") Excel本身就能編寫大量基礎(chǔ)機(jī)器學(xué)習(xí)算法
Excel本身就能編寫大量基礎(chǔ)機(jī)器學(xué)習(xí)算法
編者按:當(dāng)初學(xué)者第一次接觸機(jī)器算法時,直觀了解算法正在做什么是一項(xiàng)非常重要的任務(wù),這也是論智一直推崇可視化方法的原因之一。雖然初級算法的數(shù)學(xué)計(jì)算并不難掌握,但當(dāng)他們一看到滿篇的數(shù)學(xué)理論和符號,學(xué)習(xí)下去的興致和氣勢就消減了不少。
作為一名數(shù)據(jù)工作者,這年頭“熟悉機(jī)器學(xué)習(xí)算法”遠(yuǎn)比“精通Excel”在求職市場上要搶手得多,但前者的“熟悉”究竟是熟悉到什么程度呢?Excel本身就能編寫大量基礎(chǔ)機(jī)器學(xué)習(xí)算法,而且對于初學(xué)者來說,這樣的編寫過程不僅能加深對算法的理解,還能幫助他們更充分地感受算法的美妙。
下面我們用一個例子來證明這一點(diǎn)。
從本質(zhì)上來說,大多數(shù)數(shù)據(jù)科學(xué)算法其實(shí)就是優(yōu)化問題,而其中最常用的算法之一就是梯度下降算法。對于初學(xué)者來說,梯度下降這個詞可能乍一聽有些可怕,但它真的這么復(fù)雜嗎?
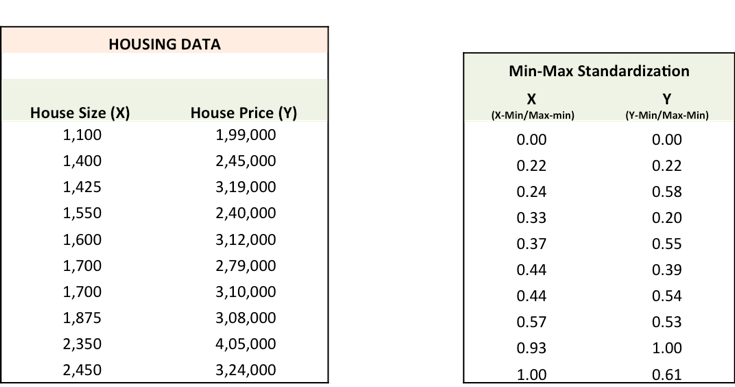
以下是一個房價預(yù)測任務(wù):根據(jù)歷史房價數(shù)據(jù)創(chuàng)建一個模型,結(jié)合房屋面積預(yù)測新房價格。讓我們先用已有數(shù)據(jù)建立一個表格:

如上表所示,房屋面積是X,房價是Y,由此我們可以繪制歷史房價數(shù)據(jù)折線圖:
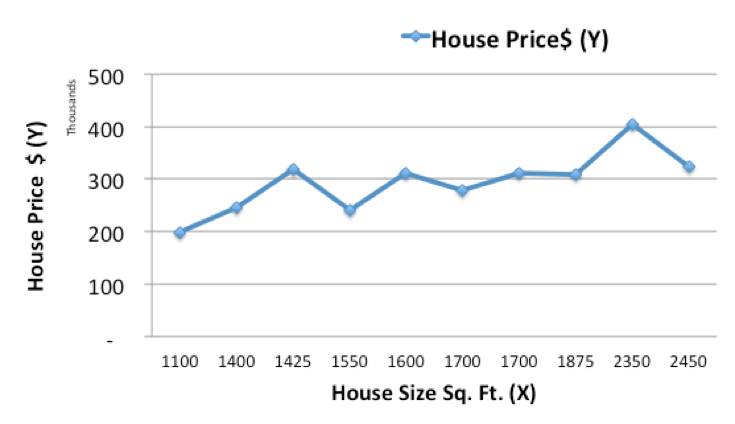
現(xiàn)在用一個簡單的線性模型,對歷史數(shù)據(jù)進(jìn)行擬合,根據(jù)房屋面積X預(yù)測新房價格Y(pre):
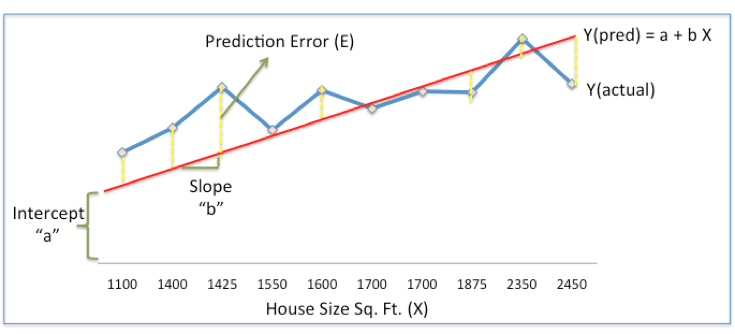
在上圖中,紅線是我們的線性模型,因此鑒于橫坐標(biāo)和縱坐標(biāo)信息,它的表達(dá)式是:Y(pred) = a + bX。
藍(lán)線是已知的歷史房價,從分布上簡單給出了房價和房屋面積相關(guān)程度的基本信息。
連接紅線和藍(lán)線的黃色虛線表示對于同一面積的房屋,模型預(yù)測和實(shí)際房價的誤差(E)。
所以我們的目標(biāo)是找到最好的a和b,使誤差項(xiàng)E最小:
殘差平方和(SSE)= ?(真實(shí)房價-預(yù)測房價)2= ?(Y - Ypred)2
(SSE只是一種方法,還可以用其他方法統(tǒng)計(jì)誤差)
好了,下面我們就要用到梯度下降了。梯度下降是一種優(yōu)化算法,它能幫我們找到優(yōu)化權(quán)重(a,b),并保證模型預(yù)測的準(zhǔn)確率。下面是具體步驟:
步驟1:用隨機(jī)值初始化權(quán)重a和b,并計(jì)算誤差(SSE)。
步驟2:計(jì)算梯度,即當(dāng)權(quán)重從初始隨機(jī)值逐漸變小時SSE的變化。這有助于我們把a(bǔ)和b朝SSE最小的方向優(yōu)化。
步驟3:用梯度調(diào)整權(quán)重以使SSE最小化,以達(dá)到最佳值。
步驟4:用新權(quán)重進(jìn)行預(yù)測,并計(jì)算新的SSE。
步驟5:重復(fù)步驟2和3,直到再次調(diào)整權(quán)重后不再明顯降低預(yù)測錯誤率。
如果說這樣描述有些泛泛而談,下面我們就結(jié)合圖表詳細(xì)介紹。請牢記一點(diǎn),事先把數(shù)據(jù)處理好有助于更高效的優(yōu)化。
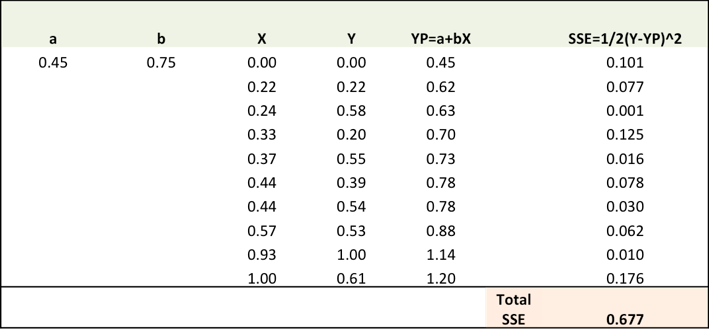
第一步: 為了擬合Y(pred) = a + bX,用隨機(jī)值初始化a和b,并計(jì)算預(yù)測誤差(SSE)。
第二步:計(jì)算權(quán)重的誤差梯度。
?SSE/?a =-(Y-Ypred)
?SSE/?b =-(Y-Ypred)X
其中,SSE=? (Y-Ypred)2= ?(Y-(a+bX))2
雖然有一點(diǎn)點(diǎn)讓人煩惱的微積分計(jì)算,但這已經(jīng)很基礎(chǔ)了,?SSE/?a和?SSE/?b是我們想要的梯度,它們給出了SSE“下降”的方向。
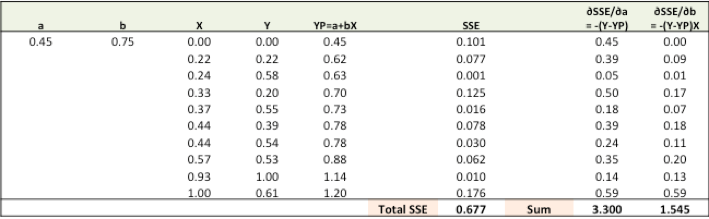
第三步:用梯度調(diào)整權(quán)重,使SSE獲得最小值,也就是最佳值。
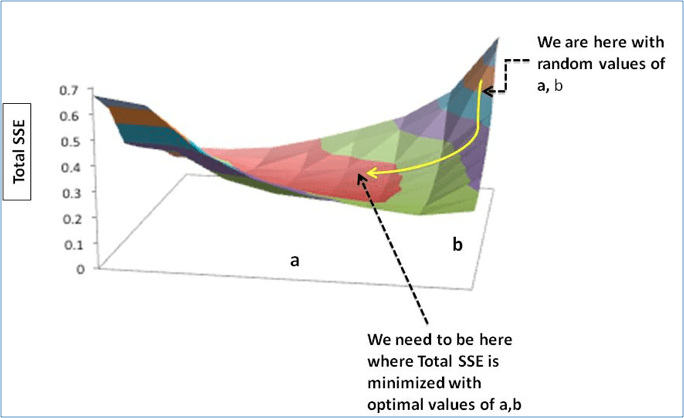
這之后我們就能用新權(quán)重更新a和b的值,以便模型沿著最優(yōu)方向移動。
因?yàn)?/p>
a-?SSE/?a
b-?SSE/?b
所以更新規(guī)則就是:
新的a = a - r × ?SSE/?a = 0.45–0.01× 3.300 = 0.42
新的b = b - r × ?SSE/?b = 0.75–0.01×1.545 = 0.73
其中r=0.01是學(xué)習(xí)率,表示權(quán)重調(diào)整的步幅。
第四步:用新的a和b進(jìn)行預(yù)測并計(jì)算新的SSE。
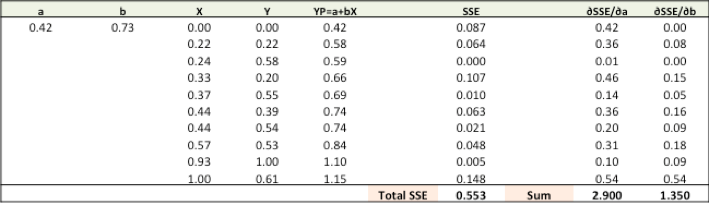
可以看到,SSE已經(jīng)從0.677下降到0.553了,這意味著模型的預(yù)測準(zhǔn)確率有所提高。
第五步:重復(fù)第二步和第三步,直到再改變a和b,SSE不再發(fā)生明顯變化。
以上就是用Excel實(shí)現(xiàn)的梯度下降算法,比起一堆數(shù)學(xué)計(jì)算,這樣圖文并茂的演示是不是更有趣呢?
在MOOC課程中,除了吳恩達(dá)的deeplearning.ai和Udacity,李飛飛強(qiáng)烈推薦的Fast.ai也有其獨(dú)到之處。這家公司的CEO Jeremy Howard是深度學(xué)習(xí)領(lǐng)域的一朵奇葩,他沒有過硬的學(xué)術(shù)背景,也沒有大型科技公司的就職經(jīng)歷,僅憑自學(xué)就在kaggle競賽中鋒芒畢露。對于這樣一個人,他的課絕對值得初學(xué)者學(xué)習(xí)。
-
Excel
+關(guān)注
關(guān)注
4文章
225瀏覽量
56357 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8490瀏覽量
134043
原文標(biāo)題:最強(qiáng)神器!用Excel實(shí)踐機(jī)器學(xué)習(xí)算法
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
美光和思科在SEMICON West 2017:實(shí)現(xiàn)機(jī)器學(xué)習(xí)的前提是讓機(jī)器使用大量數(shù)據(jù)創(chuàng)建算法
機(jī)器學(xué)習(xí)的算法應(yīng)用
什么是機(jī)器學(xué)習(xí)? 機(jī)器學(xué)習(xí)基礎(chǔ)入門
Spark機(jī)器學(xué)習(xí)庫的各種機(jī)器學(xué)習(xí)算法
通過Python就能讀懂機(jī)器學(xué)習(xí)
機(jī)器學(xué)習(xí)的范圍和算法
詳談機(jī)器學(xué)習(xí)模型算法的質(zhì)量保障方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論