏覽量
11514
原文標(biāo)題:面對強化學(xué)習(xí)的基礎(chǔ)性缺陷,研究重點也許要轉(zhuǎn)變
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
什么是深度強化學(xué)習(xí)?深度強化學(xué)習(xí)算法應(yīng)用分析

深度強化學(xué)習(xí)實戰(zhàn)
將深度學(xué)習(xí)和強化學(xué)習(xí)相結(jié)合的深度強化學(xué)習(xí)DRL
如何深度強化學(xué)習(xí) 人工智能和深度學(xué)習(xí)的進階
人工智能機器學(xué)習(xí)之強化學(xué)習(xí)
什么是強化學(xué)習(xí)?純強化學(xué)習(xí)有意義嗎?強化學(xué)習(xí)有什么的致命缺陷?

基于強化學(xué)習(xí)的MADDPG算法原理及實現(xiàn)
深度強化學(xué)習(xí)到底是什么?它的工作原理是怎么樣的
復(fù)雜應(yīng)用中運用人工智能核心 強化學(xué)習(xí)
一文詳談機器學(xué)習(xí)的強化學(xué)習(xí)
DeepMind發(fā)布強化學(xué)習(xí)庫RLax
《自動化學(xué)報》—多Agent深度強化學(xué)習(xí)綜述

什么是強化學(xué)習(xí)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論